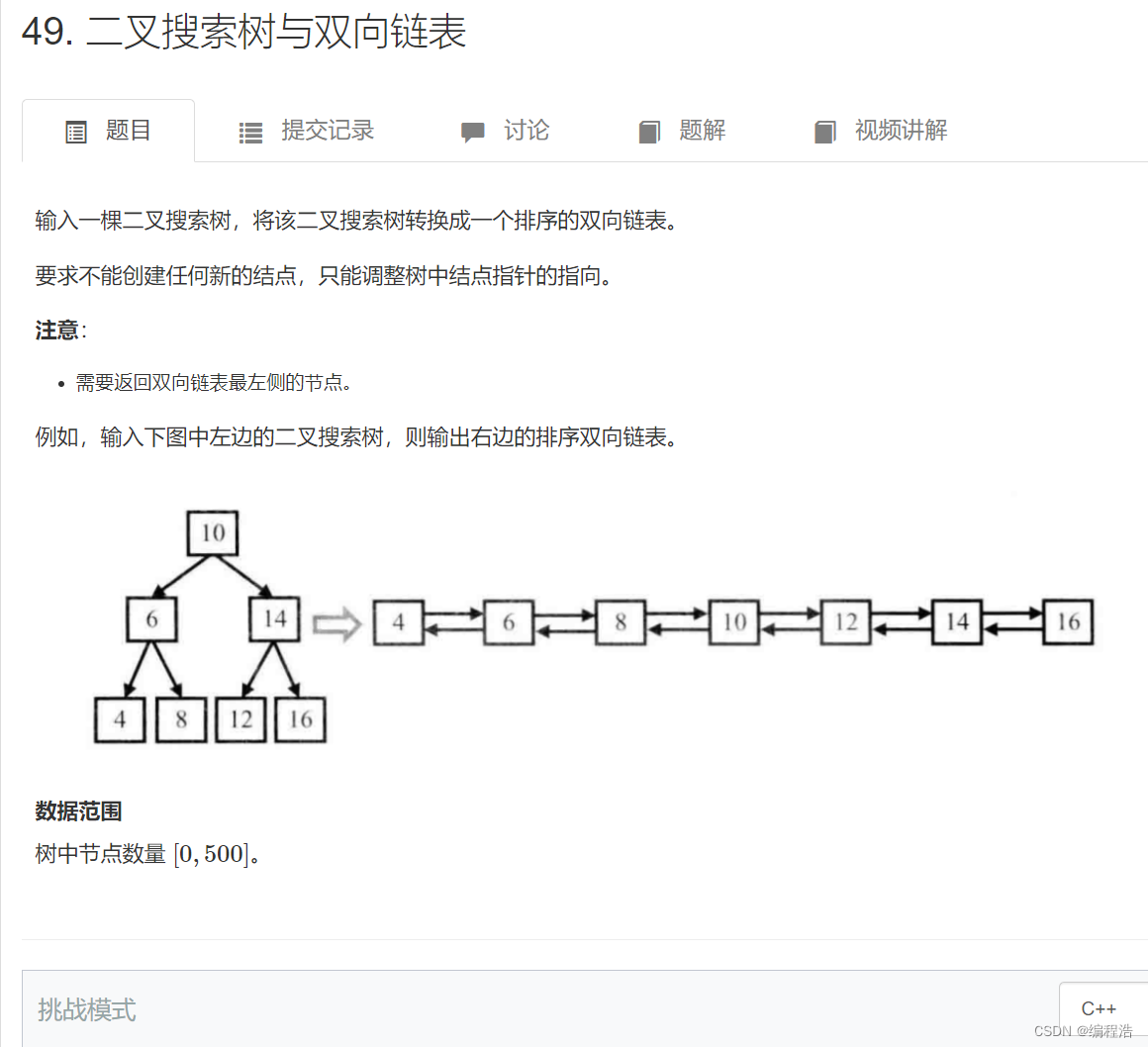
字典树(Trie 树)是一种用于快速查找前缀的数据结构。它的主要思想是:
- 树的每个节点表示一个字符
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串
- 每个节点的所有子节点包含共同的前缀
例如,对于单词列表[“hello”, “help”, “world”]可以构造这样的字典树:
root
/
h w
/ \
e l
| \
l p
o
搜索某个字符串是否在字典树中,就是从根节点开始,逐字符向下搜索对应的节点,如果最后能搜索到叶子节点,就说明这个字符串在树中。
字典树的典型操作有: - 插入字符串:逐字符插入节点
- 查找前缀:从根向下搜索前缀字符
- 查找字符串:从根向下完全匹配搜索
字典树的优点是:
- 搜索前缀非常快速,时间复杂度O(K),K为字符串长度
- 占用空间小,结构紧凑
- 可以高效删除与插入字符串
字典树常用来存储大量字符串,实现自动补全、拼写检查等功能。
总之,字典树是一种用于快速查找前缀的树形数据结构,它利用字符串之间的公共前缀来提高查询效率。如果要存储大量字符串,并经常查询字符串前缀,字典树是非常高效的选择。
class Trie {
vector<Trie*> children;
bool isEnd;
Trie* searchPrefix(string prefix) {
Trie* node = this;
for (char ch : prefix) {
ch -= 'a';
if (node->children[ch] == nullptr){
return nullptr;
}
node = node->children[ch];
}
return node;
}
public:
Trie() : children(26), isEnd(false) {}
void insert(string word) {
Trie* node = this;
for (char ch : word) {
ch -= 'a';
if (node->children[ch] == nullptr) {
node->children[ch] = new Trie();
}
node = node->children[ch];
}
node->isEnd = true;
}
bool search(string word) {
Trie* node = this->searchPrefix(word);
return node != nullptr && node->isEnd;
}
bool startsWith(string prefix) {
return this->searchPrefix(prefix) != nullptr;
}
};