文章目录
- 稀疏训练VGGNet
- 剪枝
- 导入库文件
- 测试函数
- 定义全局参数
- BN通道排序
- 制作Mask
- 剪枝操作
- 微调
- 微调方法
- 微调结果
稀疏训练VGGNet
新建train_sp.py脚本。稀疏化训练的过程和正常训练类似,不同的是在BN层中各权重加入稀疏因子,代码如下:
def updateBN(model,s=0.0001,epoch=1,epochs=1000):
srtmp = s * (1 - 0.9 * epoch / epochs)
for m in model.modules():
if isinstance(m,nn.BatchNorm2d):
m.weight.grad.data.add_(srtmp*torch.sign(m.weight.data))
m.bias.grad.data.add_(s * 10 * torch.sign(m.bias.data))
加入到train函数中,如图:
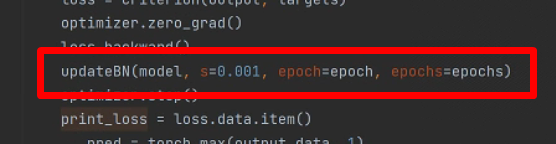
s的设置需要根据数据集调整,可以通过观察tensorboard的map,gamma变化直方图等选择。我在本次训练种使用的是0.001.
训练完成后,就可以使用tensorboard观察训练结果,在根目录运行:
tensorboard --logdir .
然后看到如下信息:
TensorFlow installation not found - running with reduced feature set.
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all
TensorBoard 2.13.0 at http://localhost:6006/ (Press CTRL+C to quit)
在浏览器中打开http://localhost:6006/就能看到。
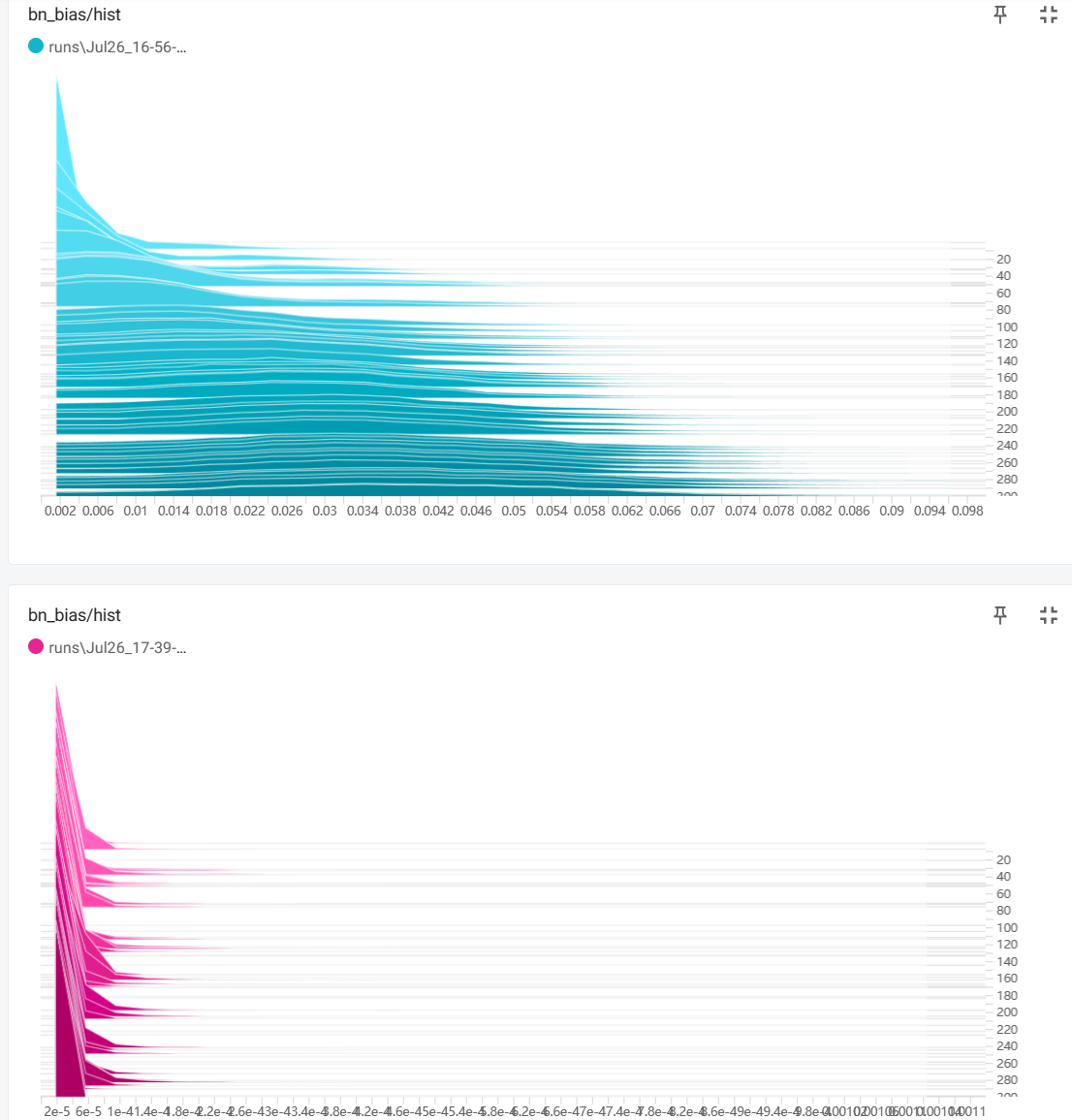
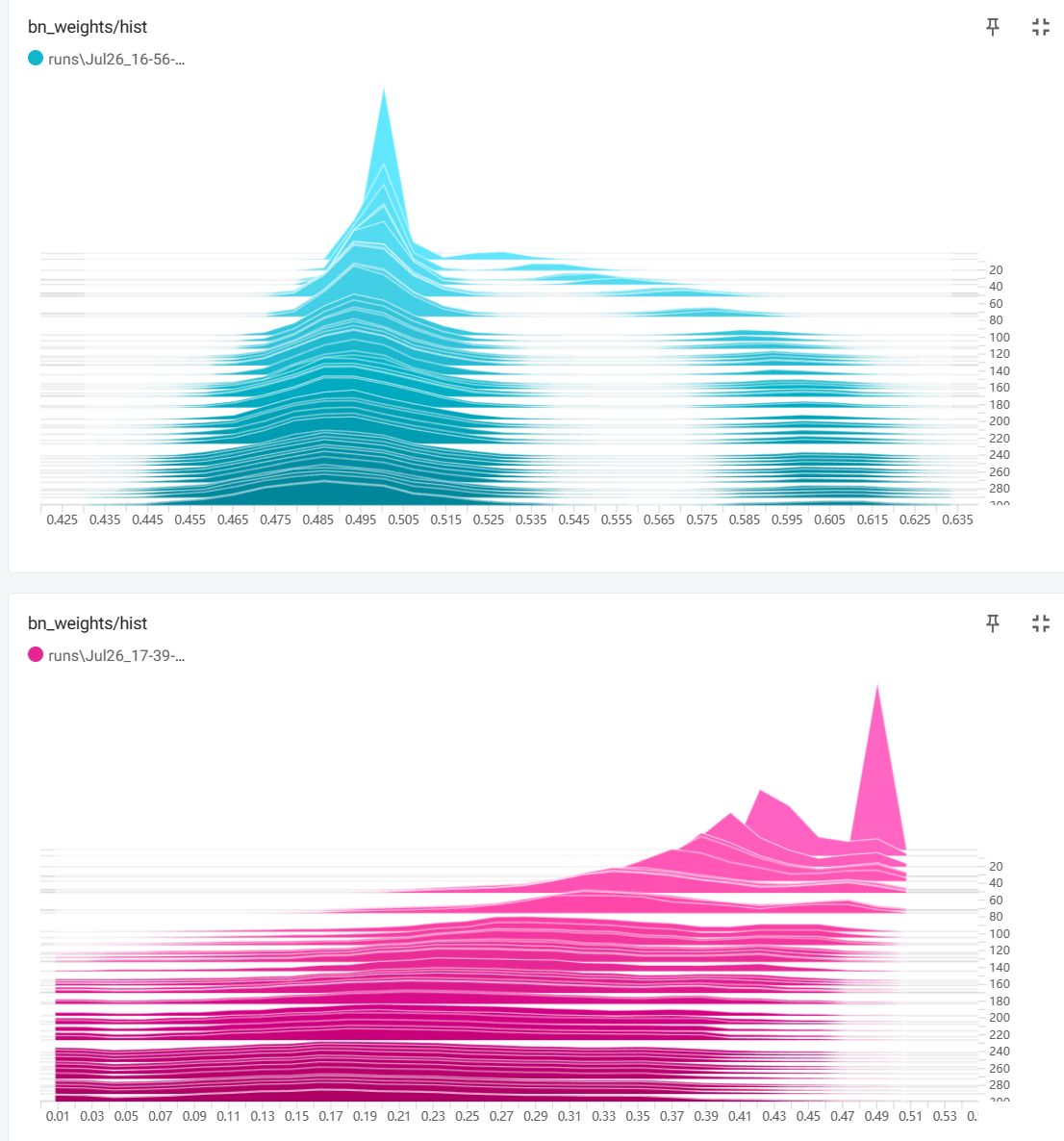
蓝色的是正常训练,BN权重的分布情况。紫红色的是加入稀疏因子后BN权重的分布情况。
稀疏化训练结果:


结果基本上和正常训练一致!最终结果也是95.6%。
剪枝
新建prune.py脚本,这个脚本是剪枝脚本。
导入库文件
import os
import argparse
import torch
import torch.nn as nn
from torch.autograd import Variable
from torchvision import datasets, transforms
from vgg import VGG
import numpy as np
测试函数
测试函数,用来测试剪枝后的模型ACC,代码如下:
# simple test model after Pre-processing prune (simple set BN scales to zeros)
def test():
# 读取数据
transform_test = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.48214436, 0.42969334, 0.33318862], std=[0.2642221, 0.23746745, 0.21696019])
])
dataset_test = datasets.ImageFolder("data/val", transform=transform_test)
test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, pin_memory=True, shuffle=False)
model.eval()
correct = 0
for data, target in test_loader:
data, target = data.to(DEVICE), target.to(DEVICE)
data, target = Variable(data, volatile=True), Variable(target)
output = model(data)
pred = output.data.max(1, keepdim=True)[1] # get the index of the max log-probability
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
print('\nTest set: Accuracy: {}/{} ({:.1f}%)\n'.format(
correct, len(test_loader.dataset), 100. * correct / len(test_loader.dataset)))
return correct / float(len(test_loader.dataset))
定义全局参数
if __name__ == '__main__':
BATCH_SIZE=16
percent=0.7
DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model_path='checkpoints/vgg_sp/best.pth'
save_name='pruned.pth'
BATCH_SIZE:测试函数的BatchSize。
percent:剪枝的比率。
DEVICE :如果有显卡则使用GPU,没有则使用cpu。
model_path:稀疏训练模型的路径。
save_name:剪枝后,模型的路径。
BN通道排序
#加载稀疏训练的模型
model = torch.load(model_path)
print(model)
total = 0 # 统计所有BN层的参数量
for m in model.modules():
if isinstance(m, nn.BatchNorm2d):
total += m.weight.data.shape[0] # 每个BN层权重w参数量
bn = torch.zeros(total)
index = 0
for m in model.modules():
#将各个BN层的参数值复制到bn中
if isinstance(m, nn.BatchNorm2d):
size = m.weight.data.shape[0]
bn[index:(index + size)] = m.weight.data.abs().clone()
index += size
#对bn中的weight值排序
y, i = torch.sort(bn)#
thre_index = int(total * percent)
thre = y[thre_index]#取bn排序后的第thresh_index索引值为bn权重的截断阈值
制作Mask
pruned = 0 #统计BN层剪枝通道数
cfg = []#统计保存通道数
cfg_mask = []#BN层权重矩阵,剪枝的通道记为0,未剪枝通道记为1
for k, m in enumerate(model.modules()):
if isinstance(m, nn.BatchNorm2d):
weight_copy = m.weight.data.clone()
mask = weight_copy.abs().gt(thre).float().cuda()#阈值分离权重
pruned = pruned + mask.shape[0] - torch.sum(mask)
m.weight.data.mul_(mask)#更新BN层的权重,剪枝通道的权重值为0
m.bias.data.mul_(mask)
cfg.append(int(torch.sum(mask)))#记录未被剪枝的通道数量
cfg_mask.append(mask.clone())
print('layer index: {:d} \t total channel: {:d} \t remaining channel: {:d}'.
format(k, mask.shape[0], int(torch.sum(mask))))
elif isinstance(m, nn.MaxPool2d):
cfg.append('M')
pruned_ratio = pruned / total
print('Pre-processing Successful!')
test()
# Make real prune
print(cfg)
剪枝操作
newmodel = VGG(cfg=cfg,num_classes=12)
newmodel.cuda()
layer_id_in_cfg = 0
start_mask = torch.ones(3)
end_mask = cfg_mask[layer_id_in_cfg]
for [m0, m1] in zip(model.modules(), newmodel.modules()):
if isinstance(m0, nn.BatchNorm2d):
idx1 = np.squeeze(np.argwhere(np.asarray(end_mask.cpu().numpy())))
m1.weight.data = m0.weight.data[idx1].clone()
m1.bias.data = m0.bias.data[idx1].clone()
m1.running_mean = m0.running_mean[idx1].clone()
m1.running_var = m0.running_var[idx1].clone()
layer_id_in_cfg += 1
start_mask = end_mask.clone()
if layer_id_in_cfg < len(cfg_mask): # do not change in Final FC
end_mask = cfg_mask[layer_id_in_cfg]
elif isinstance(m0, nn.Conv2d):
idx0 = np.squeeze(np.argwhere(np.asarray(start_mask.cpu().numpy())))
idx1 = np.squeeze(np.argwhere(np.asarray(end_mask.cpu().numpy())))
print('In shape: {:d} Out shape:{:d}'.format(idx0.shape[0], idx1.shape[0]))
w = m0.weight.data[:, idx0, :, :].clone()
w = w[idx1, :, :, :].clone()
m1.weight.data = w.clone()
# m1.bias.data = m0.bias.data[idx1].clone()
elif isinstance(m0, nn.Linear):
idx0 = np.squeeze(np.argwhere(np.asarray(start_mask.cpu().numpy())))
m1.weight.data = m0.weight.data[:, idx0].clone()
torch.save({'cfg': cfg, 'state_dict': newmodel.state_dict()}, save_name)
print(newmodel)
model = newmodel
test()
剪枝后保存模型
微调
微调方法
微调方法和正常训练类似,加载剪枝后的模型和配置,然后训练、验证即可!
if __name__ == '__main__':
# 创建保存模型的文件夹
file_dir = 'checkpoints/vgg_pruned'
if os.path.exists(file_dir):
print('true')
os.makedirs(file_dir, exist_ok=True)
else:
os.makedirs(file_dir)
# 设置全局参数
model_lr = 1e-4
BATCH_SIZE = 16
EPOCHS = 300
DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
classes = 12
resume = 'pruned.pth'
# 设置模型
model = torch.load(resume)
model_ft=VGG(cfg=model['cfg'],num_classes=classes)
model_ft.load_state_dict(model['state_dict'])
model_ft.to(DEVICE)
print(model_ft)
微调结果
Val set: Average loss: 0.2845, Accuracy: 457/482 (95%)
precision recall f1-score support
Black-grass 0.79 0.86 0.83 36
Charlock 1.00 1.00 1.00 42
Cleavers 1.00 0.96 0.98 50
Common Chickweed 0.94 0.91 0.93 34
Common wheat 0.93 1.00 0.97 42
Fat Hen 0.97 0.97 0.97 34
Loose Silky-bent 0.88 0.78 0.83 46
Maize 0.96 1.00 0.98 45
Scentless Mayweed 0.93 0.96 0.95 45
Shepherds Purse 0.97 0.97 0.97 35
Small-flowered Cranesbill 1.00 0.97 0.99 36
Sugar beet 1.00 1.00 1.00 37
accuracy 0.95 482
macro avg 0.95 0.95 0.95 482
weighted avg 0.95 0.95 0.95 482