大数据知识图谱项目——基于知识图谱的电影问答系统(超详细讲解及源码)
一、项目概述
知识图谱是将知识连接起来形成的一个网络。由节点和边组成,节点是实体,边是两个实体的关系,节点和边都可以有属性。知识图谱除了可以查询实体的属性外,还可以很方便的从一个实体通过遍历关系的方式找到相关的实体及属性信息。
本项目基于电影知识的问答,通过搭建一个电影领域知识图谱,并以该知识图谱完成自动问答与分析服务。本项目以neo4j作为存储,基于传统规则的方式完成了知识问答,并最终以关键词执行cypher查询,并返回相应结果查询语句作为问答。
该问答系统完全基于规则匹配实现,通过关键词匹配,对问句进行分类,电影问题本身属于封闭域类场景,对领域问题进行穷举并分类,然后使用cypher的match去匹配查找neo4j,根据返回数据组装问句回答,最后返回结果。
二、实现知识图谱的医疗知识问答系统基本流程
1、建立图谱(结构化的,详见代码;非结构化的需要的NLP特别多)
2、构建类别判定(可以基于机器学习方法或者深度学习方法的文本分类或者是基于关键字的规则方法)(本文为规则方法)
3、提取问题中的实体
4、根据类别和实体构建查询语句并查询
5、根处理查询结果并输出
三、实现知识图谱的电影问答系统基本流程
Neo4j版本:Neo4j Desktop1.4.15;
neo4j里面医疗系统数据库版本:4.4.5;
Pycharm版本:2021;
JDK版本:jdk1.8.0_211;
NongoDB版本:MongoDB-windows-x86_64-5.0.14;
四、Node4j实验环境的安装配置
(一)安装JAVA
1.下载java安装包:
官网下载链接:https://www.oracle.com/java/technologies/javase-downloads.html
本人下载的版本为JDK-1.8,JDK版本的选择一定要恰当,版本太高或者太低都可能导致后续的neo4j无法使用。
安装好JDK之后就要开始配置环境变量了。 配置环境变量的步骤如下:
右键单击此电脑—点击属性—点击高级系统设置—点击环境变量
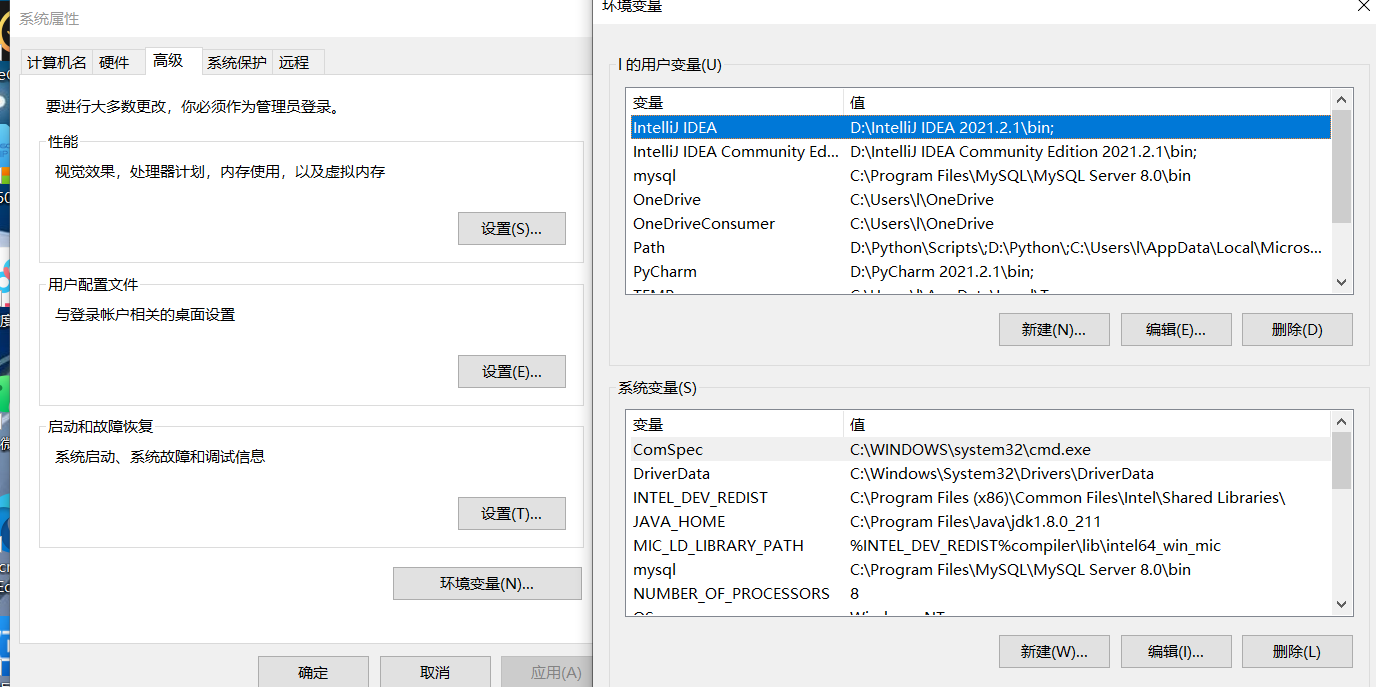
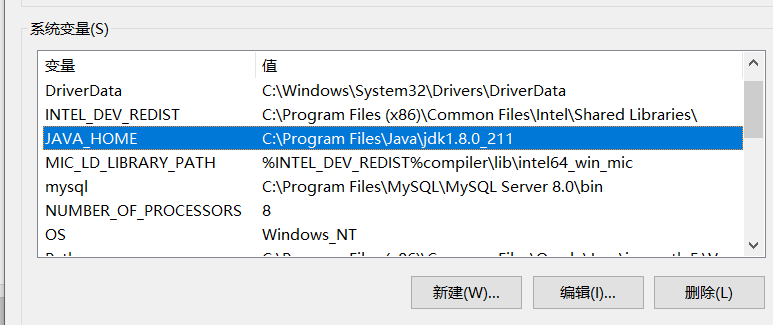
在下方的系统变量区域,新建环境变量,命名为JAVA_HOME,变量值设置为刚才JAVA的安装路径,我这里是C:\Program Files\Java\jdk1.8.0_211
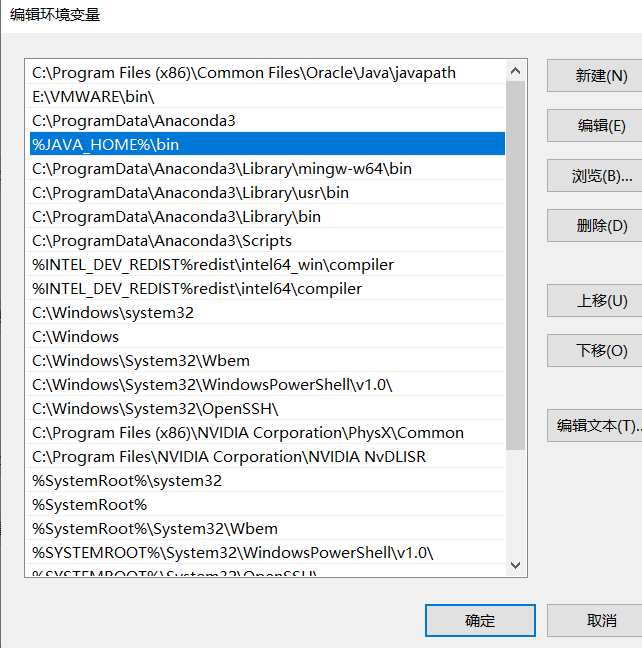
编辑系统变量区的Path,点击新建,然后输入 %JAVA_HOME%\bin
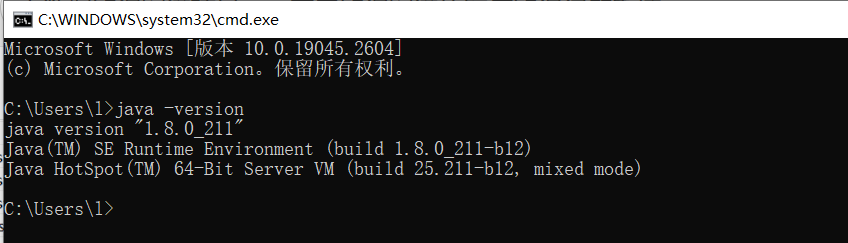
打开命令提示符CMD(WIN+R,输入cmd),输入 java -version,若提示Java的版本信息,则证明环境变量配置成功。
2.安装好JDK之后,就可以安装neo4j了
2.1 下载neo4j
官方下载链接:https://neo4j.com/download-center/#community
也可以直接下载我上传到云盘链接:
Neo4j Desktop Setup 1.4.15.exe
https://www.aliyundrive.com/s/huXS4HXMn9V
提取码: 36vf
打开之后会有一个自己设置默认路径,可以根据自己电脑情况自行设置,然后等待启动就行了
打开之后我们新建一个数据库,名字叫做:“基于电影领域的问答系统”
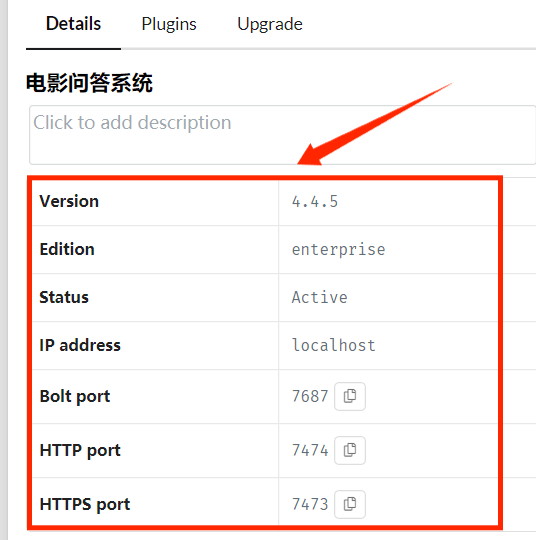
详细信息看下图:
数据库所用的是4.4.5版本,其他数据库参数信息如下:
项目结构整体目录:
├── README.md // 描述文件
├── 建立词表.py // 建立词表的程序文件
├── 建立图谱.py // 建立知识图谱的程序文件
├── chatbot_graph.py // 聊天系统主函数文件/运行文件
├── question_classifier.py // 聊天系统问题分类函数
├── question_parser.py // 聊天系统问题转换函数
├── answer_search.py // 聊天系统问题回复函数
├── genre.txt // 建立的词表
├── movie.txt // 建立的词表
├── person.txt // 建立的词表
└── data //数据文件
└── genre.csv // 图谱数据集之一
└── movie_to_genre.csv // 图谱数据集之一
└── movie.csv // 图谱数据集之一
└── person_to_movie.csv // 图谱数据集之一
└── person.csv // 图谱数据集之一
└── userdict3.txt // 图谱数据集之一
└── vocabulary.txt // 图谱数据集之一
└── question // 问题模版(项目中未用,但参考了)
└── ... // 16个问题模版
问答系统框架的构建是通过chatbot_graph.py、answer_search.py、question_classifier.py、question_parser.py等脚本实现。
五、系统实现具体步骤
下面给大家简单介绍一下里面的部分内容和源码。
创建一个“电影问答系统”的知识图谱项目,选择默认的neo4j(defult)数据库:

数据库所用的是4.4.5版本,其他数据库参数信息如下:
我们点击open进去数据库浏览器界面
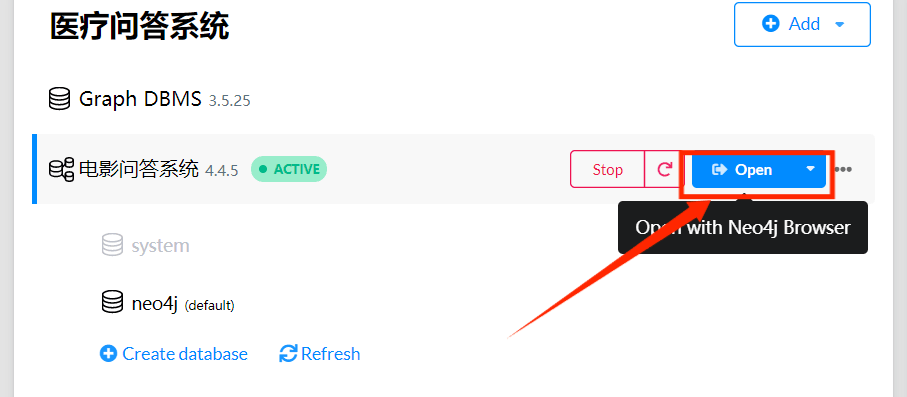
里面有我们的端口号和连接用户名user:
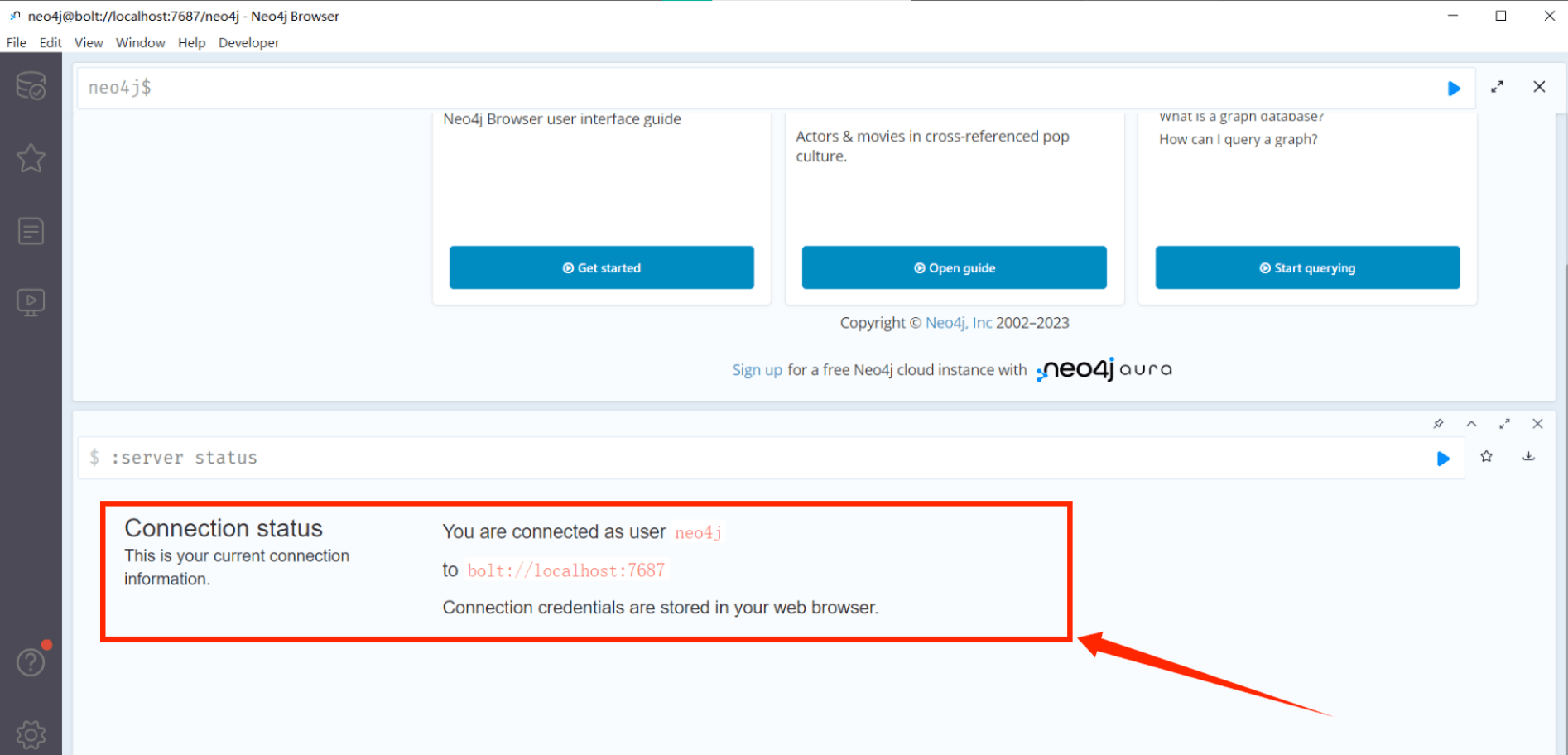
将我们脚本的端口号、用户名和密码与neo4j里面保持一致。
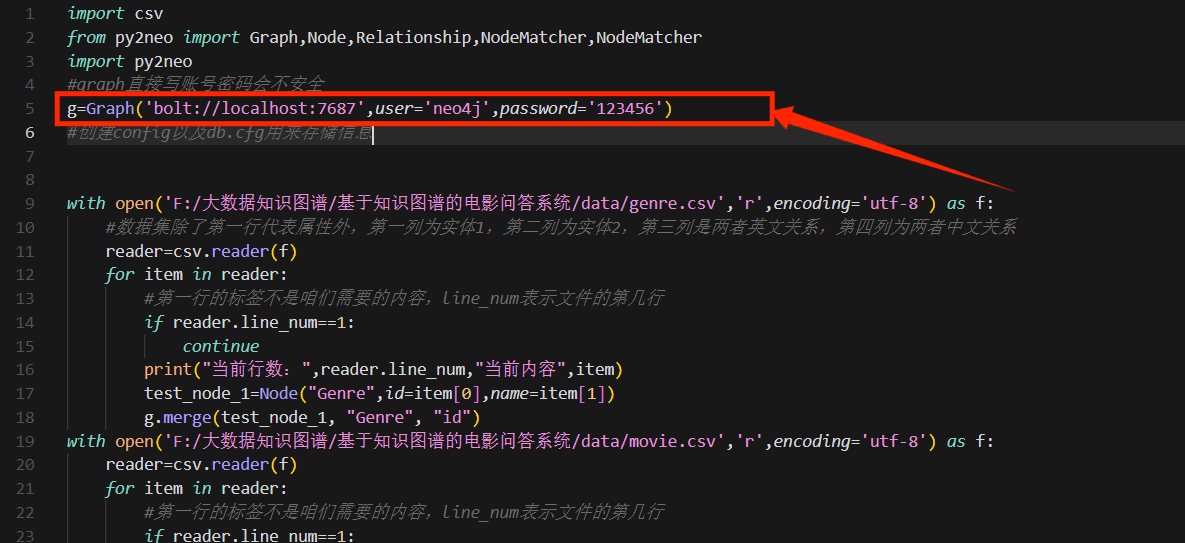
#graph直接写账号密码会不安全
g=Graph('bolt://localhost:7687',user='neo4j',password='123456')
#创建config以及db.cfg用来存储信息
建立一个与Neo4j图数据库的连接。Graph是py2neo库中的一个类,用于创建一个图数据库的实例。在这里,通过指定bolt://localhost:7687作为数据库的地址和端口,user和password作为登录凭据,来创建一个名为g的图数据库对象。这个对象可以用来执行与数据库相关的操作,比如创建节点、创建关系等。
构建词表和图谱时候,路径要跟我们本地设置的目录保持一致:
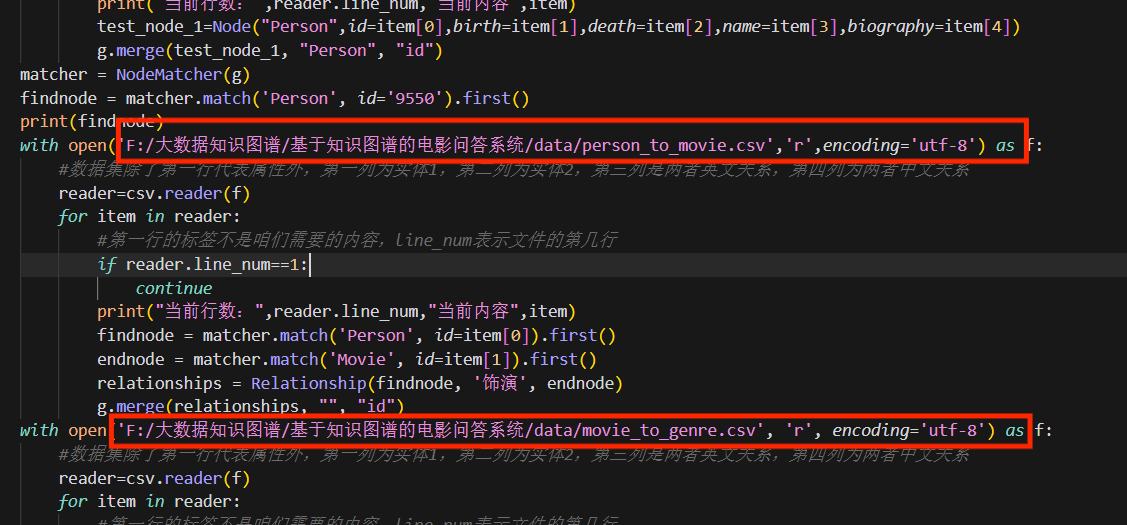
answer_search.py脚本部分代码截图:
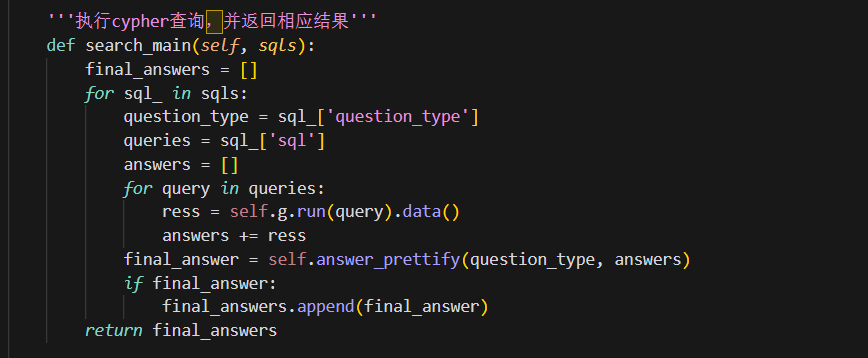
定义一个名为search_main的方法,它接受一个参数sqls,该参数是一个包含多个字典的列表。每个字典代表一个查询,包含两个键:question_type和sql。question_type表示查询的类型,sql是一个包含一个或多个Cypher查询的列表。在方法内部,它首先创建一个空列表final_answers,用于存储最终的答案。然后,它遍历sqls列表中的每个字典。对于每个字典,它提取question_type和sql的值,并创建一个空列表answers来存储查询结果。
接下来,它遍历queries列表中的每个查询,并使用self.g.run(query).data()执行Cypher查询,并将结果添加到answers列表中。最后,它调用answer_prettify方法,将question_type和answers作为参数传递,并将返回的结果存储在final_answer变量中。如果final_answer不为空,则将其添加到final_answers列表中。最后,方法返回final_answers列表,其中包含了所有查询的答案。通过执行一系列的Cypher查询,并将查询结果进行处理和美化,然后返回最终的答案列表。
question_classifier.py脚本部分代码截图:
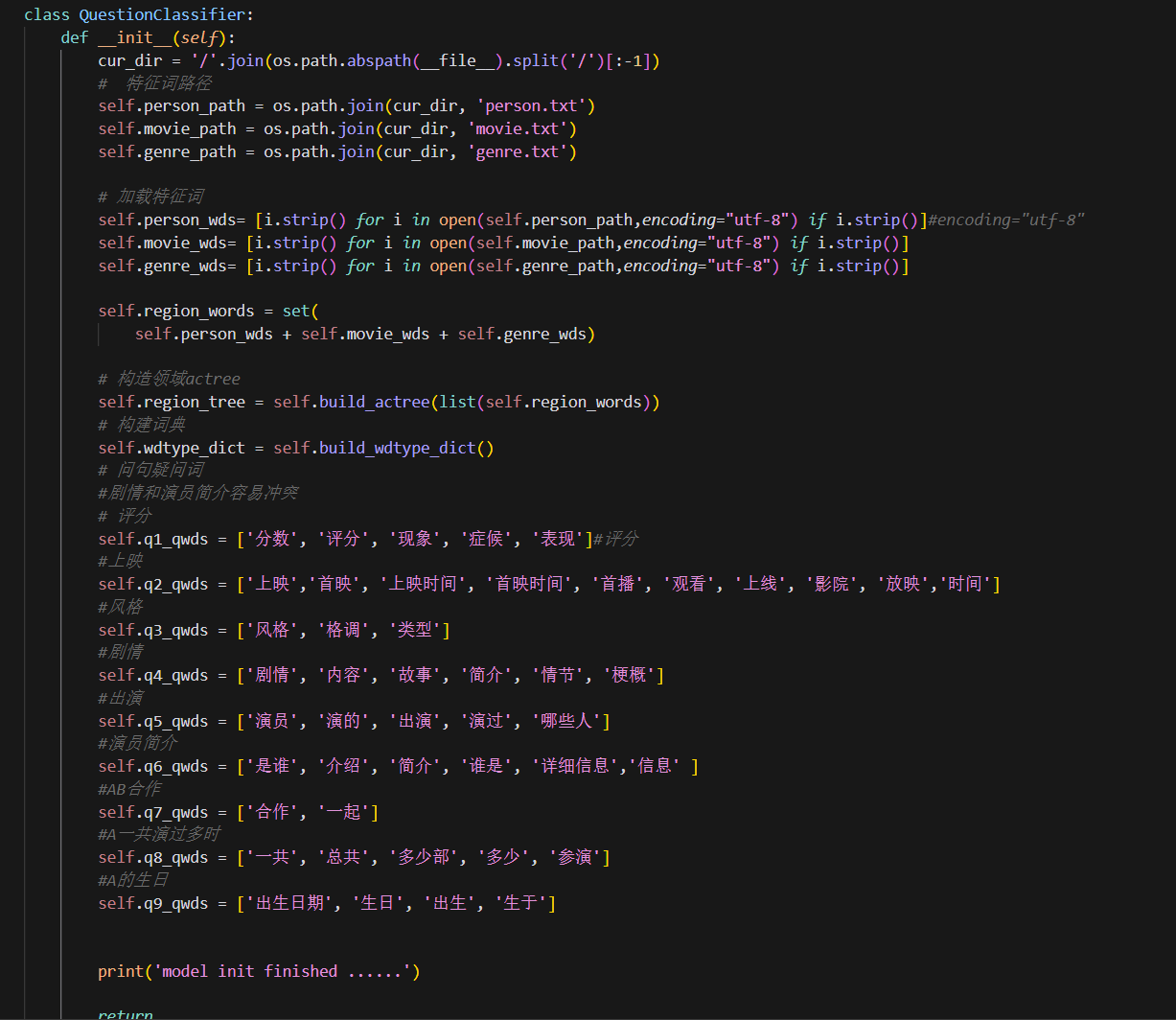
question_classifier.py脚本根据问题的内容将问题分类到不同的类型中。在QuestionClassifier类的构造函数中,首先获取当前文件的路径,并根据路径拼接出特征词文件的路径。然后,加载特征词文件中的内容,分别存储到person_wds、movie_wds和genre_wds这三个列表中。接着,将这三个列表中的元素合并到region_words这个集合中。
接下来,通过调用build_actree方法构造了一个领域actree,用于加速过滤。然后,调用build_wdtype_dict方法构建了一个词对应类型的字典wdtype_dict。在构造函数的最后,定义了一些问句疑问词的列表,用于判断问题的类型。这些列表包括评分、上映、风格、剧情、出演、演员简介、合作出演、总共和生日等。最后,打印出初始化完成的提示信息。作用是初始化一个问题分类器对象,并加载特征词和构建相关数据结构,为后续的问题分类做准备。
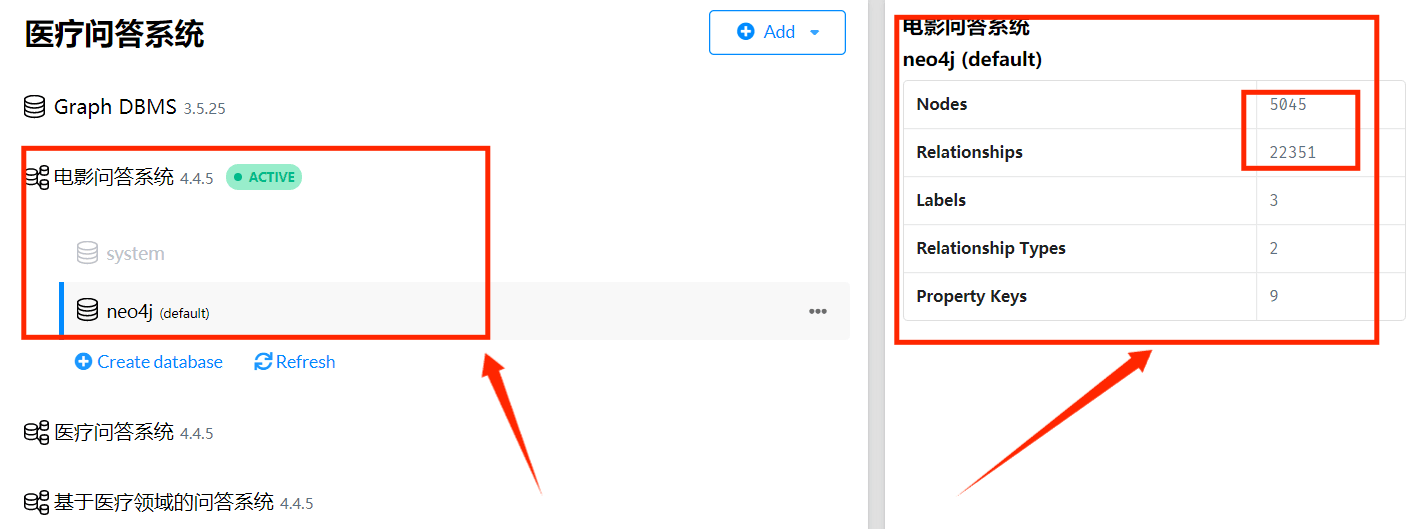
成功构建电影知识图谱节点和关系!
脚本运行完之后查看neo4j数据库中构建的知识图谱:
match (n) return n
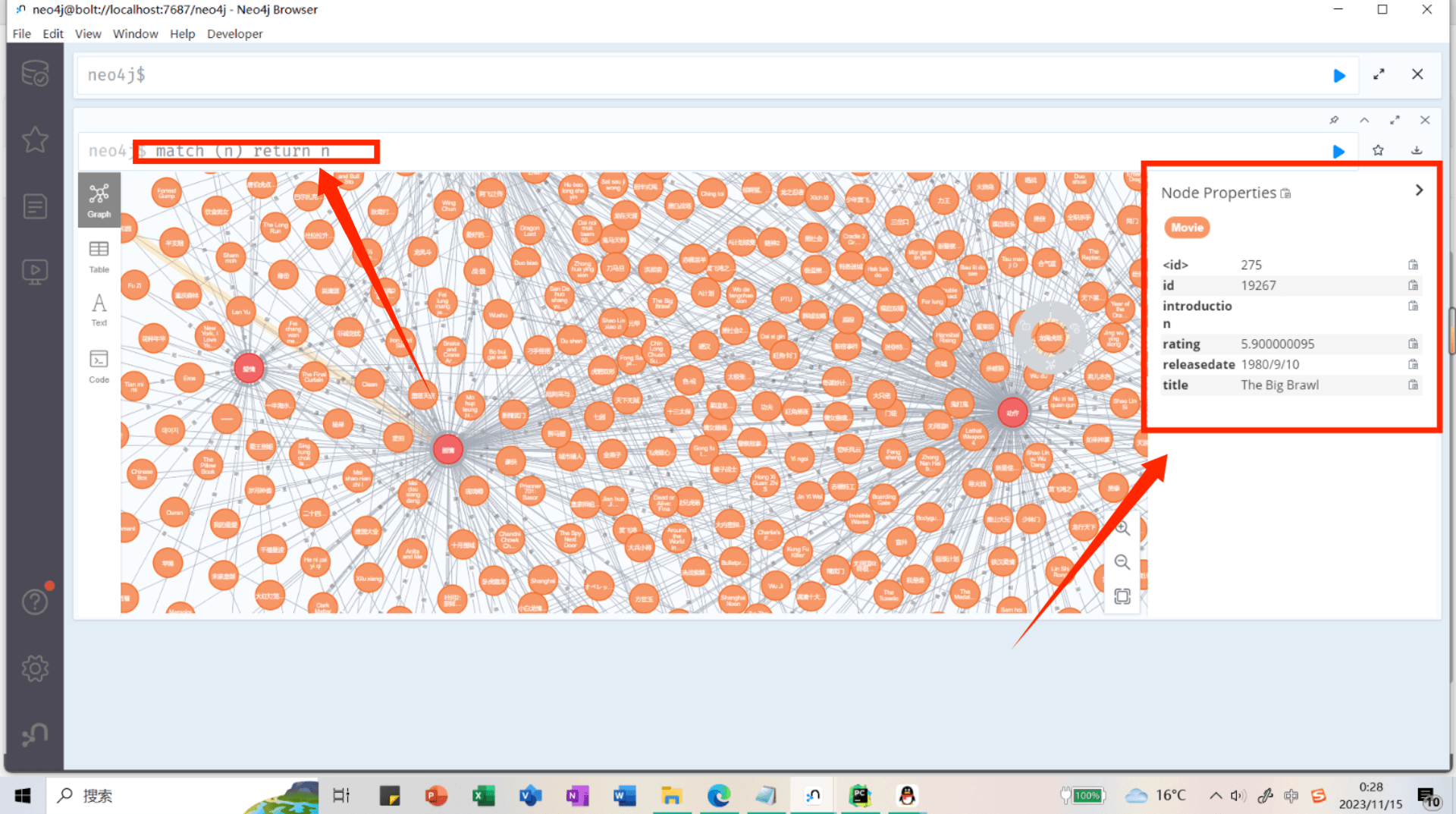

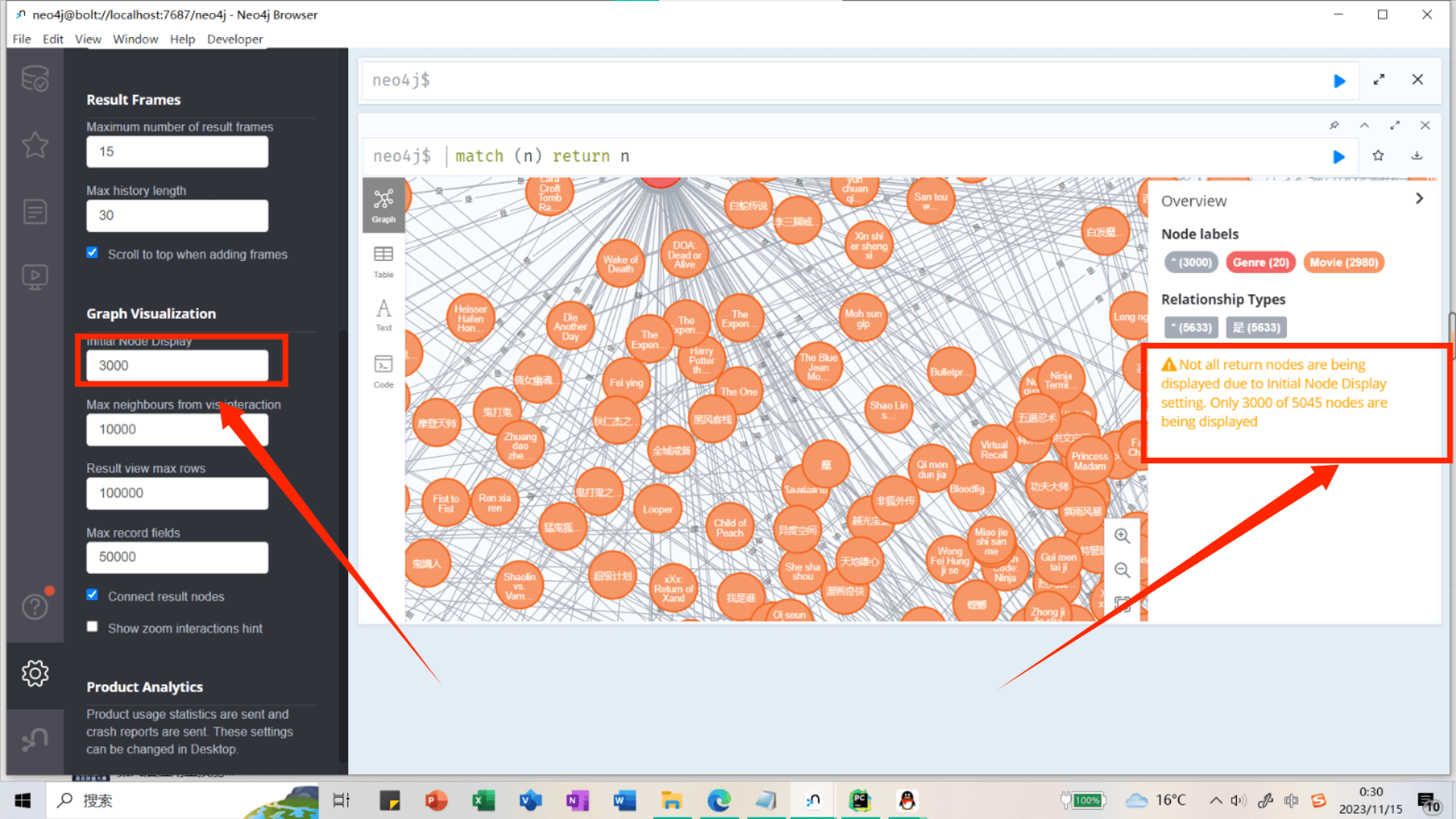
这里提示:Not all return nodes are being displayed due to Initial Node Display setting. Only 3000 of 5045 nodes are being displayed
由于“初始节点显示”设置,并非所有返回节点都显示。5045个节点中仅显示3000个
这里因为我设置的参数只显示前3000个,只显示了一部分,可以根据自己需求自由设置。
问答框架包含问句分类、问句解析、查询结果三个步骤,首先是构建词表和建立图谱;
问句分类,是通过question_classifier.py脚本实现的。
question_parser.py脚本进行问句分类后对问句进行解析。
answer_search.py脚本对解析后的结果进行查询
chatbot_graph.py脚本进行问答实测。
流程: chatbot_graph(总控)->question_classifier(分类)->question_parser(构建查询语句)->answer_search(处理查询结果并输出)
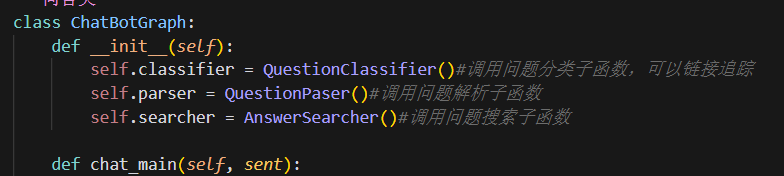
这个chatbot_graph脚本是整个问答系统的主程序。首先创建了一个ChatBotGraph类,包含了三个主要的组件:问题分类器(QuestionClassifier)、问题解析器(QuestionParser)和答案搜索器(AnswerSearcher)。在ChatBotGraph类的构造函数中,初始化了这三个组件的实例。QuestionClassifier用于对用户输入的问题进行分类QuestionParser用于解析分类结果,AnswerSearcher用于搜索合适的答案。chat_main方法是主要的交互逻辑。它接收用户输入的问题作为参数,并依次调用分类器、解析器和搜索器来获取最终的答案。如果没有找到合适的答案,将返回一个默认的回答。在代码的最后部分,创建了一个ChatBotGraph的实例,并通过一个死循环不断接收用户输入的问题,并输出对应的回答。
当我们执行chatbot_graph.py主程序,开始实现电影知识问答:
“您好!请输入您想要提问的电影知识问题:”
我们输入一个简单的问题:“李连杰和成龙的简介”
问答系统返回的结果如下:

再试试其它的问题:比如十面埋伏的评分、十面埋伏和功夫的简介、黄飞鸿之三狮王争霸里面的演员等等,当然不仅限于此,还有很多关于电影知识方面都可以问,对脚本也进行了一些优化。
问答系统返回结果如下:



最后总结一下本文章基于电影问答系统的主要特征是知识图谱,系统依赖一个或多个领域的实体,并基于图谱进行推理或演绎,深度回答用户的问题,更擅长回答知识性问题,与基于模板的聊天机器人有所不同的是它更直接、直观的给用户答案。本项目问答系统没有复杂的算法,一般采用模板匹配的方式寻找匹配度最高的答案,可以直接给出答案。经过测试本问答系统能回答的问题有很多,基于问句中存在的关键词回答效果表现很好。做出来的基于电影知识问答系统能够根据用户提出的问题很好的进行解答。做出来的问答系统还是很Nice的。
我还写了另一篇关于大数据知识图谱项目——基于知识图谱的医疗知识问答系统(超详细讲解及源码)的文章,附链接:
https://blog.csdn.net/Myx74270512/article/details/129147862?spm=1001.2014.3001.5502
这里只是简要介绍一下项目的部署和一些细节部分,具体详细内容和部署细节在开发文档里面,各位有兴趣的小伙伴可以私信我要详细的项目开发文档、完整项目源码和其它相关资料。

欢迎各位小伙伴的来访!