App Search 是 Elastic Enterprise Search 的一部分,Elastic Enterprise Search 是由 Elasticsearch 提供支持的内容搜索工具集合。
最初由 App Search 引入的一些功能(例如网络爬虫)现在可以直接通过企业搜索使用。 将这些功能与其他企业搜索工具(例如连接器和搜索 UI 库)相结合。
在今天的文章中,我来详述如何为 App search 写入数据。如果你想把数据库里的数据写入到 App search 中,你可以参考我之前的文章 “Enterprise:如何使用 Python 客户端将数据提取到 App Search 中”。
安装
首先,我们按照文章 “Enterprise:使用 MySQL connector 同步 MySQL 数据到 Elasticsearch” 里所介绍的方法来安装 Elastic Enterprise App search。这里就不再累述了。
准备数据
我们可以在网上链接 TMDB movies and series | Kaggle 下载到 TMDB 的数据。它含有 526,000 个电影及超过 93,000 个 TV 连续剧。我们点击网页上的 Download 按钮:
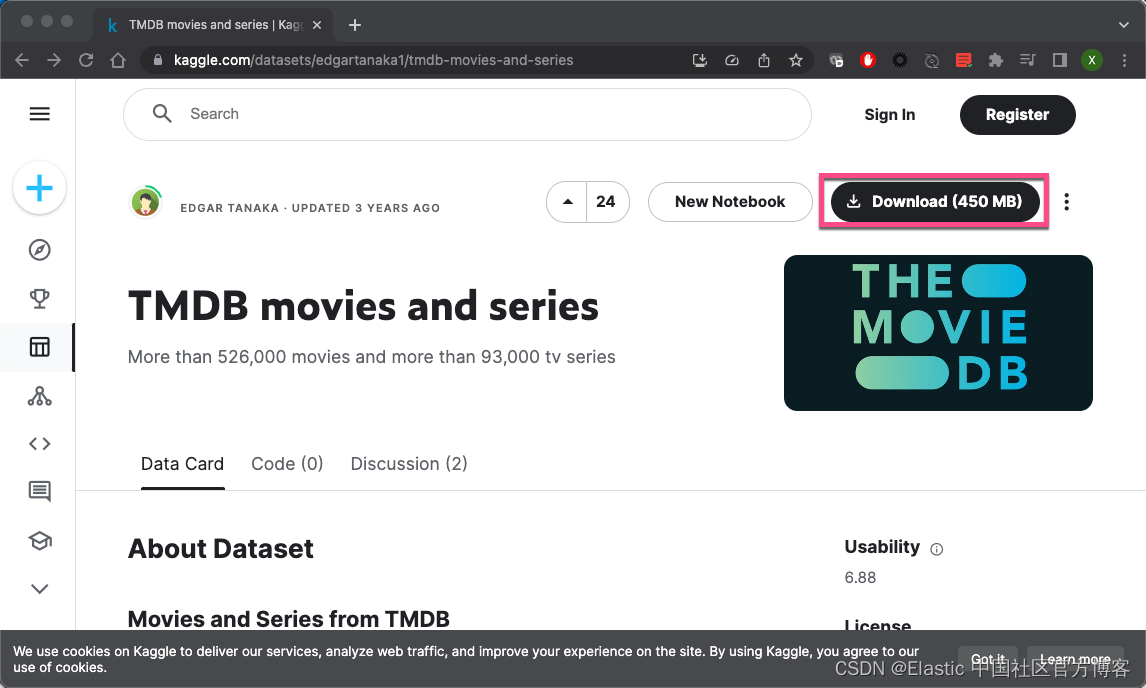
我们可以使用如下的命令来进行加压缩:
$ pwd
/Users/liuxg/data/movies_tmdb
$ ls
archive.zip
$ unzip archive.zip 我们打开 Kibana 界面:
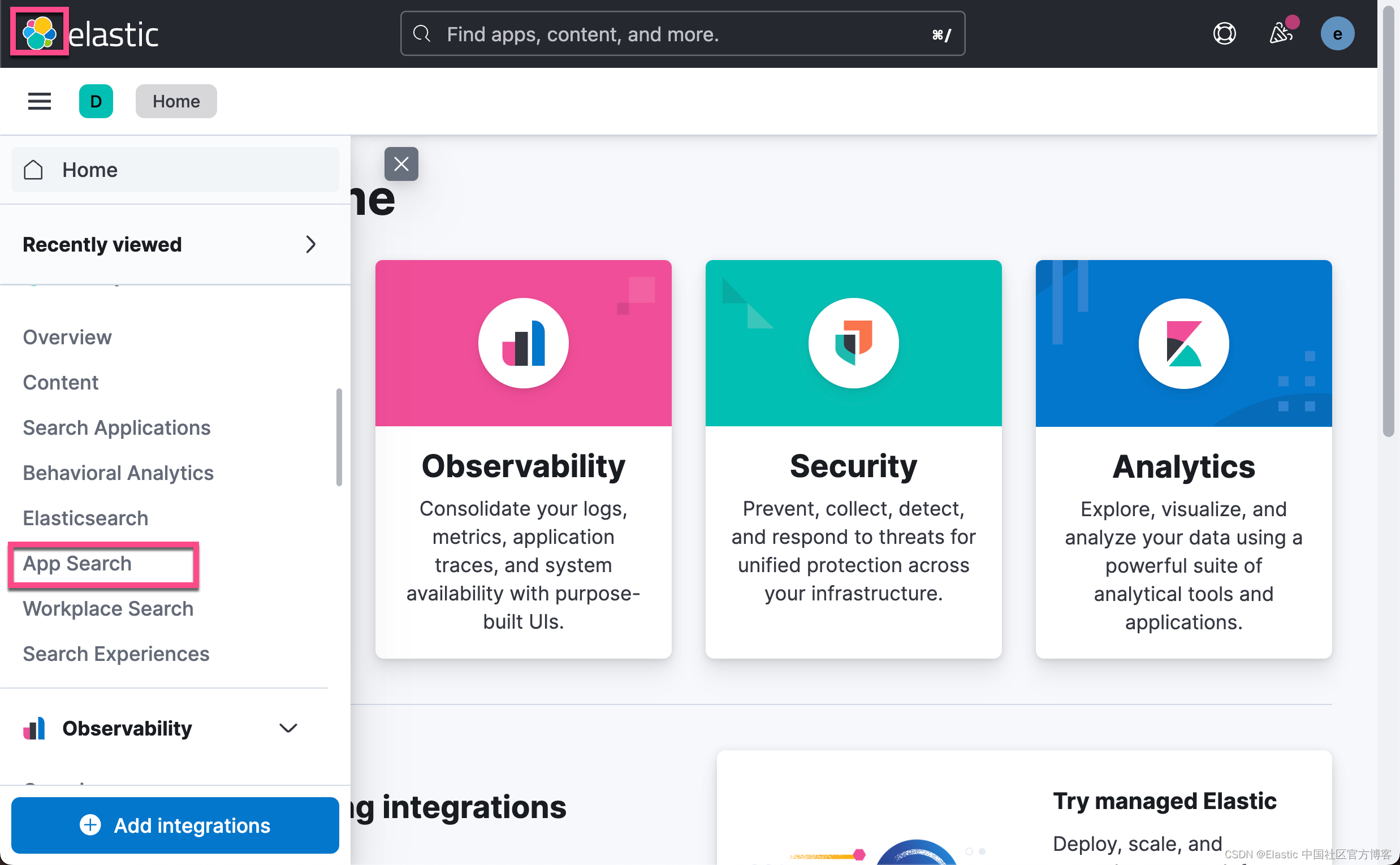
在上面,我们选择 App Search managed docs。

如上所示,目前它提供了三种方法来摄入文件。有关 Crawler 的文章,在我之前的有很多文章都已经做过介绍:
- Enterprise:Web Crawler 基础 (一)(二)
-
ChatGPT 和 Elasticsearch:OpenAI 遇见私有数据(二)
在这里,我们就不做介绍了。如果你对这个话题感兴趣,请详细阅读上面的文章以了解更多。
在上面,我们选择 Paste or upload JSON:
我们接下来选择刚才解压其中的一个文档:
我们可以看到已经有一个文档被摄入。
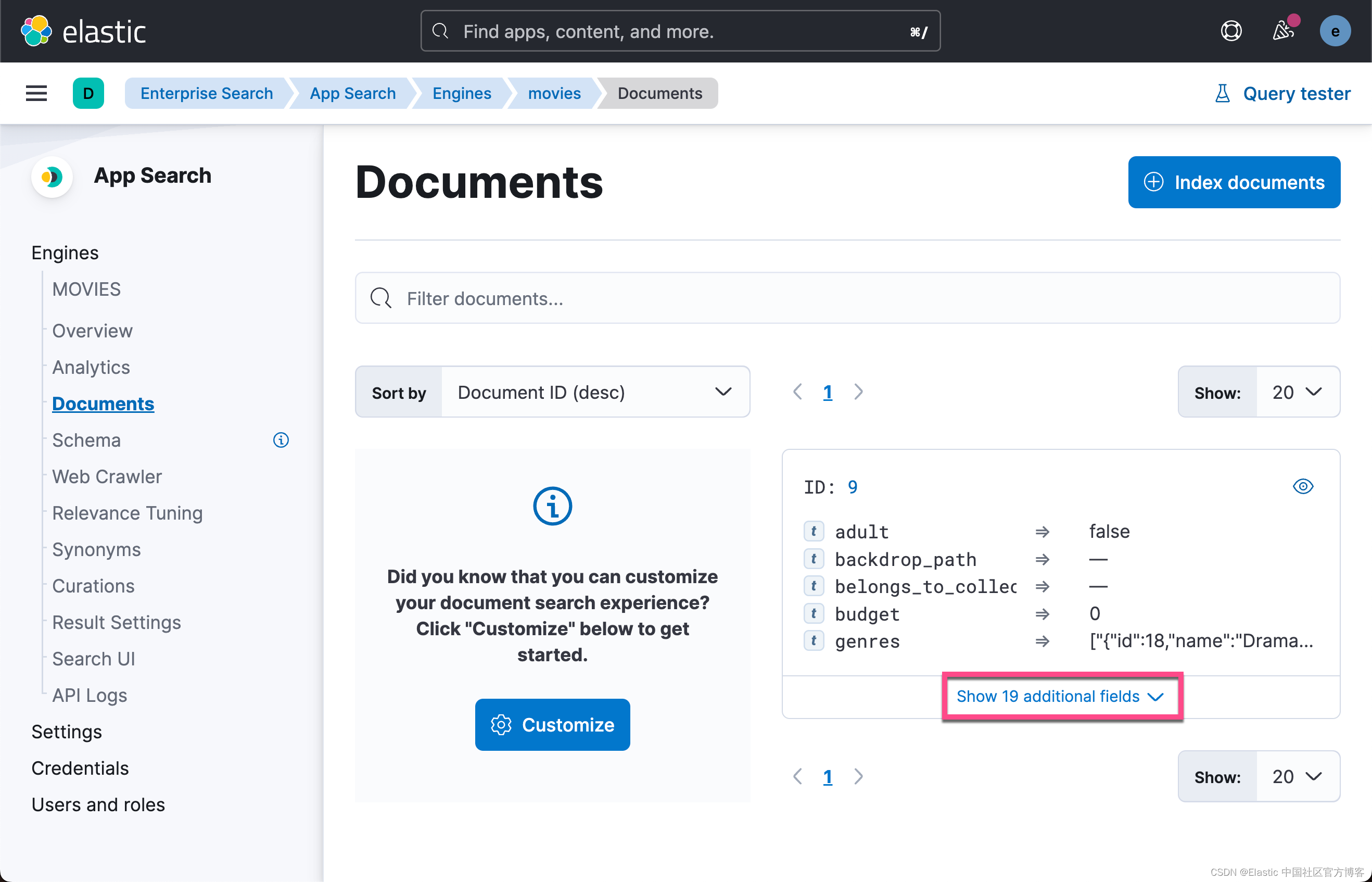
点击上面的 Documents,我们可以查看被摄入的文档:
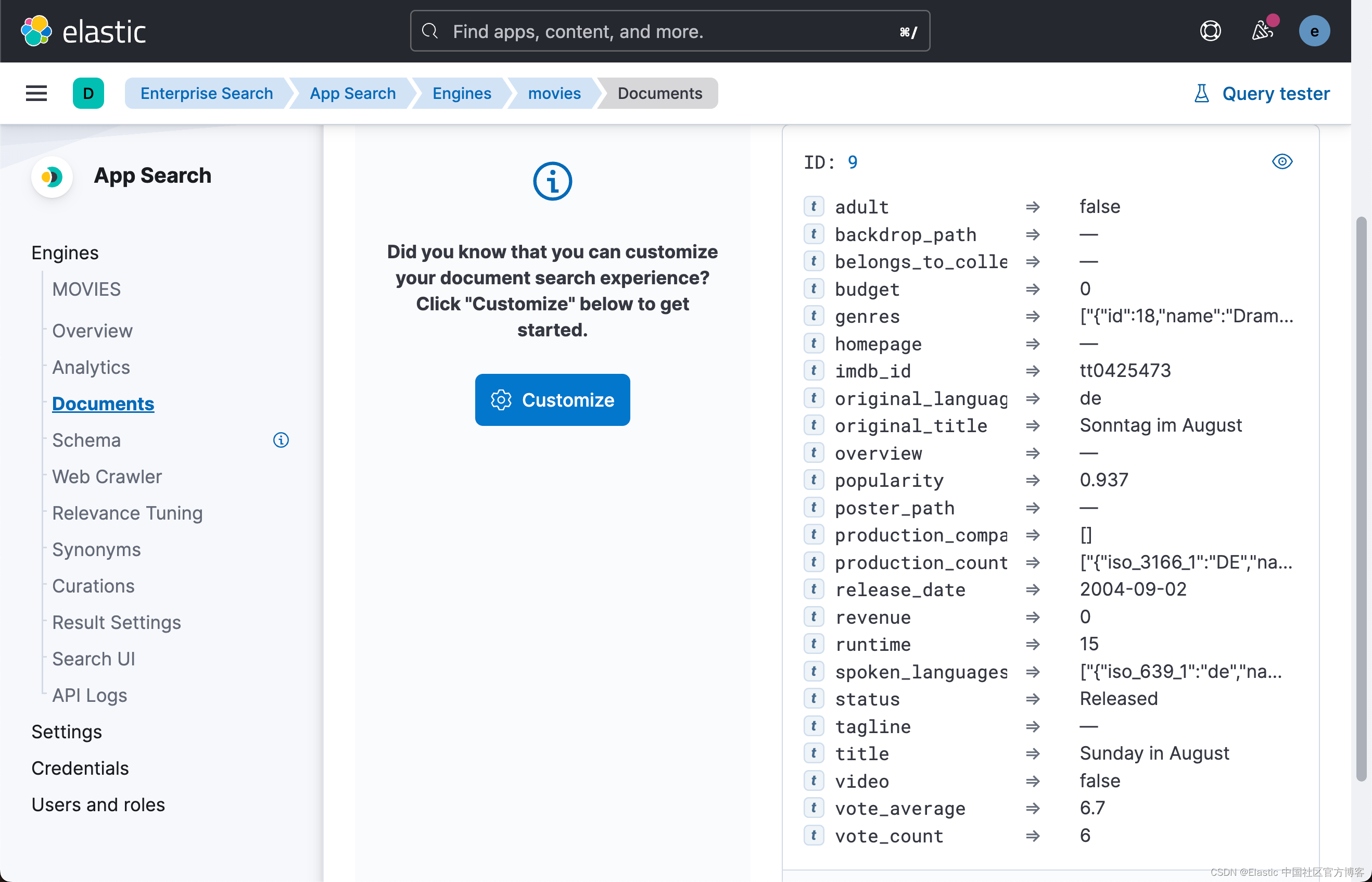

在默认的情况下,所有的字段的类型都是设置为 text 类型。这显然不是我们所期望的。我们可以通过上面的界面来修改字段的数据类型:
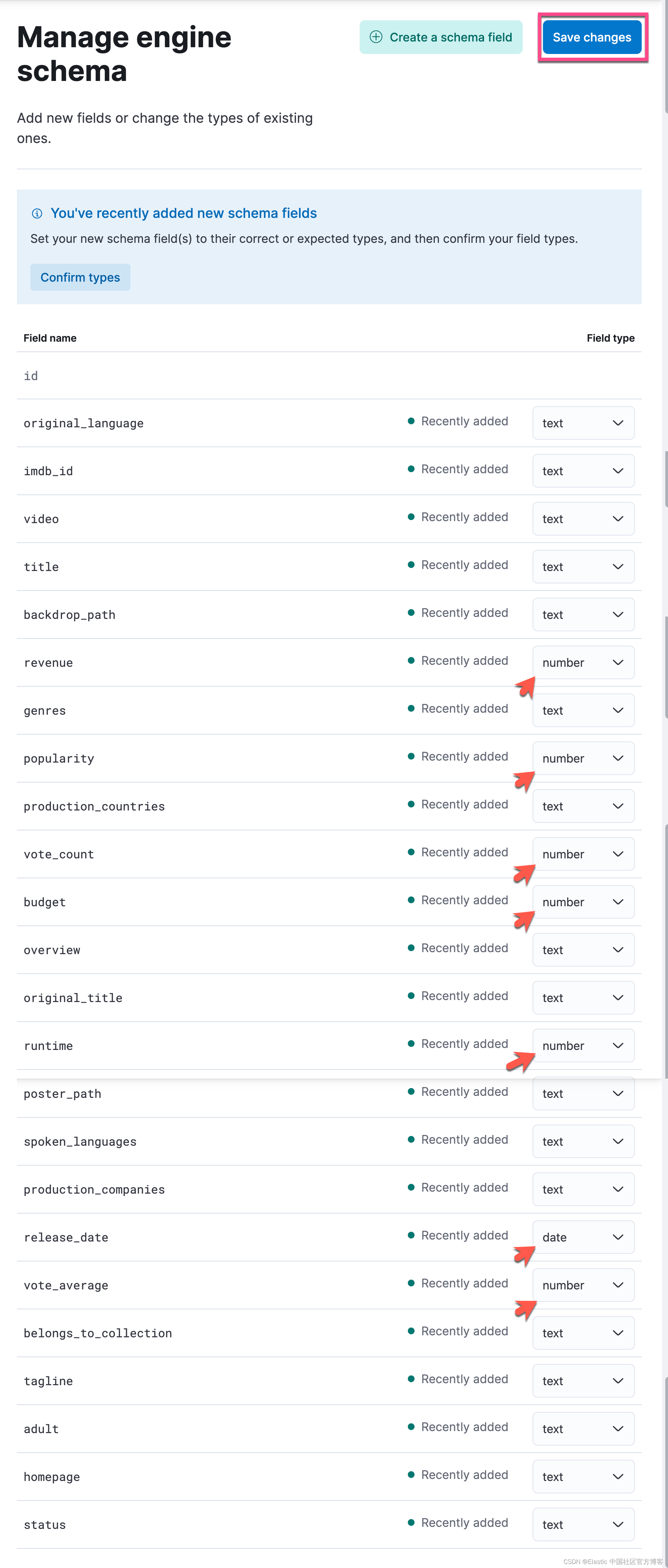 我们根据数据所代表的意思来选择合适的类型。通常我选择一个文档来摄入,并调整所有字段的数据类型。否则我们在摄入所有的文档后再进行调整,那么将会比较耗时一些。等我们把数据里各个字段的类型定义好以后,这就完成了我们的 Schema 定义。点击上面的 Save changes:
我们根据数据所代表的意思来选择合适的类型。通常我选择一个文档来摄入,并调整所有字段的数据类型。否则我们在摄入所有的文档后再进行调整,那么将会比较耗时一些。等我们把数据里各个字段的类型定义好以后,这就完成了我们的 Schema 定义。点击上面的 Save changes:
我们接下来可以摄入更多的其它文档。
我们也可以使用 Python 代码来摄入文档。我们先下载如下位置的源码:
git clone https://github.com/liu-xiao-guo/tutorials我们进入到 app-search 目录下,我们可以看到 app_search_ingest.py 文件:
app_search_ingest.py
from elastic_enterprise_search import AppSearch
import glob, os
import json
app_search = AppSearch(
"app_search_api_endpoint",
http_auth="api_private_key"
)
response = []
print("Uploading movies to App Search...")
os.chdir("movies_directory")
for file in glob.glob("*.json"):
with open(file, 'r') as json_file:
try:
response = app_search.index_documents(engine_name="movies",documents=json.load(json_file))
print(".", end='', flush=True)
except:
print("Fail!")
print(response)
break如上所示,我们需要获得 http_auth 里的 private key。我们可以通过如下的方式来获得:
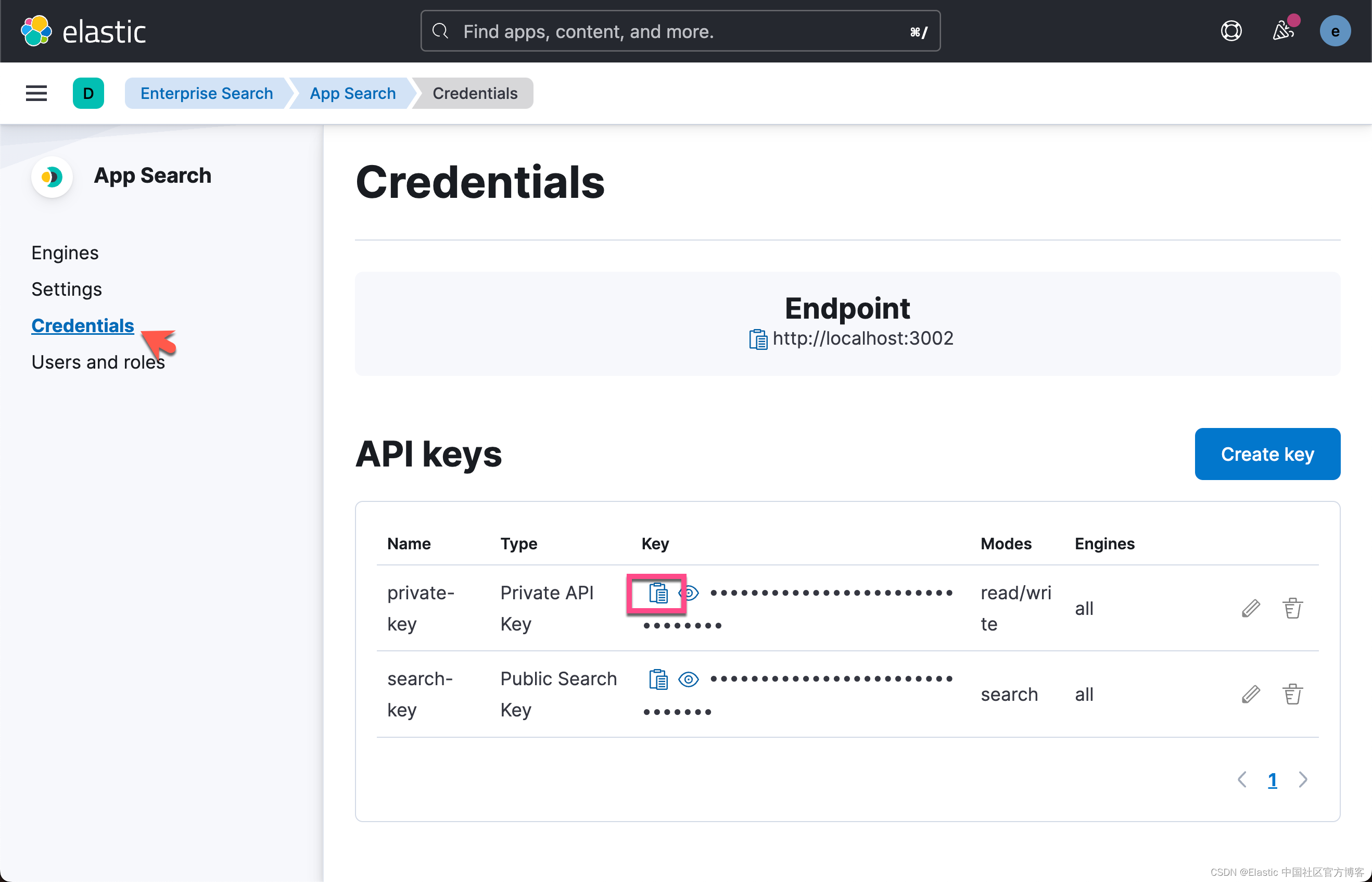
根据我的情况,我修改上面的代码为:
from elastic_enterprise_search import AppSearch
import glob, os
import json
app_search = AppSearch(
"http://localhost:3002",
http_auth="private-49cx4j3qe4pv35n4xxy4b4z7"
)
response = []
print("Uploading movies to App Search...")
os.chdir("/Users/liuxg/data/movies_tmdb/movies/movies")
for file in glob.glob("*.json"):
with open(file, 'r') as json_file:
try:
response = app_search.index_documents(engine_name="movies",documents=json.load(json_file))
print(".", end='', flush=True)
except:
print("Fail!")
print(response)
break
我们接下来运行上面的代码:
pip install elastic_enterprise_search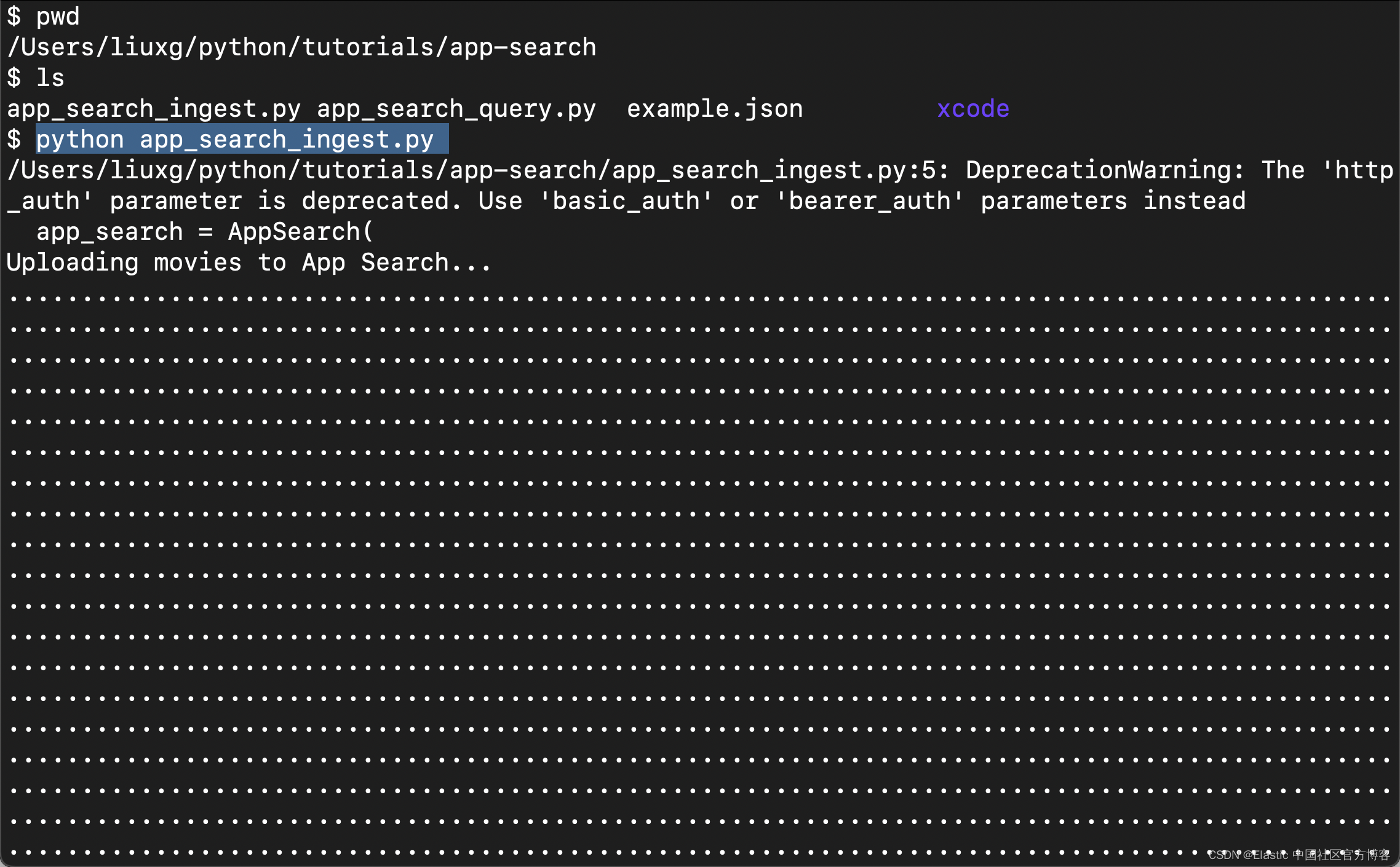
我们可以在 Kibana 界面看到新摄入的文档:

在代码的根目录下,我们还可以看到一个 app_search_query.py 的文件。我根据自己的配置,修改如下:
app_search_query.py
import requests
api_endpoint = 'http://localhost:3002' + '/api/as/v1/engines/movies/search'
api_key = 'private-49cx4j3qe4pv35n4xxy4b4z7'
headers = {q'Content-Type': 'application/json',
'Authorization': 'Bearer {0}'.format(api_key)}
query = {'query': 'family'}
response = requests.post(api_endpoint, headers=headers, json=query)
print(response.text)我们运行代码如下:
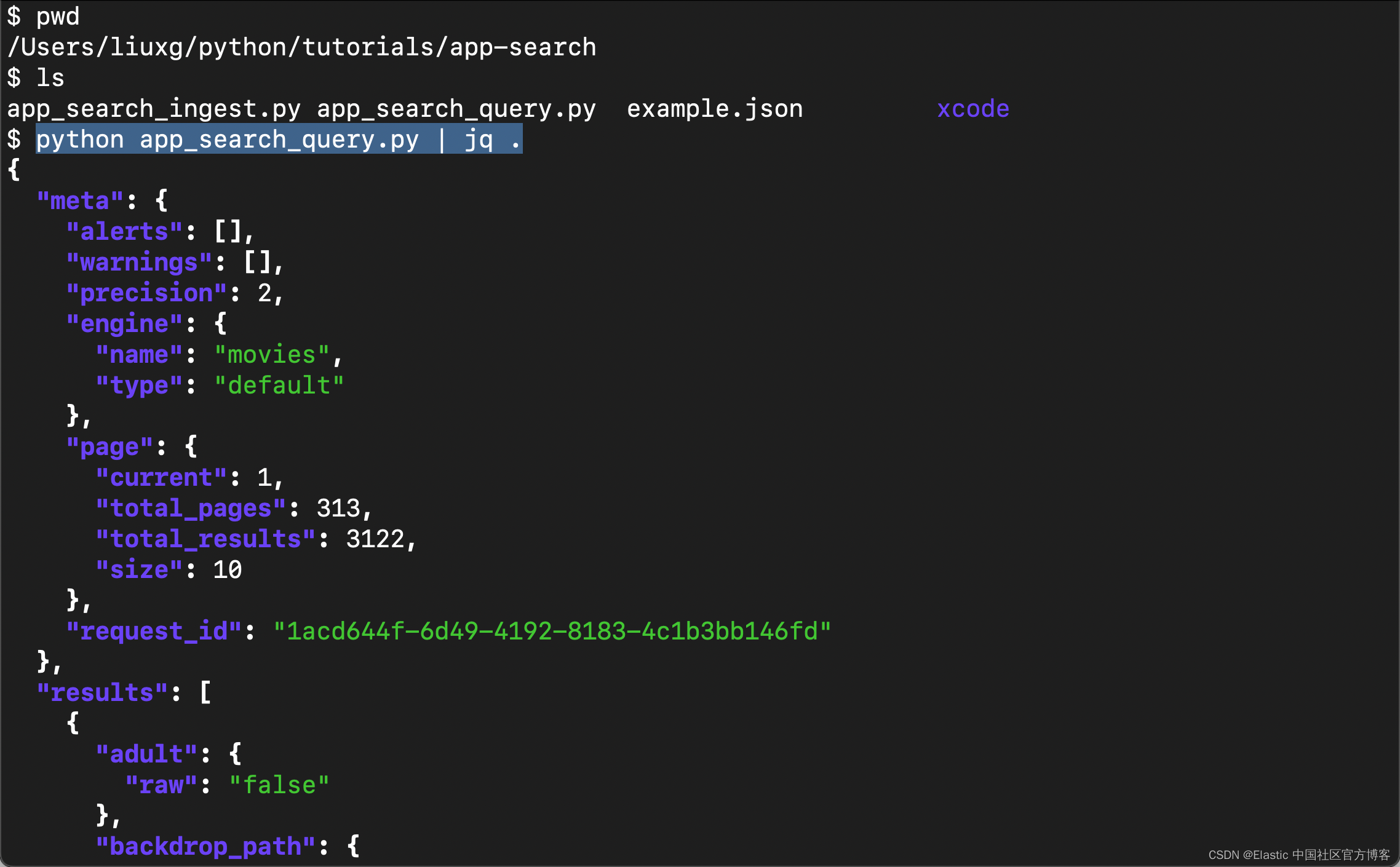
我们看到有很多的输出。