External Shuffle Service的问题
在 spark2 中,如果想要使用动态资源调度,external shuffle service外部独立的shuffle服务是必须条件,因为 spark 需要确保回收 executor 时不会删除生成的 shuffle 数据,外部的 shuffle 服务可以使得 shuffle 数据保存在 executor 之外。
但在不同的集群部署方案中,如 YARN,Mesos,Standalone配置外部的 shuffle 服务的方式都不一样,每当有新的部署方案,例如支持 Kubernetes 集群,都需要实现对应的 shuffle 服务以支持动态资源分配,可以看到动态资源分配与资源集群耦合太紧,从而限制其灵活性。
Spark 3 中的 改进解决
在 spark 3.0 中,对动态扩缩容 executor 进行了优化,引入了 shuffleTracking 功能,可以不依赖 External Shuffle Service 但整体性能自然也一般,从而可以实现智能的跟踪和管理 shuffle 数据。
参考 issue:https://github.com/apache/spark/pull/24083
Spark3 中的动态分配的配置项说明
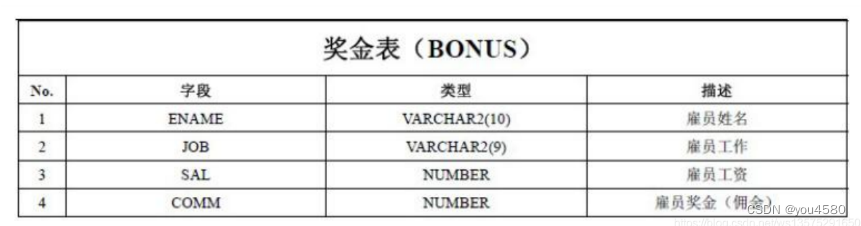
| 配置项 | 默认值 | 解释 | 开始版本 |
| spark.dynamicAllocation.enabled | false | 是否启动动态executor 分配,注意如果开启了这个选项,那么 spark.shuffle.service.enabled或 spark.dynamicAllocation.shuffleTracking.enabled配置项其中任意一个也必须要被激活 | 1.2.0 |
| spark.dynamicAllocation.executorIdleTimeout | 60s | executor 空闲时间超过这个值,该 executor 将会被缩容回收 | 1.2.0 |
| spark.dynamicAllocation.cachedExecutorIdleTimeout | infinity | 如果 executor 中的 cache 缓存的有数据,那个这个配置项可以控制 该 executor 多久后被回收 | 1.4.0 |
| spark.dynamicAllocation.minExecutors | 0 | 如果启用动态分配,则executor数量的下限 | 1.2.0 |
| spark.dynamicAllocation.maxExecutors | infinity | 如果启用动态分配,则executor数量的上限 | 1.2.0 |
| spark.dynamicAllocation.initialExecutors | 和minExecutors的值相等 | 启用动态分配的初始化 executor 是数量,与--num-executors 或 spark.executor.instances配置的值中取最大值生效 | 1.3.0 |
| spark.dynamicAllocation.executorAllocationRatio | 1 | 动态分配根据任务数量生成的最大并行度,默认提供最大并行度,该为 0.5 则降低一半新增的 executor 的数量,对某些小任务会提高资源利用率,受minExecutors和maxExecutors值的影响 | 2.4.0 |
| spark.dynamicAllocation.schedulerBacklogTimeout | 1s | 延迟动态 executor 请求生成时间 | 1.2.0 |
| spark.dynamicAllocation.sustainedSchedulerBacklogTimeout | 与schedulerBacklogTimeout一样 | 当首次生成的 executor并不能处理完执行队列的里面所有任务,那么随后每隔 sustainedSchedulerBacklogTimeout 的时间继续生成的新的 executor,executor 的数量成指数型增加,如1,2,4,8,类似 TCP 的慢启动策略 | 1.2.0 |
| spark.dynamicAllocation.shuffleTracking.enabled | false | 不依赖外部集群的 external shuffle service服务,Spark内部提供shuffle files 跟踪功能,该选项会对正在运行的 Active Executor 的shuffle 数据进行管理存储 | 3.0.0 |
| spark.dynamicAllocation.shuffleTracking.timeout | infinity | 本地磁盘上 shuffle 数据的清理时间,默认情况下 shuffle 数据在 GC 时会被清理掉,但这仅限于是 Active 状态的 Executor | 3.0.0 |
注意上文所说的 GC 配置项,并非 JVM的 GC 配置,而是 Spark 的配置项:
spark.cleaner.periodicGC.interval控制Spark 内部触发垃圾收集的频率,默认值为 30min也就是半小时,对于本地磁盘比较小的节点,建议调小该值
动态资源调度下shuffle数据清理的问题
启动了动态资源调度后(spark.shuffle.service.enabled=true 或者spark.dynamicAllocation.shuffleTracking.enabled=true)要注意 shuffle 数据的清理问题,如果磁盘比较小,shuffle 写入量又比较大,稍有不慎就会将磁盘打满,spark 自带的配置参数 spark.cleaner.periodicGC.interval 清理策略,只对存活(Active)的 Executor管用,如果是 Dead 状态的 Executor 是无法回收其在磁盘上写入的 shuffle的,只能等到整个应用重启后,YARN 才会清理。所以如果要使用 Spark 3 的动态资源调度,在官方还没有支持自动清理 Dead 节点的 shuffle 数据时,一定要对节点的的磁盘进行监控,此外可以加 crontab 定时脚本来清理:例如每小时清理,早于 6 个小时之前的数据:
0 * * * * /home/hadoop/clean_appcache.sh >/dev/null 2>&1#!/bin/bash
BASE_LOC=/mnt/yarn/usercache/hadoop/appcache
find $BASE_LOC -mmin +360 -prune -exec rm -rf {} \;动态分配 Executor+Shuffle启动命令例子
/opt/spark/bin/spark-submit \
--master yarn \
--deploy-mode client \
--conf spark.driver.host=$NODE_IP \
--conf spark.driver.bindAddress=$POD_IP \
--conf spark.metrics.namespace=test-demo \
--conf spark.yarn.metrics.namespace=test-demo \
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \
--conf spark.executor.memoryOverhead=8G \
--conf spark.executorEnv.XT=${XT} \
--conf spark.yarn.queue=spark \
--conf spark.driver.memory=8G \
--conf spark.ui.port=20001 \
--conf spark.blockManager.port=20002 \
--conf spark.driver.port=20003 \
--conf spark.cleaner.periodicGC.interval=30min \
--conf spark.shuffle.service.enabled=true \
--conf spark.dynamicAllocation.enabled=true \
--conf spark.dynamicAllocation.minExecutors=1 \
--conf spark.dynamicAllocation.maxExecutors=8 \
--conf spark.dynamicAllocation.initialExecutors=1 \
--conf spark.dynamicAllocation.executorIdleTimeout=600s \
--conf spark.dynamicAllocation.cachedExecutorIdleTimeout=600s \
--class com.test.SparkDynamicScheduleShuffleTest \
--keytab /opt/security/test.keytab \
--principal test \
--files xt.properties \
--driver-cores 1 \
--executor-cores 2 \
--executor-memory 4G \
--jars hdfs:///xxx1.jar \
--name shuffle-test \
hdfs:///xxx.jar