ID生成规则必要性
软件上要求
- 全局唯一
不能出现重复的ID号,既然是唯一标识,这是最基本的要求 - 趋势递增
在MySQL的InnoDB引擎中使用的是聚集索引,由于多数RDBMS使用Btree的数据结构来存储索引数据,
在主键的选择上面我们应该尽量使用有序的主键保证写入性能 - 单调递增
保证下一个ID一定大于上一个ID,例如事务版本号、IM增量消息、排序等特殊需求 - 信息安全
如果ID是连续的,恶意用户的扒取工作就非常容易做了,直接按照顺序下载指定URL即可;如果是订单号就更危险了,竞对可以直接知道我们一天的单量。所以在一些应用场景下,需要书无规则不规则,让竞争对手不好猜。 - 含时间戳
利于排查
硬件上的要求
ID号生成系统高可用性
高可用:发一个获取分布式ID的请求,服务器就要保证99.999%的情况下给我创建一个唯一分布式ID
低延迟:发一个获取分布式ID的请求,服务器就要快,极速
高QPS:假如并发一口气10万个创建分布式ID请求同时杀过来,服务器要顶的住且一下子成功创建,o万个分布式ID
以前的解决方案
UUID
1.无序,无法预测他的生成顺序,不能生成递增有序的数字。首先分布式id一般都会作为主键,但是安装mysql官方推荐主键要尽量越短越好,UUID每一个都很长,所以不是很推荐。
2.主键,ID作为主键时在特定的环境会存在一些问题。比如做DB主键的场景下,UUID就非常不适用MySQL官方有明确的建议主键要尽量越短越好36个字符长度的UUID不符合要求。
3.索引,B+树索引的分裂。既然分布式id是主键,然后主键是包含索引的,然后mysql的索引是通过b+树来实现的,每一次新的UUID数据的插入,为了查询的优化,都会对索引底层的b+树进行修改,因为儿UD数据是无序的,所以每一次UUID数据的插入都会对主键地城的b+树进行很大的修改,这一点很不好。插入完全无序,不但会导致一些中间节点产生分裂,也会白白创造出很多不饱和的节点,这样大大降低了数据库插入的性能。
数据库自增
实现原理:在分布式里面,数据库的自增ID机制的主要原理是:数据库自增ID和mysql数据库的replace into实现的。这里的replace into跟insert功能类似,不同点在于: replace into首先尝试插入数据列表中,如果发现表中已经有此行数据(根据主键或唯一索引判断)则先删除,再插入。否则直接插入新数据。REPLACE INTO的含义是插入一条记录,如果表中唯一索引的值遇到冲突,则替换老数据。

1:系统水平扩展比较困难,比如定义好了步长和机器台数之后,如果要添加机器该怎么做?假设现在只有一台机器发号是1.2,3.4.5(步长是1),这个时候需要扩容机器一台。可以这样做:把第工台机器的初始值设置得比第一台超过很多貌似还好,现在想象一下如果我们线上有100台机器,这个时候要扩容该怎么做?简直是噩梦。所以系统水平扩展方案复杂难以实现。
2∶数据库压力还是很大,每次获取ID都得读写一次数据库,非常影响性能,不符合分布式ID里面的延迟低和要高QPS的规则(在高并发下,如果都去数据库里面获取id,那是非常影响性能的
基于Redis生成全局id策略
单机环境下因为Redis低版本是单线的天生保证原子性,可以使用原子操作INCR和INCRBY来实现,所以也行。但是集群情况下,同样和MySQL一样需要设置不同的增长步长,但是部署与维护十分麻烦。
解决方案-Twitter的分布式自增ID算法SnowFlake
Twitter的分布式雪花算法 SnowFlake ,经测试snowflake每秒能够产生26万个自增可排序的ID
1、twitter的SnowFlake生成ID能够按照时间有序生成
2、SnowFlake算法生成id的结果是一个64bit大小的整数,为一个Long型(转换成字符串后长度最多19)。3、分布式系统内不会产生ID碰撞(由datacenter和workerld作区分)并且效率较高。
雪花算法的核心组件

号段解析:
1bit,
不用,因为二进制中最高位是符号位,1表示负数,0表示正数。生成的id一般都是用整数,所以最高位固定为0。
41bit-时间戳,用来记录时间戳,毫秒级。
41位可以表示2^{41}-1个数字,
如果只用来表示正整数(计算机中正数包含O),可以表示的数值范围是:0至2(41-1,减1是因为可表示的数值范围是从O开始算的,而不是1.-也就是说41位可以表示2*[41]-1个毫秒的值,转化成单位年则是(2^(41]-1)/(10006060*24 *365)=69年,所以雪花算法的使用时间是1970-2039年
10bit-工作机器id,用来记录工作机器id。
-可以部署在2{10]= 1024个节点,包括5位datacenterld和5位workerld
-5位(bit)可以表示的最大正整数是2"(5)}-1=31,即可以用0、1、2、3、.…1这32个数字,来表示不同的datecenterld或workerld
12bit-序列号,序列号,用来记录同毫秒内产生的不同id。
-12位.(bit)可以表示的最大正整数是2[12}-1= 4095,即可以用0、1、2、3、…4094这4095个数字,来表示同一机器同一时间截(毫秒)内产生的4095个ID序号。
结论:SnowFlake可以保证
所有生成的id按时间趋势递增
整个分布式系统内不会产生重复id(因为有datacenterld和workerld来做区分)
SnowFlake落地
源码的github地址在这里,由于他是scale实现的所以我们需要使用第三方的hutool工具包
pom中引入第三方依赖
<!--雪花算法,分布式ID-->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-captcha</artifactId>
<version>4.6.8</version>
</dependency>
封装IdGeneratorSnowFlake工具类
package com.atguigu.springcloud.alibaba.util;
import cn.hutool.core.lang.Snowflake;
import cn.hutool.core.net.NetUtil;
import cn.hutool.core.util.IdUtil;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
/**
* @description:
* @author: Czw
* @create: 2022-11-14 20:22
**/
@Component
public class IdGeneratorSnowFlake {
//机房,0-31
private long workerId = 10;
//机器,0-31
private long dataCenterId = 5;
private Snowflake snowflake = IdUtil.createSnowflake(workerId, dataCenterId);
@PostConstruct
public void init() {
try {
workerId = NetUtil.ipv4ToLong(NetUtil.getLocalhostStr());
System.out.println("当前机器的workId:" + workerId);
} catch (Exception e) {
e.printStackTrace();
System.out.println("当前机器的workId获取失败" + e);
workerId = NetUtil.getLocalhostStr().hashCode();
}
}
public synchronized long snowFlakeId(long workerId, long dataCenterId) {
Snowflake snowflake = IdUtil.createSnowflake(workerId, dataCenterId);
return snowflake.nextId();
}
public synchronized long snowFlakeId() {
return snowflake.nextId();
}
}
测试
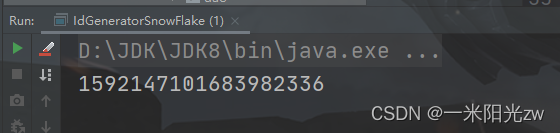
单机测试
public static void main(String[] args) {
//生成雪花算法
System.out.println(new IdGeneratorSnowFlake().snowFlakeId());
;
}
并发测试,编写接口
@Autowired
private IdGeneratorSnowFlake idGeneratorSnowflake;
/**
* 线程池生成多个雪花算法
*/
@RequestMapping("/snowFlakeId")
public CommonResult snowFlakeId() {
ExecutorService threadPool = Executors.newFixedThreadPool(5);
for (int i = 0; i < 50; i++) {
threadPool.submit(() -> {
System.out.println(idGeneratorSnowflake.snowFlakeId());
});
}
return new CommonResult(200, "生成成功");
}
测试访问
生成数据
1592146466838323200
1592146466838323202
1592146466838323201
1592146466838323204
1592146466838323203
1592146466838323208
1592146466838323209
1592146466838323207
1592146466838323206
1592146466838323205
1592146466842517505
1592146466842517507
1592146466842517508
1592146466842517509
1592146466842517510
1592146466842517511
1592146466842517512
1592146466842517513
1592146466842517514
1592146466842517515
1592146466842517516
1592146466842517517
1592146466842517518
1592146466842517519
1592146466842517504
1592146466838323211
1592146466842517522
1592146466842517523
1592146466842517524
1592146466842517525
1592146466842517526
1592146466842517527
1592146466842517528
1592146466842517529
1592146466842517530
1592146466842517531
1592146466838323210
1592146466842517532
1592146466842517521
1592146466842517535
1592146466842517536
1592146466842517537
1592146466842517538
1592146466842517539
1592146466842517520
1592146466842517506
1592146466846711808
1592146466842517540
1592146466842517534
1592146466842517533