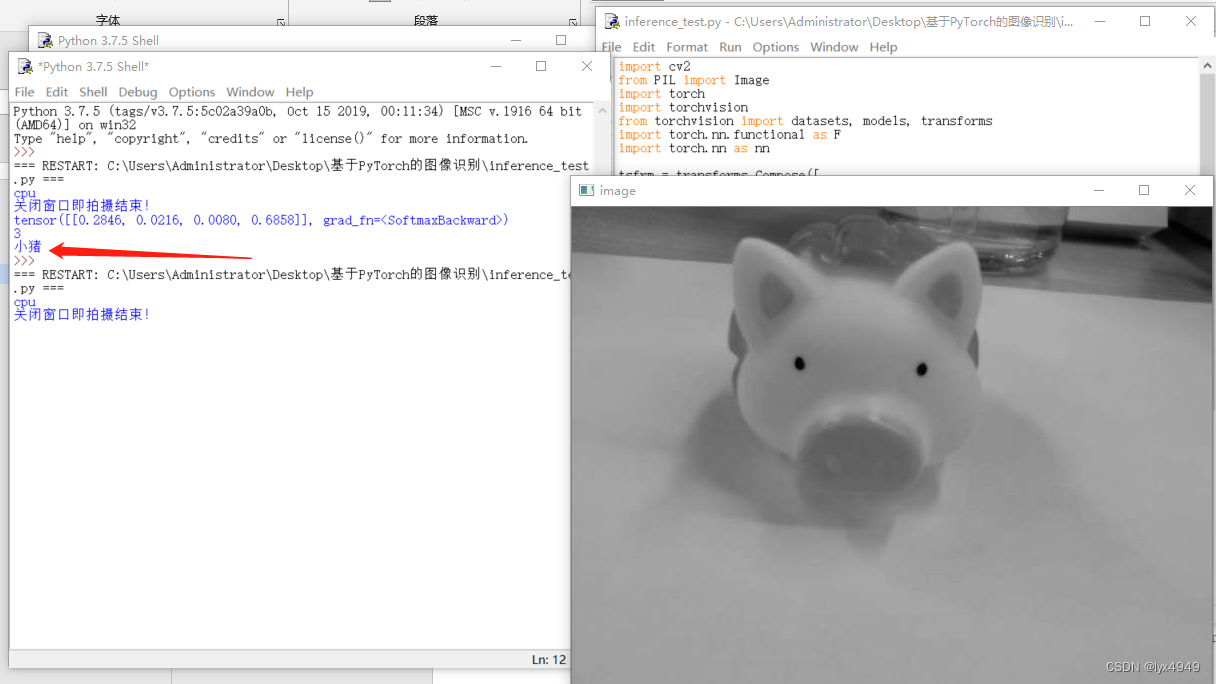
数据拉链任务
拉链任务是一种常见的数据追踪和历史记录技术,在ETL中也有广泛应用。拉链任务通过类似“版本控制”的方式,记录不同时间点的数据变化情况,可用于数据分析、报表输出、增量导出等场景。
在ETL中,拉链任务通常包含以下步骤:
拉链表设计:设计一个拉链表,记录需要追踪历史变化的主题表的关键字段、时间戳等信息。
抽取当前数据:使用ETL工具或手动方式抽取当前主题表中的所有数据,并插入到拉链表中,记录初始版本号。
定期增量抽取:以一定的频率,比如每天或每周,抽取主题表中新增或变化的数据,并通过比较前后版本的方式来更新拉链表。
处理过期数据:对于拉链表中已经过期的数据,需要进行处理,通常是标记为已失效或删除。
通过拉链任务,可以方便地追踪和分析数据变化的情况,同时也可以规范数据处理流程,提高数据质量和可信度。
On the other hand
The concept of a “Zipper Task” in the context of ETL (Extract, Transform, Load) refers to a common technique used for data tracking and historical record-keeping. It is often applied in ETL processes to capture and track changes in data over time.
In a zipper task, a “zipper table” is designed to record the key fields, timestamps, and other relevant information from the source table that needs to be tracked for historical changes. The zipper table acts as a version control mechanism to store the data at different time points.
The process of a zipper task typically involves the following steps:
- Zipper Table Design: Designing a zipper table with the necessary fields to capture the historical changes in the source table.
- Initial Data Extraction: Initially extracting all the data from the source table and inserting it into the zipper table, assigning an initial version number.
- Periodic Incremental Extraction: Extracting incremental changes from the source table at regular intervals, such as daily or weekly, and updating the zipper table by comparing the previous version with the current version.
- Handling Expired Data: Managing expired data in the zipper table, typically by marking it as inactive or deleting it.
By implementing zipper tasks, it becomes easier to track and analyze the changes in data over time. It also helps standardize data processing workflows, leading to improved data quality and reliability.