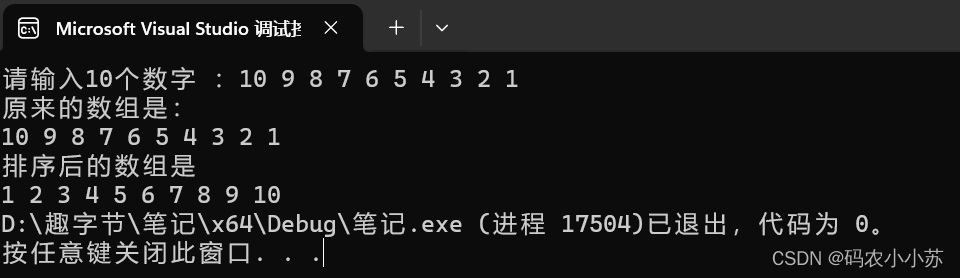
最近我把《代码审计 C/C++实践》一书中关于描述SCA工具的技术点之一——多维代码特征提取技术重新阅读了一下,理解一下多维代码特征提取技术以及在SCA工具中的运用。
SCA工具需要对知识库(或称为源库我认为更合适)中的软件代码提取特征值,特征值提取分为五个级别,包括函数级、类级、文件级、包级和项目级。根据同源匹配粒度的精度选项,产品可以根据不同的特征值算法建立起相应特征值并入库建立索引,这些特征值索引库就是我们所说的同源分析中的源,是同源分析的基础。
特征值索引库生成技术从函数、类、文件、包、项目五个级别提取相应的特征值,这些特征值就是大家所说的代码指纹。下面我们对5个级别分别进行简单阐述。
一、函数级提取特征
原始代码会首先经过词法分析器,提取标识符、常量、关键字、运算符等标识单元,然后利用符号表进行规范化处理,以此生成函数级特征指纹。在函数级别抽取的特征包括:函数编号、函数代码的摘要值、函数包含的词法标识、函数的抽象语法树特征向量、函数程序依赖图的特征向量、对应源文件开始的行号、对应源文件结束的行号、函数描述文本等。
二、类级提取特征
在类级别抽取的特征包括:类编号、类代码的摘要值、类包含的词法标识、类的抽象语法树特征向量、类的程序依赖图的特征向量、对应源文件开始的行号、对应源文件结束的行号、类描述文本。
三、文件级提取特征
在文件级别抽取的特征包括:文件编号、文件代码的摘要值、文件包含的词法标识、文件的程序依赖图的特征向量、文件的描述文本。
四、包级提取特征
包是一个汇总特征,在包级别抽取的特征包括包编号、包下属的文件、类和函数特征,以及包的描述文本。
五、项目级提取特征
项目也是一个汇总特征,在项目级别抽取的特征包括项目编号、项目下属的包级别的特征,以及项目的描述文本。
基于特征库的匹配算法,则是从文本、标识、语法、语义四个方面进行匹配,称为指纹匹配算法。在每个方面存在三种匹配方式,第一种是依据摘要的匹配方式;第二种是依据特征向量或特征向量哈希值的匹配方式;第三种是针对标识袋(Bag-of-tokens)的部分索引的匹配方式。
(1)基于文本摘要的识别匹配算法
对于摘要特征,匹配算法可以精确匹配到相同摘要值的函数、类、文件以及包含该函数、类、文件的包和项目。
(2)基于词法的识别匹配算法
对于词法分析生成的标识袋特征,匹配算法可以利用其部分索引快速定位相似的函数、类、文件以及包含该函数、类、文件的包和项目。
(3)基于语法的识别匹配算法
对于语法分析生成抽象语法树的特征向量或其哈希值特征,匹配算法可以近似定位目标函数、类以及包含该函数、类的文件、包和项目。
(4)基于语义的识别匹配算法
对于语义分析生成程序依赖图或值依赖图的特征向量或其哈希值特征,匹配算法可以近似定位目标函数、类以及包含该函数、类的文件、包和项目。
各个级别对象所使用的特征提取方法如下表所示。
其中对应级别对象直接使用的特征提取方法用“√”表示,通过推导方式来提取特征的用“〇”表示,不适用相应级别对象的特征提取方法用“×”表示。
表 各级别对象的特征提取方法
| 特征提取 方法 对象 | 文本 | 标识 | 语法 | 语义 |
| 函数 | × | √ | √ | √ |
| 类 | × | 〇 | 〇 | 〇 |
| 文件 | √ | 〇 | 〇 | 〇 |
| 包 | 〇 | 〇 | 〇 | 〇 |
| 项目 | 〇 | 〇 | 〇 | 〇 |
下面按照上面表中的不同对象进行提取方法简单描述。
(1)函数级别的特征提取
函数级别的特征通过标识、语法和语义等特征提取方法提取,下面分别描述。
首先通过标识计算函数特征。需要将源代码仓库中的代码片段解析为<符号,频数>的集合并存储,而对于二进制代码,首先需要对二进制代码进行反汇编,依据汇编代码提取代码片段集合。每个代码片段有全局唯一的ID,通过统计所有的符号,生成全局符号频数表。接着利用在关键技术部分介绍的“子块重叠过滤”的思想,建立“部分索引”,具体过程如下:
①设相似度为θ,为平衡精确度和召回率,θ可取70%;
②查询全局符号频数表,将代码片段中的符号按全局频数升序排列;
③设代码片段中总符号数为N,选取前N - θN + 1个符号,建立符号-代码片段的反向索引。
其次通过语法计算函数特征。通过构建源代码函数级别的抽象语法树,以及二进制代码对应汇编代码的控制流图,构建语法级别的特征向量,并将特征向量存入数据库。抽象语法树上的特征分为树的节点个数、深度以及树的前向遍历顺序等类别,函数控制流图上的特征分为如下两类:
①跳转指令。具体地,本项目将跳转指令分为个数、位置与跳转目标
位置三个维度,其中位置和跳转目标位置使用相对位置进行编码,能够较为准确地抽象控制流图中的控制流特征。
②函数调用指令。该特征能够一定程度刻画函数的功能,例如如果仅调用字符串拼接函数,可能执行的是字符串操作功能。基于控制流图中的跳转指令特征和函数调用特征,以函数为单位计算特征值。这一步将特征向量计算为局部敏感的哈希值。
最后通过语义计算函数特征。首先对源代码进行值依赖分析。对二进制代码而言,仅反汇编是不够的,因为汇编代码在不同的指令架构中以及不同的操作系统中均有不同的结构,为构建统一的值依赖模型带来困难。为克服这个问题,本项目基于中间语言对二进制代码建立值依赖模型。国际上已存在很多类型中间语言,例如RREIL、Vine、BAP、LLVM IR等。本项目将基于RREIL语言实现二进制代码到中间语言的提升,从而消除指令架构、操作系统等在值依赖上的差异,使用统一的框架分析值依赖关系。对源代码或中间代码对应的中间表示进行进一步的值依赖分析,计算常量值并去除不可达路径,从而将中间代码进一步归一化,按照值依赖的依赖关系(即依赖图中的指向关系),构建各依赖子图上的特征向量,存入数据库。
对二进制代码而言,根据编译选项,同一个源代码可以有多个二进制目标码的表现形式。通常要考虑到几个重要的编译选项类别,比如目标平台、调试与否、动态或静态链接,以及其他一些优化选项,而且不同的编译器的特点也不尽相同。因此,需要就二进制的多种编译状态进行函数特征提取,从而能够判断多个编译器、多个编译选项的二进制文件,实现识别匹配。
(2)类级别的特征提取
如果分析的是面向对象语言的源代码,则类级特征通过函数特征推导得出。同时计算匹配到的函数占类中所有函数的比例,根据阈值决定类级的推导结果。
(3)文件级别的特征提取
文件级别的特征通过文本特征提取方法提取。具体而言,首先将该项目分解为包和文件,并将包进一步分解为多个文件。文本特征通过MD5的方式求得。对于二进制代码,基于字节流的方式计算MD5值。
此外,通过类和函数级别的特征推导文件级别的特征。通过计算匹配到的类和函数占文件中所有类与函数的比例,根据阈值决定文件级的推导结果。
(4)包与项目级别的特征提取
包和项目级别的特征通过文件特征推导得出。根据上一级别得到匹配的文件的个数,计算匹配的相似度。根据预设的阈值决定包与项目级别的推导结果。
(结束)