视频局部区域移动检测, 删除相似帧
完整方案在本文最后, 不想听故事的直接跳转到完整方案即可
起因
老板的一个东西找不到了, 让查监控
场景
东西放在一个架子上, 由一个海康威视全天候录像的摄像头监控, 但是巧就巧在这个要找的东西被放在了摄像头的死角里, 正好被柜子的隔板给挡住了, 没办法通过对比的方法直接找出来移动痕迹.
于是只能导出从这个东西被放进去,到发现这个东西丢失的这段时间, 全部的录像资料(跨度近1个月, 共163G视频)
开始尝试
尝试一 观看所有移动事件
24*30个小时的视频不可能挨着看, 不过好在海康威视的NVR4.0有事件检测, 直接导出目标时间段内的所有移动事件检测视频(时长不好统计).
花了4个工作日, 将一个月的移动事件视频资料, 使用PotPlayer12倍速看完, 发现那东西放进去后根本就没人动过. 遂报告老板, 老板不信, 让再查一遍监控.
第二次观看移动事件视频时发现, 海康的移动检测有问题, 经常出现闪回(同一个片段重复两次)就算了, 还会出现移动事件丢失(直观感受就是人物明明还在画面中移动, 突然就消失了), 这让我失去了对海康移动事件检测的信任.
于是开始第二次尝试
尝试二 压缩原视频后观看
24*30个小时的视频,就算12倍速, 也得60个小时才能看完, 让我集中精力60小时看监控视频? 我选离职!
于是在网上搜索, 想找到一个视频相似帧删除的工具, 这样就能大大压缩视频时长并能保留下移动变化. 接着就在B站上找到一个宝藏UP, 写的这样一个工具: 侦测视频相似画面自动清除,抓取监控重点变化,批量生成浓缩视频, 使用这个工具, 光是压缩24*30个小时的视频, 就花掉了超过24小时的时间…原海康威视导出的1G大小, 时长在几个小时-十几小时不等的视频, 经过该工具压缩后, 时长缩短到十几分钟-一个小时不等, 时长被压缩了10倍以上
我用了5个工作日, 将这些压缩后的视频以12倍速全部看完, 仍然没有发现那东西被人拿走的痕迹, 遂又向老板报告, 老板说: “…算了吧”
老板算了, 我不能算
在使用宝藏UP主写的工具的时候, 我感受到了这个工具的不足之处:
- 相似度检测, 容易受到窗外树木, 地砖倒影变化的严重干扰
- 相似度检测, 会受到视频左上角时间水印的严重干扰
- 相似度检测, 会受到夜间噪点的严重干扰
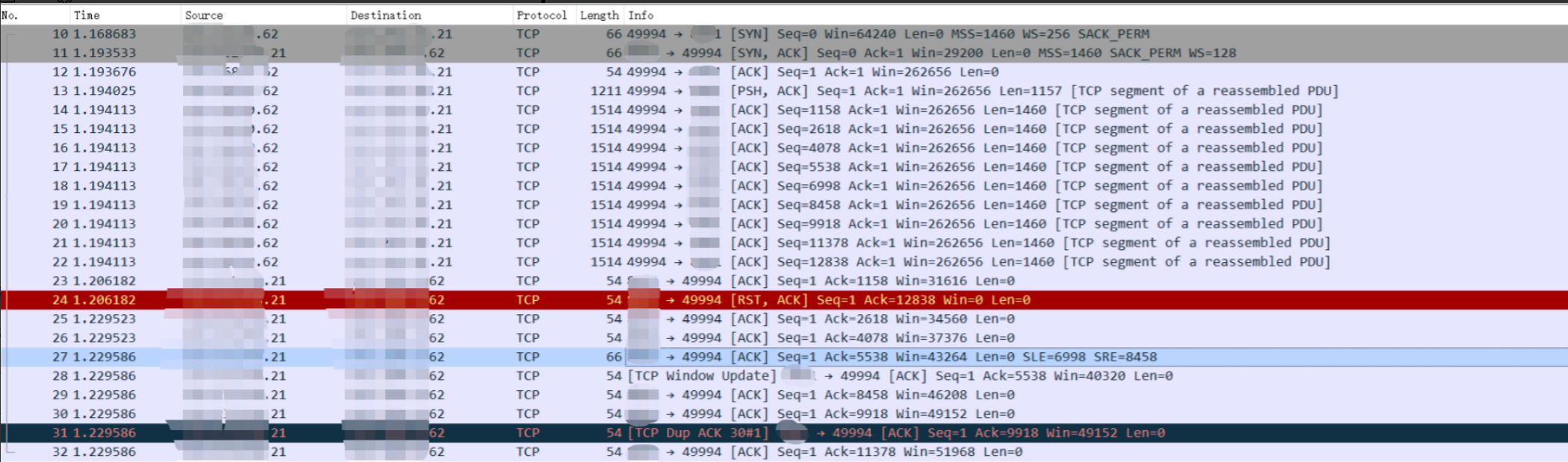
图中蓝色框内是需要重点观察移动变化的区域
两个黄色框内是对相似度检测造成严重干扰的区域(如果调整参数, 滤过这两部分的干扰, 那么相对的物体移动的帧也会被删除一部分, 使得结果不可靠)
于是, 我就想, 有没有一种可以对视频的局部区域内进行相似度检测压缩的方法

尝试三 ffmpeg mpdecimate 日志提取
由于宝藏up的工具是调用了ffmpeg这个传说中的库来做的, 于是我问AI(gpt3.5): ffmpeg能不能对视频的局部区域做相似帧删除?
经过一阵对线, AI最后给了我一句指令:
ffmpeg -i ./ceshi.mp4 -vf "crop=850:486:1070:0,mpdecimate=hi=64*120:lo=65*50:frac=0.33,setpts=N/FRAME_RATE/TB" ceshi3.mp4
该指令执行后, 会生成一个被相似度压缩后的视频, 但是有一点缺陷, 就是该视频的长宽只有crop剪裁的长宽(画幅只有蓝色框框那么大). 以至于物体的移动失去了时间这个参照物, 我看见它动了, 但不知道是什么时间点动的, 想要去原视频找出对应的一幕也很困难.
然后我又去和AI对线, 试试看ffmpeg能不能对视频的局部区域做相似帧检测, 然后在全局上删除相似帧. 最后直到AI向我抱歉…➡对线详情点击⬅
后来我突发奇想, mpdecimate的日志里,应该包含了被删除, 或者被保留的帧信息, 那么我可以提取这些帧信息, 在原视频上抽取这些帧, 组成新的视频, 就完美符合我的需求了. AI还真的给了我一个提取日志信息的方式:AI相关对话记录
ffmpeg -i ./ceshi.mp4 -vf 'crop=850:486:1070:0,mpdecimate=hi=64*120:lo=65*50:frac=0.33,showinfo' -f null - > mpdecimate_log.txt 2>&1
AI还向我解释了日志中, 各个参数的含义:
# ffmpeg mpdecimate 部分日志如下:
[Parsed_showinfo_2 @ 000002c311b40a00] n: 1 pts:2141190 pts_time:23.791 duration: 3600 duration_time:0.04 pos:
660900 fmt:yuvj420p sar:0/1 s:850x486 i:P iskey:0 type:P checksum:E7F119D0 plane_checksum:[CE36ADF8 B187A046 0BDFCB74
] mean:[128 117 133] stdev:[70.1 12.7 8.3]
[Parsed_showinfo_2 @ 000002c311b40a00] color_range:pc color_space:unknown color_primaries:unknown color_trc:unknown
[Parsed_showinfo_2 @ 000002c311b40a00] n: 2 pts:2148930 pts_time:23.877 duration: 3600 duration_time:0.04 pos:
662364 fmt:yuvj420p sar:0/1 s:850x486 i:P iskey:0 type:P checksum:4EF9DC25 plane_checksum:[74FE6EE1 4B23A19F 35F7CB96
] mean:[128 117 133] stdev:[70.1 12.7 8.3]
[Parsed_showinfo_2 @ 000002c311b40a00] color_range:pc color_space:unknown color_primaries:unknown color_trc:unknown
[Parsed_showinfo_2 @ 000002c311b40a00] n: 3 pts:2163510 pts_time:24.039 duration: 3600 duration_time:0.04 pos:
665464 fmt:yuvj420p sar:0/1 s:850x486 i:P iskey:1 type:I checksum:5F63E050 plane_checksum:[72CCB4CD 3A06A540 A6F28634
] mean:[127 117 133] stdev:[69.9 12.6 8.1]
# AI对各参数解释如下:
n: 帧的编号,表示该帧是原视频中的第49帧。 # 实际n代表的是该帧在新视频中的帧编号, 与原视频无关
pts: 帧的展示时间戳(Presentation Timestamp),在这个例子中,为352800。
pts_time: 帧的展示时间戳,以秒为单位,即3.92秒。 # 我的程序最终所使用的参数
duration: 帧的时长,即持续时间为3600。
duration_time: 帧的时长,以秒为单位,即0.04秒。
pos: 帧在输入文件中的位置,这里显示为947116。
fmt: 像素格式,这里为yuvj420p。
sar: 像素的采样比例,这里为0/1,表示未定义。
s: 视频帧的分辨率,这里为1920x1080。
i: 帧的类型,这里为P帧。
iskey: 帧是否为关键帧(keyframe),这里为0,表示不是关键帧。
type: 帧的类型,这里为P帧。
checksum: 帧的校验和,这里为EBA0BE0F。
plane_checksum: 平面校验和,表示帧的不同色彩通道的校验和。
mean: 帧的像素平均值,表示每个色彩通道的像素平均值为[117, 126, 129]。
stdev: 帧的像素标准差,表示每个色彩通道的像素标准差为[61.5, 8.7, 7.3]。
获取到了保留帧信息日志, 接下来问题就变为了如何在视频中提取指定帧, 于是, 针对日志中的各种参数, 开始了旷日持久的尝试…
尝试四 ffmpeg concat
使用ffmpeg concat 读取文件的功能, AI相关对话记录
# 指令如下:
ffmpeg -f concat -i timestamps.txt -c copy ceshi3.mp4
# AI给出的 timestamps.txt 文件内格式为:
file 'ceshi.mp4' # 文件地址
inpoint 3.437000 # 片段开始时间
outpoint 4.789000 # 片段结束时间
file 'ceshi.mp4'
inpoint 5.123456
outpoint 6.987654
...
测试结果:
- 输出视频会出现闪回的现象, 就是这个片段明明刚刚过了, 又来一遍(非常影响观看)
- 输出视频在无移动时(只是光线变化造成捕获), 会卡在某一帧不动, 然后移动到下一个卡顿处, 又卡住不动
猜测是指定时间时, 会往前回溯关键帧, 然后取持续时间的视频长度, 或者是指定的时间不连贯, 导致的频繁回溯
经统计, 需要捕获的帧里面各种类型数量对比: {‘I’: 1332, ‘P’: 32201}
经统计, 原视频关键帧分布较为均匀, 约24秒一个关键帧, 无论是否出现移动, 关键帧频率几乎不受影响
优化方案: 指定一个时间跨度, 将需要捕获的相邻两个帧的时间差 大于 跨度的帧丢弃, 小于 跨度的帧连接(取前一帧的头至后一帧的尾, 作为一个concat节点)
经测试发现: 更改时间跨度的值(具体为一帧时间长度的倍数), 可以缓解闪回和卡顿现象, 但是无法完全消除
尝试五 ffmpeg select=‘eq()’
使用 ffmpeg select= eq(pts,…)+eq(pts,…)进行抽帧, 相关AI对话记录
ffmpeg -i ./ceshi.mp4 -vf "select='eq(pts,2856816180)+eq(pts,2856848760)+eq(...',setpts=N/FRAME_RATE/TB" -y ceshi_15.mp4
这个方式对于视频帧数较少时, 非常适用, 压缩后的视频也没有问题
但是当视频时长达到: 9小时/40W帧, 需要保留其中7000+帧时
- win10 cmd 最大只支持8000+个字符的指令, 而且ffmpeg本身对指令长度也有限制. 一个包含7000帧的完整指令, 需要拆分成20+个小指令
- 我一度沉迷于把该指令的select参数写入文件中, 以绕过cmd的指令长度限制, 但均告失败, 相关AI对线实录1,相关AI对线实录2
- 当pts靠近视频前面时, 抽帧完会卡住(CPU保持100%运转), 程序无法结束
- 当pts靠近视频后面时, 一开始就会卡住(CPU保持100%运转), 无法开始抽帧
猜测是因为程序需要逐帧读取, 以到达指定的帧位置
至此, 只使用ffmpeg 的方式已经无法达到我想要的结果了…于是开始考虑使用其它软件来抽取视频中的指定帧,比如opencv
尝试六 opencv 逐帧读取, 比对帧号
# 日志文件内容如下:
[Parsed_showinfo_2 @ 000002c311b40a00] n: 1 pts:2141190 pts_time:23.791 duration: 3600 duration_time:0.04 pos:
660900 fmt:yuvj420p sar:0/1 s:850x486 i:P iskey:0 type:P checksum:E7F119D0 plane_checksum:[CE36ADF8 B187A046 0BDFCB74
] mean:[128 117 133] stdev:[70.1 12.7 8.3]
# 当duration恒定时, pts/duration的值就是该帧在原视频中的帧号
cap = cv2.VideoCapture(file_path)
fourcc = cv2.VideoWriter_fourcc('M', 'P', '4', '2') # 初始化视频写入器
fps = cap.get(cv2.CAP_PROP_FPS) # 帧率
out = cv2.VideoWriter('./ceshi3.avi', fourcc, fps, (int(cap.get(3)), int(cap.get(4)))) # 构建新视频
with open('./mpdecimate_log.txt', encoding='utf16') as f:
time_message = f.read() # 读取日志文件内容
n = -1
for item in re.finditer(r'n:.*?pts: *(?P<pts>\d+).*?duration: *(?P<duration>\d+)',time_message):
# 从ffmpeg mpdecimate 的日志中提取 pts 和 duration参数, 计算该帧处于原视频中的序号
pts = item.group('pts')
duration = item.group('duration')
frame_num = int(pts/duration)
while True:
n += 1
ret, frame = cap.read() # 逐帧读取
if not ret: break
if n < frame_num: # 未达到指定帧时, 读取下一帧
continue
out.write(frame)
break
测试发现逐帧读取非常耗时, 为了优化时间, 还测试了在多线程, 多进程下的时间对比
| 进程数 | 线程数 | 读取帧数 | 耗时 | CPU占用 |
|---|---|---|---|---|
| 1 | 1 | 10000 | 52秒 | 95 |
| 1 | 4 | 2500*4 | 49秒 | 95 |
| 3 | 3*1 | 3333*3 | 46秒 | 95 |
| 1 | 1*1 | 3333*1 | 20秒 | 53 |
| 2 | 2*1 | 3333*2 | 32秒 | 95 |
多进程也无法有效提高速度, 这种现象我无法解释, 只能归结于CPU瓶颈, CPU: i5 9300H
尝试七 opencv 跳帧读取, 比对帧号
不过好在opencv提供了一种快速跳过一帧,不做读取的方式:
cap.read() # 读取下一帧, 该方法实际由以下两个方法组成:
ret = cap.grab() # 跳转到下一帧
ret, frame = cap.retrieve() # 读取当前帧
那么只需要修改尝试六, while True:内部循环即可:
while True:
n += 1
ret = cap.grab() # 跳转到下一帧
if not ret: break
if n < frame_num: # 未达到指定帧时, 跳转到下一帧
continue
ret, frame = cap.retrieve() # 读取当前帧
out.write(frame)
break
这样测试时, 程序运行时间大大缩减了, 从40W帧中, 取出7000帧, 耗时大概10分钟
可是输出的视频却有问题, 有时画面中明明没有物体移动, 但是视频速度却按照正常时间流逝, 在应该有物体移动的时间段却被跳过了, 导致输出视频不可用
这个问题在原视频时长较短时, 感受不明显. 后来经过测试发现一个问题:
海康威视导出视频的总帧数, 用ffmpeg和opencv分别计算得出的值不一样, 相差5000+帧…差了几百秒
opencv 计算的总帧数, 符合 时长*帧率, 但是ffmpeg就会少一些…为此, 我拿电影文件做了测试, 对于电影文件, 二者给出的总帧数就是一样的, 符合时长*帧率…我只能说, 海康威视真的是个坑
因为这个原因, 导致帧号在ffmpeg与opencv之间无法完全对应, 视频越往后, 偏差越大
为了统一二者计算出的帧数, 我大声喊出AI救我!!! AI告诉我说有可能是由于原视频的部分帧损坏导致, 并给出了解决方式, 相关对话详情
# 该指令运行速度非常快, 40W帧9小时1G大小的视频, 几秒钟就可以完成
ffmpeg -ss 0 -i ./ceshi.mp4 -map 0:v:0 -c copy -y temp_video.mp4
# 对于生成的新视频temp_video.mp4, ffmpeg和opencv获取到的总帧数已经相同
于是我性高彩烈的开始新一轮测试, 结果却更加离谱, 通过temp_video.mp4压缩后的视频, 比之前的结果还要离谱
后来我从temp_video.mp4压缩日志中找到了答案:
# temp_video.mp4 部分压缩日志如下:
[Parsed_showinfo_2 @ 000001b0d6674480] n: 856 pts:2175890850 pts_time:24176.6 duration: 6930 duration_time:0.077 pos:389250636 fmt:yuvj420p sar:0/1 s:842x458 i:P iskey:0 type:P checksum:83F092C9 plane_checksum:[2AFE0FBE BA884DA4 FDAD3567] mean:[104 120 130] stdev:[68.8 10.6 6.8]
[Parsed_showinfo_2 @ 000001b0d6674480] color_range:pc color_space:unknown color_primaries:unknown color_trc:unknown
[Parsed_showinfo_2 @ 000001b0d6674480] n: 857 pts:2175897780 pts_time:24176.6 duration: 9000 duration_time:0.1 pos:389274303 fmt:yuvj420p sar:0/1 s:842x458 i:P iskey:0 type:P checksum:E2E29AB9 plane_checksum:[446A1E6A B8294192 A5863ABD] mean:[104 120 130] stdev:[68.8 10.6 6.9]
[Parsed_showinfo_2 @ 000001b0d6674480] color_range:pc color_space:unknown color_primaries:unknown color_trc:unknown
[Parsed_showinfo_2 @ 000001b0d6674480] n: 858 pts:2175906780 pts_time:24176.7 duration: 5940 duration_time:0.066 pos:389287958 fmt:yuvj420p sar:0/1 s:842x458 i:P iskey:0 type:P checksum:E3EAA589 plane_checksum:[839427C2 BC423E6D 9A273F5A] mean:[104 120 130] stdev:[68.7 10.7 6.9]
[Parsed_showinfo_2 @ 000001b0d6674480] color_range:pc color_space:unknown color_primaries:unknown color_trc:unknown
注意看 duration 和 duration_time, 他们都不一致了, 也就是说, 每一帧的持续时间不一样了, 我了个天坑呀…
比对帧号, 宣告失败
尝试八 opencv 跳帧读取, 比对时间
比对帧号失败, 那就比对时间试试: 提取日志中的 pts_time 数据
cap = cv2.VideoCapture(file_path)
fourcc = cv2.VideoWriter_fourcc('M', 'P', '4', '2') # 初始化视频写入器
fps = cap.get(cv2.CAP_PROP_FPS) # 帧率
out = cv2.VideoWriter('./ceshi3.avi', fourcc, fps, (int(cap.get(3)), int(cap.get(4)))) # 构建新视频
with open('./mpdecimate_log.txt', encoding='utf16') as f:
time_message = f.read() # 读取日志文件内容
for item in re.finditer(r'n:.*?pts_time: *(?P<pts_time>\d+(\.\d+)?)', time_message):
# 从ffmpeg mpdecimate 的日志中提取 pts_time 数据
pts_time_str = item.group('pts_time')
pts_time = int(float(pts_time_str) * 1000) # 毫秒
while True:
ret = cap.grab() # 跳转到下一帧
if not ret: break
if cap.get(cv2.CAP_PROP_POS_MSEC) < pts_time: # 未达到指定时间,跳转到下一帧
continue
ret, frame = cap.retrieve() # 读取当前帧
out.write(frame)
break
如此输出视频终于符合了我的需求, 只是整个程序耗时还不太理想, 一个40W帧, 9小时, 1G的原视频:
- 使用ffmpeg crop mpdecimate 生成压缩日志, 耗时近600秒
- 接着使用opencv 读取日志, 抽取指定帧写入(7000帧), 耗时600+秒
于是接下来将分别尝试对这两个步骤提速
尝试九 ffmpeg crop mpdecimate 启用GPU加速
经过尝试数据如下:
# CPU编解码, 40W帧 耗时: 576秒
ffmpeg -i ./ceshi.mp4 -vf 'crop=850:486:1070:0,mpdecimate=hi=64*120:lo=65*50:frac=0.33,showinfo' -f null - > mpdecimate_log.txt 2>&1
# CPU解码, GPU编码, 40W帧 耗时: 600秒
ffmpeg -i ./ceshi.mp4 -c:v h264_nvenc -vf 'crop=850:486:1070:0,mpdecimate=hi=64*120:lo=65*50:frac=0.33,showinfo' -f null - > mpdecimate_log.txt 2>&1
# GPU解码, GPU编码, 40W帧 耗时: 更慢....直奔1000秒去了
ffmpeg -c:v hevc_cuvid -i ./ceshi.mp4 -c:v h264_nvenc -vf 'crop=850:486:1070:0,mpdecimate=hi=64*120:lo=65*50:frac=0.33,showinfo' -f null - > mpdecimate_log.txt 2>&1
结论是, CPU是最快的…
猜测是因为mpdecimate只能用CPU去运算, 数据需要在GPU与CPU之间传递, 导致速度变慢
尝试十 opencv 跳转到指定时间读取帧
cap.set(cv2.CAP_PROP_POS_MSEC, pts_time) # 跳转到指定毫秒数, 比较耗时 ≈0.3秒
cap = cv2.VideoCapture(file_path)
fourcc = cv2.VideoWriter_fourcc('M', 'P', '4', '2') # 初始化视频写入器
fps = cap.get(cv2.CAP_PROP_FPS) # 帧率
out = cv2.VideoWriter('./ceshi3.avi', fourcc, fps, (int(cap.get(3)), int(cap.get(4)))) # 构建新视频
with open('./mpdecimate_log.txt', encoding='utf16') as f:
time_message = f.read() # 读取日志文件内容
pts_time_last = 0
for item in re.finditer(r'n:.*?pts_time: *(?P<pts_time>\d+(\.\d+)?)', time_message):
# 从ffmpeg mpdecimate 的日志中提取 pts_time 数据
pts_time_str = item.group('pts_time')
pts_time = int(float(pts_time_str) * 1000) # 毫秒
if (pts_time - pts_time_last) / 1000 * fps >= 270:
# 如果相邻两帧时间差值相距超过 270帧, 则直接跳转到该帧读取, 不再逐帧跳过
# 这个值是在CPU: i5 9300h 条件下测试得到
# 该条件下 cap.grab() 连续跳过270帧耗时与 cap.set(cv2.CAP_PROP_POS_MSEC, pts_time)相当, 0.3秒
cap.set(cv2.CAP_PROP_POS_MSEC, pts_time) # 跳转到指定毫秒数, 比较耗时 ≈0.3秒
ret, frame = cap.retrieve()
pts_time_last = pts_time
out.write(frame)
continue
while True:
ret = cap.grab() # 跳转到下一帧
if not ret: break
if cap.get(cv2.CAP_PROP_POS_MSEC) < pts_time: # 未达到指定时间,跳转到下一帧
continue
ret, frame = cap.retrieve() # 读取当前帧
pts_time_last = pts_time
out.write(frame)
break
此方案下, 使用opencv 读取日志, 抽取指定帧写入(7000帧), 耗时由600+秒, 缩减到135秒左右. 时间上已经基本符合需求
但是播放最终生成的视频发现, 会产生严重的灰屏界面, 就好像是帧损坏了一样.并且opencv会弹出一些报错信息: Could not find ref with POC XXX
然后发现该报错信息恰恰是因为跳转到指定时间cap.set(cv2.CAP_PROP_POS_MSEC, pts_time)之后导致的, 于是我又拿出电影文件进行测试, 发现没有报错, 输出视频也没有发生帧损坏现象. 看来问题还是出在海康威视的导出视频身上.
于是我又将尝试七里AI给出的修复指令拿出来试试, 先生成一个临时视频文件, 再对这个临时文件做日志提取与压缩
# 该指令运行速度非常快, 40W帧9小时1G大小的视频, 几秒钟就可以完成
ffmpeg -ss 0 -i ./ceshi.mp4 -map 0:v:0 -c copy -y temp_video.mp4
最终, 生成的视频已经符合需求
未开始的尝试
如果比对时间也搞不定的话, 会尝试比对帧的物理位置, 就是日志中的pos 数据, AI说它代表了帧在原视频中的物理位置, 为此还跟AI对线了一轮,发现AI一本正经胡说八道. 详情点击查看,
如果opencv无法按照物理地址跳转, 我会考虑使用二进制读取文件, 跳转到指定位置后, 手动判断一帧的数据
来时路
至此, 整个压缩方案大体完成, 从6.29-8.19号, 耗时近两个月时间, 期间代码写的断断续续, 方案一直在ffmpeg 与opencv之间来回摇摆, 好几次测试小视频的时候已经成功, 但是一测大的视频就会出现各种各样的问题, 那种由喜转悲的心态, 让我处于放弃的边缘. 好在这次没有任由自己放弃, 也谢谢自己这次没有放弃.
整个过程中, 我搜索了大量的问题, 查阅了部分ffmpeg的官方文档, 也频繁的向AI(gpt3.5)提问, 创建的会话有几十个, 上文中也展示了其中的一部分. AI的回答在此次的尝试中占据了至关重要的部分: mpdecimate日志的获取方式, concat 带时间的文件格式, 对海康视频损坏帧的修复指令, 这些都是我在普通搜索引擎里没有找到的答案.
在与AI的对话中, 每次我驳回了AI的回答时, AI都会先抱歉, 再接受我的建议, 继续回答问题, 就像是一个没有感情的机器. 但是我开启了几十个会话, 问了几十个问题, 却从来没有对AI说一句谢谢…AI会不会因为我不说谢谢, 而觉得我不礼貌呢?
以后可能会有的探索
魔改ffmpeg, 使下面的命令能够直接满足需求, 对感兴趣区域做相似度判断, 并对整个视频做相似帧删除
ffmpeg -i ceshi.mp4 -vf "addroi=1070:0:850:486,mpdecimate=hi=64*120:lo=65*50:frac=0.33,setpts=N/FRAME_RATE/TB" ceshi_result.mp4
完整方案
"""
环境:
python: 3.10
ffmpeg: 6.0-essentials_build
opencv: 4.8.0
CPU: i5 9300h
GPU: GTX 1050(3G) # 未使用
使用场景:
1.只想对感兴趣区域做相似度判断, 删除相似帧
2.对1产生的结果, 需要保留原视频完整的画面
使用场景限制:
1.感兴趣区域不宜过大,影响压缩日志生成速度, 区域越大,日志生成速度越慢
2.感兴趣区域不宜有经常变化的物体,影响抽帧的速度,变化越多,抽帧越慢. 例:不能把时间水印框入感兴趣区域, 不能把随风而动的东西框入感兴趣区域
3.以上两点, 需要同时满足, 否则请跳转到尝试二, 下载宝藏up主的工具, 效率更高
食用方式:
1.修改 mpdecimate_***开头的几个参数值, 以达到自己想要的效果, 建议用小视频测试参数值,速度快. 提示: hi和lo越大,删除的帧越多
2.修改 file_path 原视频文件路径
3.启动程序
"""
import os
import sys
import time
import re
import cv2
file_path = './test/ceshi.mp4' # 源文件地址
temp_file_path = '' # 一开始转码后的临时文件地址, 留空
global point1, point2, min_x, min_y, width, height # 在图像上画矩形框,所需的全局变量
mpdecimate_max = 0 # 官方默认 0
mpdecimate_keep = 0 # 官方默认 0 这个程序里该参数未启用, 启用会报错, 没细研究
mpdecimate_hi = 64*100 # 官方默认 64*12
mpdecimate_lo = 64*45 # 官方默认 64*5
mpdecimate_frac = 0.33 # 官方默认 0.33
log_encoding = 'utf8' # 日志编码格式
# skip_frame: 两次时间差值相距超过270帧, 则直接跳转到该帧操作, 不再逐帧跳过,
# skip_frame: 该值由i5 9300h CPU测试而来, 此CPU下cap.grab()连续跳过270帧耗时与cap.set(cv2.CAP_PROP_POS_MSEC, pts_time)耗时相当
skip_frame = 270
# 将原视频转码
def transcoding_video():
"""
将原视频快速转码, 以去除海康威视导出视频里的损坏帧, 防止抽帧时按照时间跳转出现灰屏
40W帧,耗时几秒钟
"""
global temp_file_path
temp_file_path = f'temp_video.{file_path.split(".")[-1]}'
os.system(f'ffmpeg -ss 0 -i {file_path} -map 0:v:0 -c copy -y {temp_file_path}')
time.sleep(1) # 加上一个睡眠时间, 否则下一步的画矩形框可能无法弹窗
# 鼠标响应函数(opencv画矩形框,并获取左上角的坐标与长宽)
def _rectangular_box(event, x, y, flags, param):
"""
鼠标响应函数(opencv画矩形框,并获取左上角的坐标与长宽)
:param event: 鼠标事件
:param x: 坐标
:param y: 坐标
:param flags:
:param param: 传递进来的参数(这里传入的是视频的第一帧)
:return:
"""
global point1, point2, min_x, min_y, width, height
img = param.copy()
if event == cv2.EVENT_LBUTTONDOWN: # 左键点击
point1 = (x, y)
cv2.circle(img, point1, 10, (0, 255, 0), 5)
cv2.imshow('image', img)
elif event == cv2.EVENT_MOUSEMOVE and (flags & cv2.EVENT_FLAG_LBUTTON): # 按住左键拖曳
cv2.rectangle(img, point1, (x, y), (255, 0, 0), 5)
cv2.imshow('image', img)
elif event == cv2.EVENT_LBUTTONUP: # 左键释放
point2 = (x, y)
cv2.rectangle(img, point1, point2, (0, 255, 255), 4)
cv2.imshow('image', img)
min_x = min(point1[0], point2[0])
min_y = min(point1[1], point2[1])
width = abs(point1[0] - point2[0])
height = abs(point1[1] - point2[1])
# opencv画矩形框,并获取左上角的坐标与长宽
def get_rectangle_point():
"""
opencv画矩形框,并获取左上角的坐标与长宽
:return: 矩形框 左上角的坐标, 和长宽
"""
cap_temp = cv2.VideoCapture(file_path)
if not cap_temp.isOpened():
print("无法打开视频文件。请检查文件路径。")
exit()
ret, frame = cap_temp.read() # 读取第一帧
cv2.namedWindow('image', 0)
cv2.resizeWindow('image', 1920, 1080) # 设置窗口大小, 否则显示不完全, 不方便画框
cv2.setMouseCallback('image', _rectangular_box, frame) # 设置鼠标回调函数
cv2.imshow('image', frame)
cv2.waitKey(0) # 按任意键退出矩形选择
cap_temp.release() # 回收资源
cv2.destroyWindow('image') # 关闭窗口
return min_x, min_y, width, height
# 生成视频压缩日志文件
def crate_mpdecimate_log():
"""
先剪切, 再计算相似度, 将需要保留的帧信息, 写入日志文件(剪切面积越大, 执行速度越慢, 剪切的过程相当于一次转码)
如果拥有高端显卡, 可以尝试将下面的指令拆分为两部分执行, 先crop生成一个新视频, 再对新视频mpdecimate提取日志, 总耗时可能会减少
"""
# CPU编解码, 40W帧 耗时: 576秒
instruct = f"ffmpeg -i {temp_file_path} -vf crop={width}:{height}:{min_x}:{min_y}," \
f"mpdecimate=max={mpdecimate_max}:hi={mpdecimate_hi}:lo={mpdecimate_lo}:frac={mpdecimate_frac}," \
f"showinfo -f null - > mpdecimate_log.txt 2>&1"
print(instruct)
print('压缩日志生成中, 请等待, 该过程没有进度条展示并且有较高CPU占用, 请耐心等待')
os.system(instruct)
# 读取需要保留的帧的时间信息
def read_time_message():
try:
with open('./mpdecimate_log.txt', encoding=log_encoding) as f:
time_message = f.read()
except UnicodeError:
print(f'日志格式编码错误, {log_encoding} 无法读取日志文件')
exit()
for item in re.finditer(r'n:.*?pts_time: *(?P<pts_time>\d+(\.\d+)?)', time_message):
yield item.group('pts_time')
# 视频时间维度压缩
def video_time_compress():
cap = cv2.VideoCapture(temp_file_path)
if not cap.isOpened():
print("无法打开视频文件。请检查文件路径。")
exit()
fourcc = cv2.VideoWriter_fourcc('M', 'P', '4', '2') # 初始化视频写入器
fps = cap.get(cv2.CAP_PROP_FPS) # 帧率
cv_total_fps = cap.get(7) # 总帧数
cv_total_msec = int(cv_total_fps / fps * 1000) # 总时长, 秒
print(f'原视频总帧数:{cv_total_fps}, 帧率:{fps}, 总时长:{cv_total_msec / 1000}')
new_name = file_path.split('/')[-1].split('.')[0] + '_compress.avi' # 输出视频名称
try: # 输出目录
os.mkdir('compress_file')
except FileExistsError:
pass
out = cv2.VideoWriter(f'./compress_file/{new_name}', fourcc, fps, (int(cap.get(3)), int(cap.get(4))))
for frame in extraction_frame(cap, cv_total_msec, fps):
out.write(frame)
cap.release()
out.release()
# 抽帧
def extraction_frame(cap, cv_total_msec, fps):
"""
视频抽取指定时间的所有帧
:param cap: 视频
:param cv_total_msec: 总时长(毫秒)
:param fps: 帧率
:return: 被抽取的每一帧
"""
pts_time_last = 0
for pts_time_str in read_time_message():
pts_time = int(float(pts_time_str) * 1000) # 毫秒
# 如果相邻两帧时间差值相距超过 skip_frame 数量的帧, 则直接跳转到该帧操作, 不再逐帧跳过
if (pts_time - pts_time_last) / 1000 * fps >= skip_frame:
cap.set(cv2.CAP_PROP_POS_MSEC, pts_time) # 跳转到指定毫秒数, 比较耗时 ≈0.3秒
ret, frame = cap.retrieve()
pts_time_last = pts_time
sys.stdout.write(f"\r 进度:{round(pts_time / cv_total_msec * 100, 2)}")
sys.stdout.flush()
yield frame
continue
while True:
ret = cap.grab() # 逐帧跳过
if not ret: break
if cap.get(cv2.CAP_PROP_POS_MSEC) < pts_time: continue # 逐帧跳过
ret, frame = cap.retrieve()
pts_time_last = pts_time
# print(round(pts_time / cv_total_msec * 100, 2))
sys.stdout.write(f"\r 进度:{round(pts_time / cv_total_msec * 100, 2)}")
sys.stdout.flush()
yield frame
break
def main():
transcoding_video()
get_rectangle_point()
print('剪切坐标', min_x, min_y, width, height)
begin = time.time()
crate_mpdecimate_log()
end = time.time()
print('临时日志文件已生成')
print(f'生成日志耗时: {end - begin}')
begin = time.time()
video_time_compress()
end = time.time()
print(f'压缩耗时: {end - begin}') # 逐帧跳过压缩(总共40W帧,读取7300帧)耗时657秒 # 按时间节点跳帧压缩(读取7300帧)耗时: 129秒
if __name__ == '__main__':
main()
欢迎关注作者微信公众号: 小玉的小本本