目录
- 一、全功能AI开发平台介绍
- 二、AI项目落地应用流程(以文本分类为例)
- 2-0、项目开始
- 2-1、项目背景
- 2-2、数据准备介绍
- 2-3、项目数据
- 2-4、建模调参介绍
- 2-5、项目的建模调参
- 2-6、开发部署
- 2-7、项目在公有云的部署
- 附录:调用api代码
- 总结
一、全功能AI开发平台介绍

全功能AI开发平台是一个综合性的平台,旨在支持各种人工智能(AI)应用的开发、部署和管理。这些平台通常提供一系列工具、库和服务,以帮助开发者、数据科学家和工程师创建和操作各种类型的AI应用。以下是全功能AI开发平台通常提供的一些功能和特性:
- 数据管理:提供数据存储、数据集成、数据清洗和数据标注工具,以支持AI模型的训练和评估。
- 模型开发:包括模型训练、调优和验证工具,以及深度学习框架集成,使开发者能够创建自定义AI模型。
- 自动化ML(AutoML):提供自动化工具,可以自动选择和调整模型参数,以简化模型开发流程。
- 部署和托管:支持AI模型的部署到云端或边缘设备,并提供自动扩展和管理模型的能力。
- 可解释性和监控:提供模型解释性工具,以及实时性能监控和错误检测,以确保AI应用的可靠性和可解释性。
- 集成和API:支持将AI功能集成到现有应用程序中,以及提供API,以便其他应用程序可以调用AI模型。
- 安全性和隐私:提供安全性和隐私保护功能,以确保AI应用的数据和模型的安全性。
- 可视化工具:提供可视化界面,以简化模型训练和部署的管理和监控。
下面以百度BML全功能AI开发平台为例进行介绍(一站式AI开发流程如下),且底层框架内置文心大模型基座:

二、AI项目落地应用流程(以文本分类为例)
2-0、项目开始
任务抽象:
- 项目有多少个任务场景
- 每个任务场景需要开发多少个模型
- 部署场景的约束是什么
任务流程介绍:
- 采集/标注数据
- 选择预训练模型
- 数据增强策略
- 超参数调整
- 模型训练以及评估
- 分析报告
2-1、项目背景
项目背景介绍:
在我们的生活和工作中,很多事情都可以转化为一个分类问题来解决,比如“上班坐公交还是坐地铁”、“吃米饭还是吃面条”等等可以转化为二分类问题。自然语言处理领域也是这样,大量的任务可以用文本分类的方式来解决,比如垃圾文本识别、涉黄涉暴文本识别、意图识别、文本匹配、命名实体识别等,有着极其广泛的应用场景:
- 投诉信息分类:训练客服投诉信息的自动分类,将每个用户投诉的内容进行分类管理,节省大量客服人力。
- 媒体文章分类:训练网络媒体文章的自动分类,进而实现各类文章的自动分类。
- 文本审核:定制训练文本审核的模型,如训练文本中是否含有违规/偏激性质的描述。
中文新闻文本标题分类任务简介:
- 新闻分类是文本分类中常见的应用场景。在传统分类模式下,往往是通过人工对新闻内容进行核对,从 而将新闻划分到合适的类别中。这种方式会消耗大量的人力资源,并且效率不高。采用深度学习的方法可以取得较高的分类精度,是新闻推荐等场景下的基础任务。
使用BML开发平台,注册账号并且开始使用:官方链接

2-2、数据准备介绍
项目数据:
- 项目任务需要什么样的数据
- 如何制作高质量的数据集(图片数据:是否存在高度相似、模糊的图片,进行数据的清洗)
- 数据量不够怎么办(每一类的图片数量是否大于80张?是否需要增加图片以平衡类别数量?进行上采样?)
高质量数据:
- 数据标注正确
- 尽量提升数据的类别,提升模型的泛化能力
- 保证训练数据尽量与业务数据接近,各个类别平衡
- 数据划分正确,测试集验证集不会泄露。
- 以结果为导向看数据:看哪个类别的数据模型不太擅长识别,即分析badcase,采用数据增强增加数据数量。
数据增强(以图片的数据增强为例):
- 对比度
- 色平衡
- 亮度
- 锐化
- 目标框裁剪
- 标注框旋转
- 标注框翻转
- 水平裁剪
BML平台优势:
- 智能标注
- 多人标注
- 数据质检报告
- 支持与数据采集设备直连
- BML自动化数据清洗:去近似、去模糊、裁剪、旋转、镜像。
- 自动数据增强。开放超过40种算子,灵活配置

2-3、项目数据
本文采用中文新闻文本标题分类数据集进行示例:数据

- 点击数据集管理,并创建数据集。

- 在创建数据集界面,设置好相关信息并点击完成

-
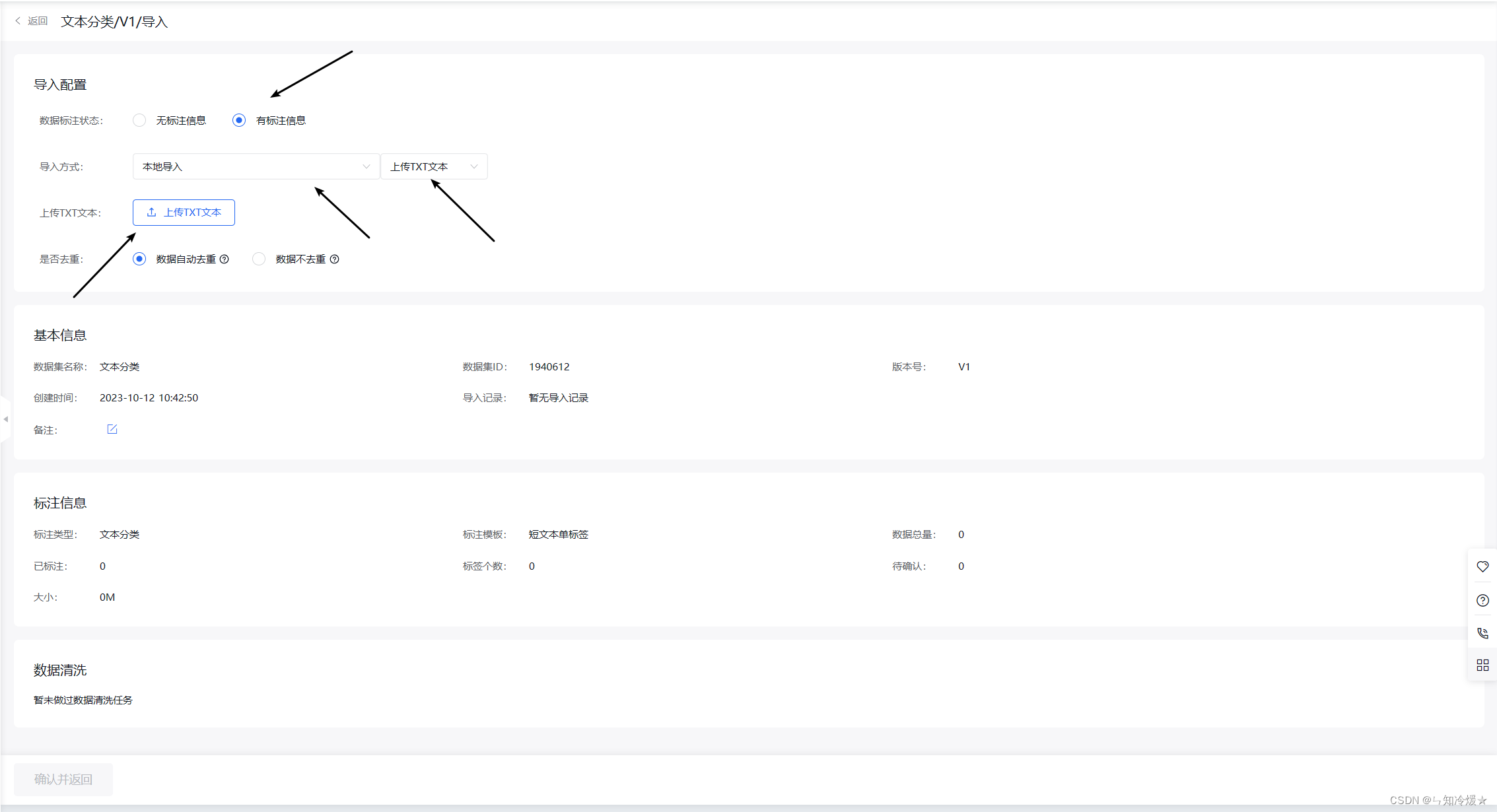
填写导入配置信息: 设置数据的标注状态,是否为有标注信息,从本地导入,上传txt文本。之后点击上传txt文本将下载好的数据上传。
-
数据集创建完成后,可以在数据集管理界面看到导入的数据,并可以查看到导入状态、标注状态等信息。

2-4、建模调参介绍
建模调参:
- 选择什么样的模型
- 有没有精度更高的模型
- 如何调优,进一步提升性能
- 要不要购买服务器?
BML平台优势:
- 提供预置模型调参、NoteBook建模、自定义作业建模等三种开发方式,满足不同需求的开发者。

- 自动调参:以某种高级策略搜索超参组合,自动获得优秀的模型效果

2-5、项目的建模调参
- 选择使用预置模型调参,选择自然语言处理模型,点击创建任务

- 选择类型为文本分类-类型为单文本单标签。

- 创建完成后点击新建运行。

- 添加数据可以选择刚才导入的数据集,也可以选择公开数据集(二分类。数据量较少),需要注意的是,如果选择公开数据集,可以跳过前边的所有步骤。



- 在配置模型阶段,可以进行相关预训练模型的配置以及超参数的设置。Tiny版本模型更小,训练速度更快,但是精度略差。之后设置训练资源,以及选择计算节点。提交运行任务。


- 训练结束后点击评估报告,可以查看模型的表现情况(由于时间原因,我这里选择的是公开二分类数据进行训练), 点击配置详情可以查看训练时设置的参数,训练可视化可以查看训练过程中的指标变化


- 进一步测试模型可以点击发布按钮进行模型的发布, 发布模型之后可以在发布模型这一列看到已经发布的模型,这时候点击评估报告可以看到模型校验按钮,可以进行模型的校验,输入文本进行校验。


2-6、开发部署
部署环境:
云端:公有云部署,即将模型部署为在线服务,从而以REST API的方式提供推理预测能力。且公有云部署是最快捷的模型部署方式,不同类型的模型在执行公有云部署时的流程基本一致,当部署后在线API的接口与模型有关。
- 易于部署迭代
- 可使用大模型,快速上线
- 高延迟
- 成本线性升高
边缘端:
- 算力限制
- 前期开发部署成本高
- 低延迟
- 成本可控
在线服务说明:在线服务当前仅允许一个模型版本处于上线状态,若上线时有其他模型版本在线,则会将当前版本下线并且上线新的版本。服务状态以及其含义说明如下所示:


2-7、项目在公有云的部署
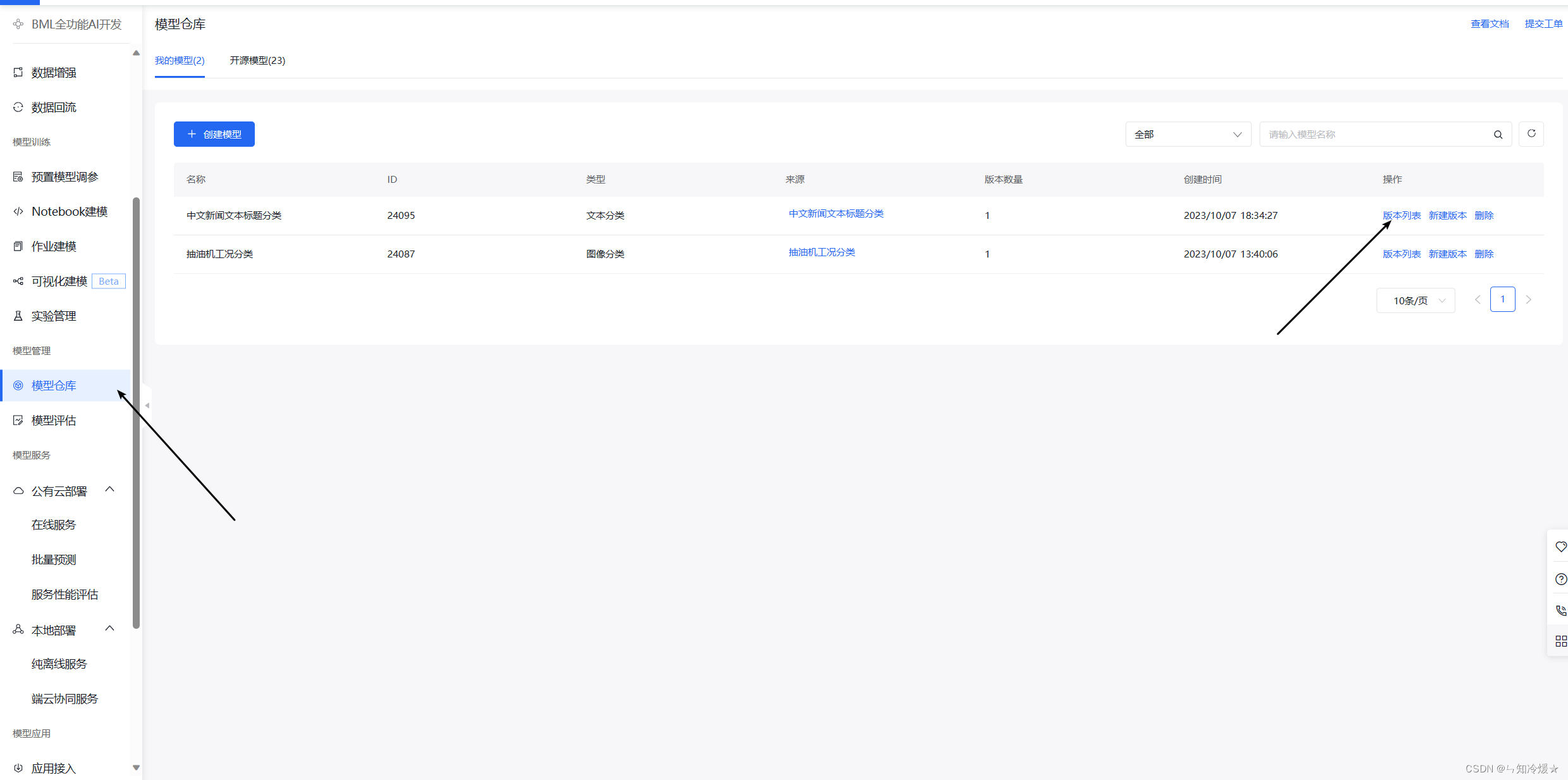
- 在模型仓库中选择发布的模型版本,之后进行在线服务部署。
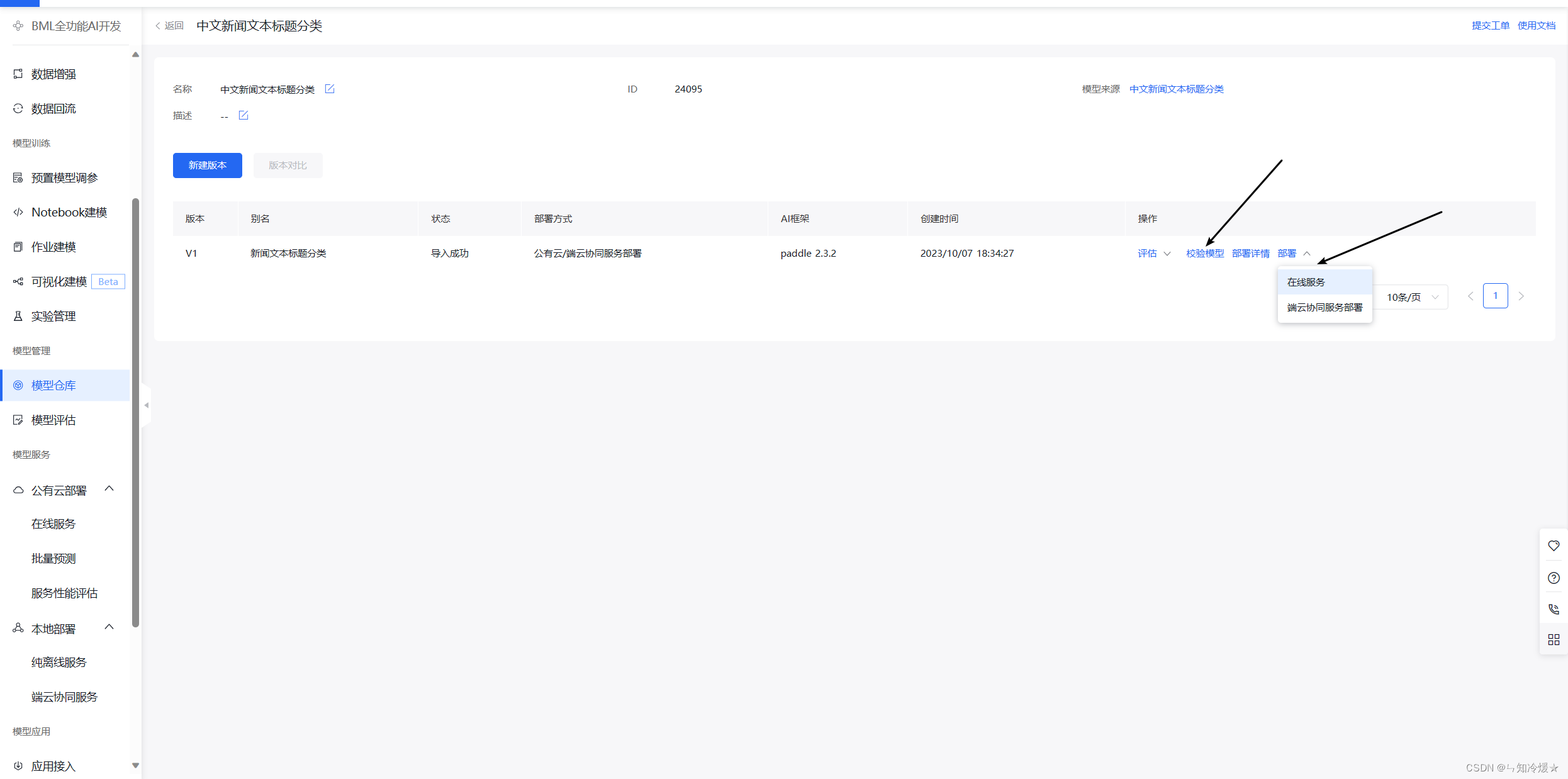
- 在线服务设置:设置服务名称以及接口地址,模型配置阶段设置已经发布的模型以及对应版本,在资源配置阶段设置好需要使用的配置,按照小时计费。
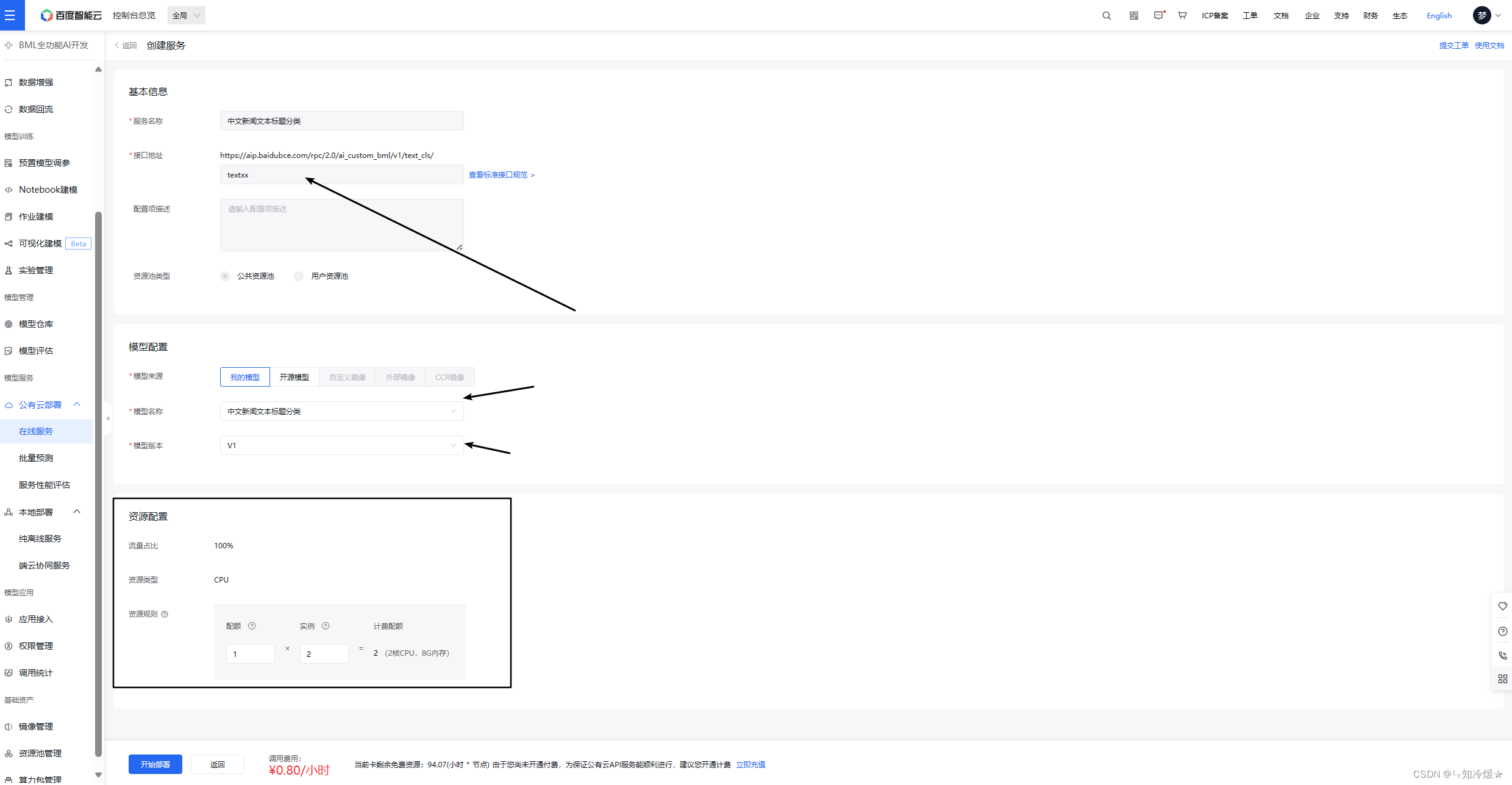
- 创建好在线服务之后,创建应用,之后调用接口进行服务调用
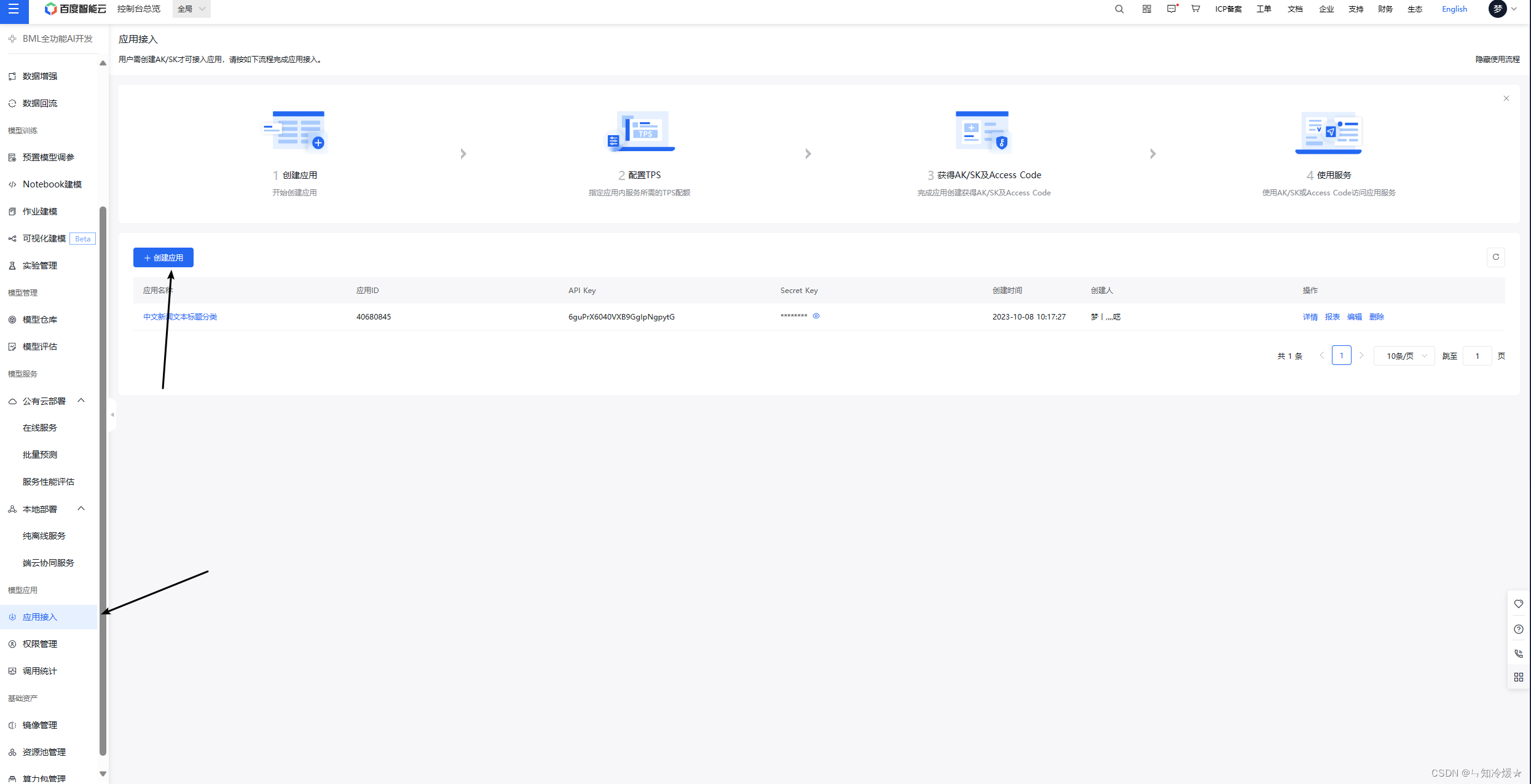
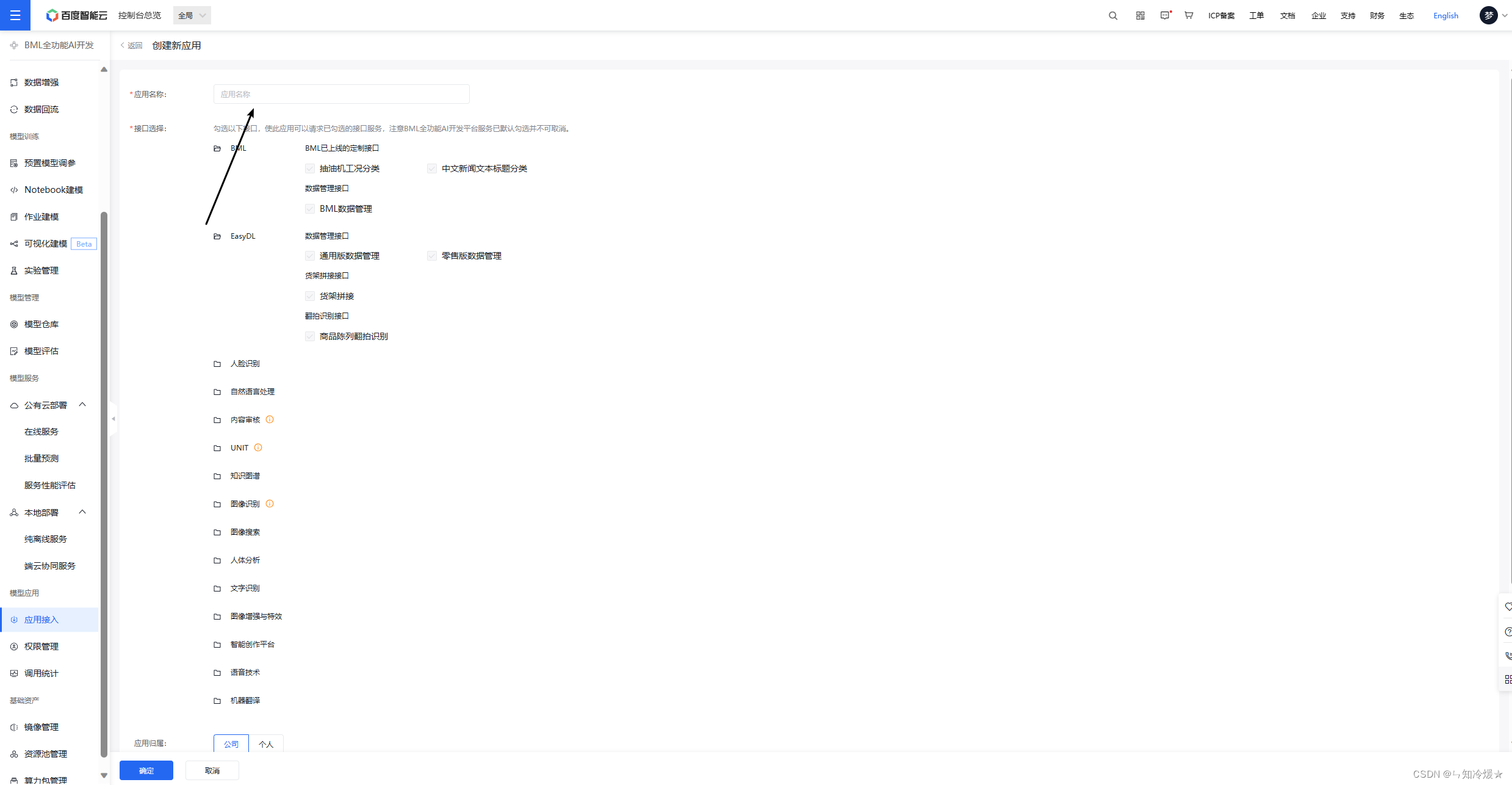
- 之后使用ak、sk以及请求url来进行接口的调用
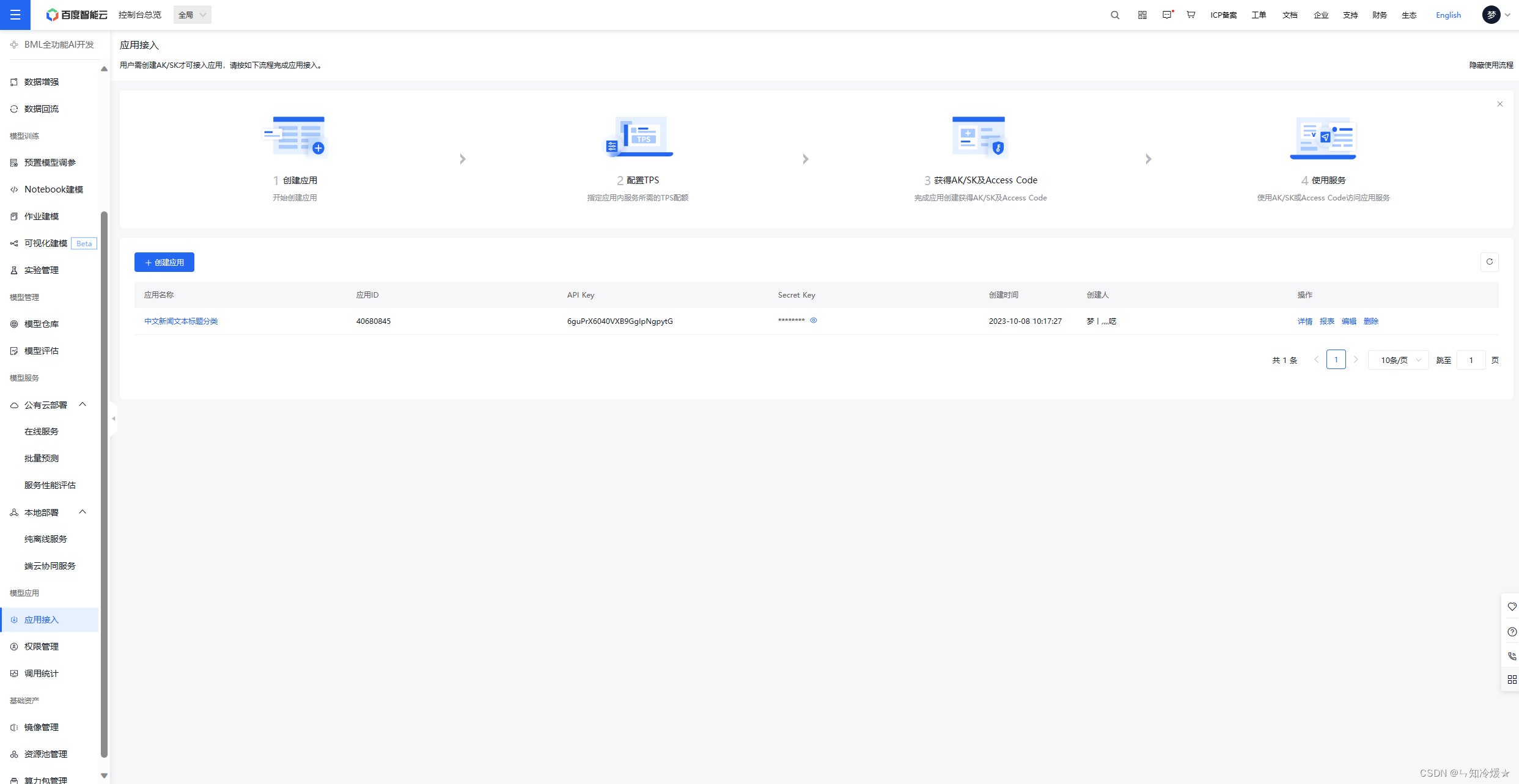
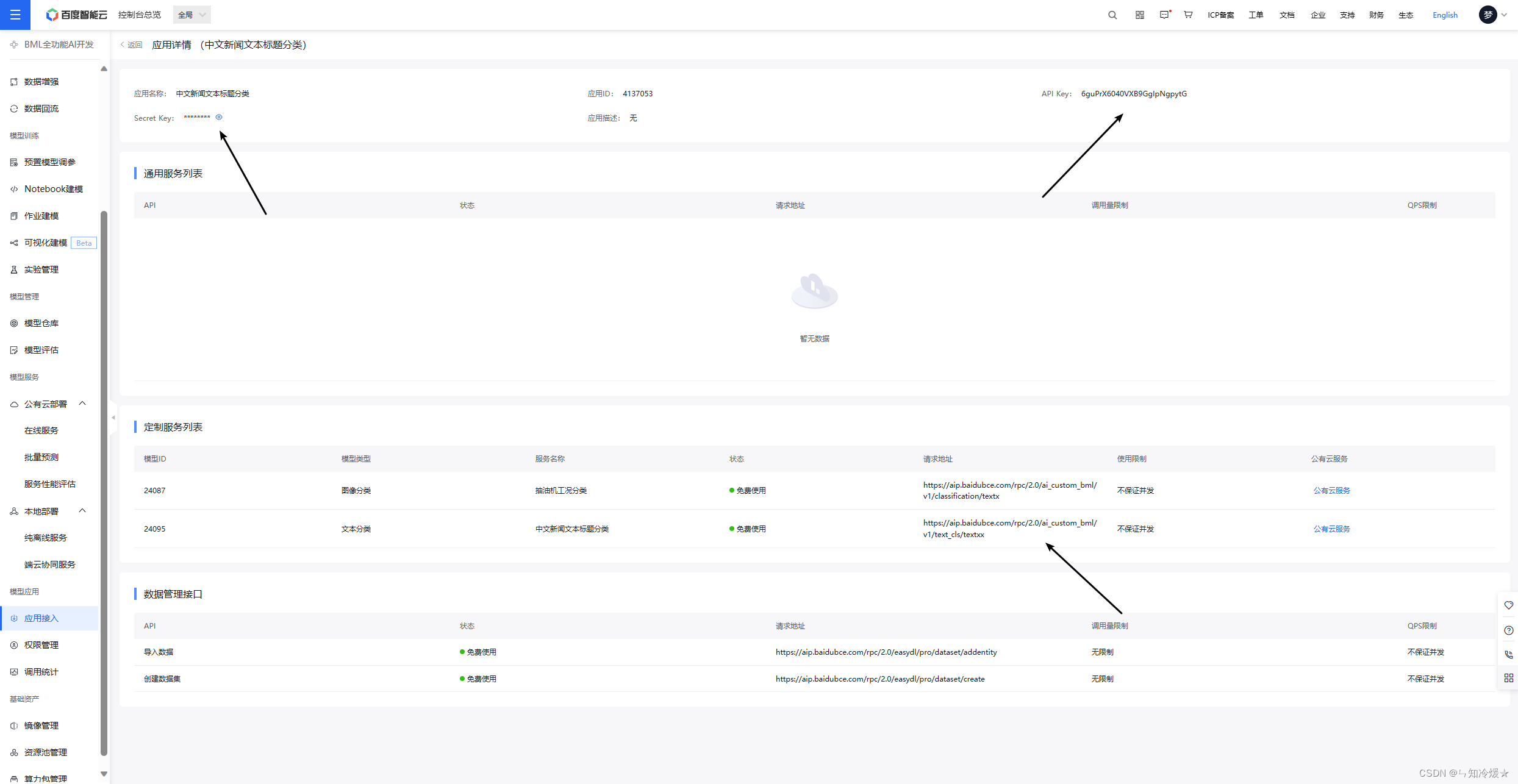
附录:调用api代码
import requests
import json
API_KEY = ""
SECRET_KEY = ""
def main():
url = "https://aip.baidubce.com/rpc/2.0/nlp/v1/sentiment_classify?charset=&access_token=" + get_access_token()
payload = json.dumps("")
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
def get_access_token():
"""
使用 AK,SK 生成鉴权签名(Access Token)
:return: access_token,或是None(如果错误)
"""
url = "https://aip.baidubce.com/oauth/2.0/token"
params = {"grant_type": "client_credentials", "client_id": API_KEY, "client_secret": SECRET_KEY}
return str(requests.post(url, params=params).json().get("access_token"))
if __name__ == '__main__':
main()
参考文章:
百度BML全功能开发平台官网.
数据集管理.
EasyDL文本价格整体说明.
开发文档训练、部署等.
鉴权认证机制.
服务与支持文档.
示例代码中心.
总结
人有悲欢离合,月有阴晴圆缺,此事古难全。
![2023年中国尾气净化催化材料产量、需求量及行业市场规模分析[图]](https://img-blog.csdnimg.cn/img_convert/be5fc300e375b0aabdbbaaeaae32c557.png)
![2023年中国印花布产量及发展前景分析:数码印花将成为行业趋势[图]](https://img-blog.csdnimg.cn/img_convert/e35ceb5895aea779c747f6625f79bdad.png)

![2023年中国光纤传感器发展历程、需求量及行业市场规模分析[图]](https://img-blog.csdnimg.cn/img_convert/956c73b5040d9725b7fda9e0d36335bd.png)