面试题讲解🍴
文章目录
- 面试题讲解🍴
- ==和equals()的区别🍔
- 1️⃣注意事项
- 2️⃣明确问题
- 3️⃣总结
- 什么是HashCode🍇
- 1️⃣HashCode的描述
- 2️⃣常见误区
- 3️⃣hashCode的作用
- 4️⃣总结
- String、StringBuffer、StringBuilder的区别🍈
- 1️⃣String、StringBuffer和StringBuilder的共同点
- 2️⃣String、StringBuffer和StringBuilder的区别
- 3️⃣总结
- ArrayList与LinkedList的区别🍊
- 1️⃣共同点
- 2️⃣区别
- 3️⃣常见误区
- 4️⃣总结
- 什么是volatile🍐
- 1️⃣主要作用
- 2️⃣关于指令重排
- 3️⃣关于属性的可见性
- 4️⃣总结
- Thread类中的start()和run()方法的区别🍓
- 1️⃣关于Thread类的start()方法
- 2️⃣关于Thread类的run()方法
- 3️⃣常见误区
- 4️⃣总结
- String、StringBuffer和StringBuilder的区别🥥
- 1️⃣总结
- ArrayList与LinkedList的区别🍑
- 1️⃣共同点
- 2️⃣区别
- 3️⃣常见误区
- 4️⃣总结
- 什么是volatile🥦
- 1️⃣主要作用
- 2️⃣关于指令重排
- 3️⃣关于属性的可见性
- 4️⃣总结
- Thread类中的start()和run()方法的区别🍋
- 1️⃣关于Thread类的start()方法
- 2️⃣关于Thread类的run()方法
- 3️⃣常见误区
- 4️⃣总结
- 数据库的三范式🍗
- 1️⃣第一范式 1NF(列不可再分)
- 2️⃣第二范式 2NF(该拆就拆)
- 3️⃣第三范式 3NF(没有传递)
- 4️⃣关于冗余
- 5️⃣创建数据库的几点建议
- 6️⃣总结
- 依赖注入的几种方式🥫
- 1️⃣属性注入
- 2️⃣Setter注入
- 3️⃣构造方法注入
- 4️⃣总结
- `@Autowired`和`@Resource`的区别🍣
- 1️⃣共同点
- 2️⃣区别
- 3️⃣常见误区
- 4️⃣引申
- 5️⃣总结
- Mybatis的优点和缺点🍠
- 1️⃣优点
- 2️⃣缺点
- 3️⃣理性看待缺点
- 4️⃣总结
- Mybatis的#{}和${}的区别🍏
- 1️⃣共同点
- 2️⃣SQL注入
- 3️⃣预编译
- 4️⃣Mybatis的#{}占位符
- 5️⃣Mybatis的${}占位符
- 6️⃣总结
- SpringBoot的核心注解有那些🥕
- 1️⃣注意事项
- 2️⃣核心注解
- `@SpringBootApplication`
- `@SpringBootTest`
- 3️⃣总结
- SpringBoot的常用starter有那些🥘
- 1️⃣starter的概念
- 2️⃣提示
- 3️⃣常用的starter
==和equals()的区别🍔
1️⃣注意事项
关于“对比”类型的面试题,建议回答时包括:
- 多个对比项有什么相同 / 相似之处
- 多个对比项的区别
- 在应用中应该如何选取(重要)
- 可能的话,加入一些扩展(对相关知识点的理解)
2️⃣明确问题
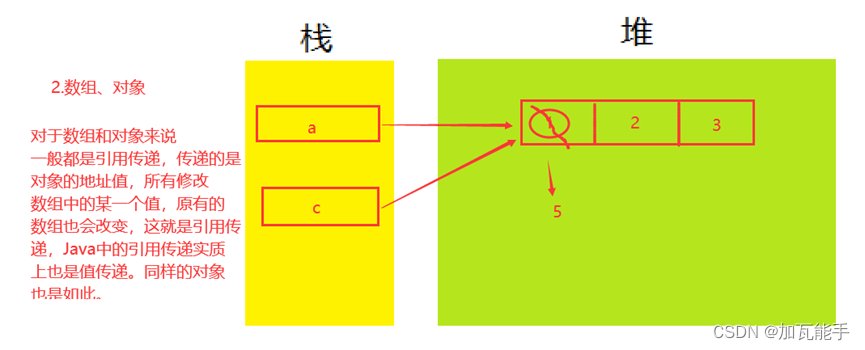
变量和对象是两个不同概念
Object a = new Object()
//a 就是变量 在内存中实际存在的数据就是对象
所有引用类型的变量值都是引用地址
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VLEQzQNb-1687187982965)(../../../AppData/Roaming/Typora/typora-user-images/image-20230611171553917.png)]](https://img-blog.csdnimg.cn/b0cd4572ff17453c8f7e96d4920d0507.png)
==与equals() 相同 / 相似之处:这两者都是用于比较两个变量是否“相同”的
==与equals() 区别:
==是基本用算符,适用于所有类型的变量与变量的对比equals()是Object类定义的方法,用于Object是Java的基类(所有类的父类),所以任何对象都可调用equals()方法实现对比,但是基本数据类型并不是对象,无法调用该方法实现对比- ==对比的是变量的值,基本数据类型对比的是字面值、引用数据类型对比的是引用地址
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PSQTK91e-1687187982966)(../../../AppData/Roaming/Typora/typora-user-images/image-20230611172211079.png)]](https://img-blog.csdnimg.cn/085c6074c6d44cfd9f41e12f2fc44de3.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LIXgNBFX-1687187982967)(../../../AppData/Roaming/Typora/typora-user-images/image-20230611172219695.png)]](https://img-blog.csdnimg.cn/7551a84e543a441590f2c4c103bbca2c.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bd4nfXaJ-1687187982968)(../../../AppData/Roaming/Typora/typora-user-images/image-20230611172246833.png)]](https://img-blog.csdnimg.cn/a2c8c4d1f6d344329f7e665a6be399d3.png)
equals()只是一个方法,到底返回true或false取决于方法的实现,默认情况(根据Object的定义)它与==结果相同,方法可以被重写,在Java中,许多类都重写了equals(),如String、包装类、日期等,尽管是不同的对象,但equals()结果为true
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gqcflw4U-1687187982968)(../../../AppData/Roaming/Typora/typora-user-images/image-20230611172634854.png)]](https://img-blog.csdnimg.cn/2b9fe5c908494424aa4ea02c6949c9c3.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YmQk8CHM-1687187982969)(../../../AppData/Roaming/Typora/typora-user-images/image-20230611172847826.png)]](https://img-blog.csdnimg.cn/5574669c968e4284b408d27a332fbfc3.png)
由于Java对常量池的特殊处理,直接声明的字符串使用==对比也是成立的
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GA8KnL5z-1687187982969)(../../../AppData/Roaming/Typora/typora-user-images/image-20230611172953087.png)]](https://img-blog.csdnimg.cn/22696f93539c499fb627042cc69fd4c6.png)
在[-128,127]区间的值对整型包装类对象使用==对比也是成立的
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OisxhpTp-1687187982970)(../../../AppData/Roaming/Typora/typora-user-images/image-20230611173112503.png)]](https://img-blog.csdnimg.cn/d295fa776962444f852e53f03da1bddb.png)
3️⃣总结
- 相同之处:都是对比两个数据是否相同
- 不同之处:
==可用于对比所有数据,而equals()只能被对象调用,==对比的是变量值是否相同,所以基本数据类型的变量只要字面值相同就为true,引用类型的变量仅当引用地址相同时才返回true,equals()是Object定义的,默认使用==实现对比,所以,当该方法没有被重写时,执行效果与==相同,如果被重写,则取决于重写的代码,如String类,在执行equals()将逐一对比字符串中的每个字符,所以,只要两个String对象的字符完全相同,两个String对象使用equals()对比返回结果为true - 补充说明:由于Java会在编译期处理常量,常量池中的每个常量都是唯一的,所以,当使用字符串常量直接对变量赋值,或使用 [-128,127] 区间值对
Byte/Short/Integer/Long类型的对象赋值时,使用==对比的结果为true - 实际应用原则:实际编写代码中,对于基本数据类型的变量,必须使用
==进行对比,因为基本数据类型变量不可调用equals(),对于引用数据类型的变量推荐使用equals()进行对比,且在必要的情况下,重写equals(),使之返回结果的规则符合当前编码要求,重写时,保证同一个对象的对比结果为true,即如果==对比为true,则equals()对比返回true
什么是HashCode🍇
通常,口头描述的hashCode指的是hashCode()方法,或该方法的返回值,hashCode()方法是由Object类定义的,所以在Java中,所有类都有该方法,并且所有类都可重写该方法
1️⃣HashCode的描述
- 返回该对象的哈希值。这个方法是为哈希表提供支持的,比如由
HashMap提供的哈希表 - .hashCode的一般原则是:
- 在Java应用程序的执行过程中,只要对同一个对象调用一次以上,
hashCode方法就必须始终返回相同的整数,前提是在对象的equals比较中使用的信息没有被修改。对于同一个应用程序而言,某一次的执行与另一次执行时,该值需要保持一致 - 如果两个对象根据
equals(Obiect)方法对比的结果是相等的,那么在这两个对象上调用hashCode方法必须产生相同的整数结果 - 有种情况并不是强制的:如果根据
equals(Obiect)方法,两个对象不相等,那么在这两个对象上调用hashCode方法必须产生不同的整数结果。然而,程序员应该知道,为不相等的对象产生不同的整数结果可能会提高哈希表的性能
- 在Java应用程序的执行过程中,只要对同一个对象调用一次以上,
2️⃣常见误区
- 误区:
hashCode就是对象的内存地址 - 解读:哈希(
hash)一般指散列算法,也叫哈希算法,在Object类的实现中,哈希码(hashCode)是通过哈希算法得到的一个整型结果,本质与内存地址没关系 - 误区产生原因:根据
Object类的hashCode()实现,每个对象的hashCode值(理论上)都不同,通常可以用于判断两个变量是否引用同一个对象 - 反向论证:
hashCode无法表示对象的内存地址- JVM在进行垃圾管理时,会移动对象的位置,即:经过某次垃圾回收之后,对象在内存中的位置可能就已经发生了变化,但
hashCode值并不会变 - Integer(或int〉类型的值区间是
-2147483648~2147483647,Java管理的内存已经超过4GB,所以,hashCode不可能是内存地址
- JVM在进行垃圾管理时,会移动对象的位置,即:经过某次垃圾回收之后,对象在内存中的位置可能就已经发生了变化,但
- 误区:手动使用
hashCode - 解读:这个方法是为哈希表提供的,比如
HashMap提供的哈希表,hashCode的设计是提供给JVM管理对象时使用的,并不是给开发者自行使用的
3️⃣hashCode的作用
- Hash容器可以通过
hashCode定位需要使用的对象,典型的Hash容器:HashSet、HashMap、HashTable、ConcurrentHashMap。再次强调hashCode不是对象的内存地址 - Hash容器通过
hashCode来排除两个不相同的对象,例如向HashSet的元素、HashMap的Key等都要求“唯一”,如果即将添加的元素的hashCode与集合中已有的每个元素的hashCode均不同,则可以视为“当前集合中尚不存在即将添加的元素。如果两个对象的hashCode相同。Hash容器还会调用equals()方法,仅当equals()也返回true时,才会视为“相同”
4️⃣总结
hashCode()是Object定义的方法,它将返回一个整型值,它并不代表对象在内存中的地址,它存在的价值是为Hash容器处理数据时提供支持,Hash容器可以根据hashCode定位需要使用的对象,也可以根据hashCode来排除两个不相同的对象,即:hashCode不同,则视为两个对象不同- 在重写
hashCode()时,应该遵循Java SE的官方指导:- 如果两个对象使用
equals()对比的结果为true,则这两个对象的hashCode()返回的结果应该相同 - 如果两个对象使用
equals()对比的结果为false,则这两个对象的hashCode()返回的结果应该不同 - 通常,你不必关心如何重写
equals()方法和hashCode()方法,而是使用IDE生成,例如Eclipse、IntelliJIDEA,它们生成的方法是符合以上指导意见的
- 如果两个对象使用
String、StringBuffer、StringBuilder的区别🍈
1️⃣String、StringBuffer和StringBuilder的共同点
- 都是用于处理字符串数据的类
- 都是管理内部的一个
char[]实现的 - 实现的接口大致相同,特别是
CharSequence接口 - 许多API的设计中,方法的参数或返回值都使用这个接口,使得参数或返回值更加灵活
- 有许多相同的APl,例如
replace()、indexOf()等
2️⃣String、StringBuffer和StringBuilder的区别
-
String的“不可变”特性:每个字符串对象都是不可变的,其特性是由于其内部通过管理一个char[]决定的,Java语言中,数组在内存中必须是连接的,长度是不可变的String s = "hello"; s = "hello, world !"; //以上代码中,声明了1个变量,创建了2个对象 -
String的“不可变”特性与该类声明中的
final无关。final只是表示这个类不可以继承,String的“不可变”特性,在String的API中,所有修改字符串的方法都将返回新的String对象,基于String的“不可变”特性,其修改操作的效率非常低下,需要寻址、创建新对象,还可能将原有的char[]的某部分复制到新的char[]中![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oc7LETRY-1687187982971)(../../../AppData/Roaming/Typora/typora-user-images/image-20230611184400267.png)]](https://img-blog.csdnimg.cn/e792ab59feed445e90d9e46bc16657b0.png)
-
StringBuffer和StringBuilder从一开始就会使用长度更长的char[],哪怕只用于存放少量的几个字符。其length()方法会返回实际存放的字符数量![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-21uNTKAU-1687187982972)(../../../AppData/Roaming/Typora/typora-user-images/image-20230611184612641.png)]](https://img-blog.csdnimg.cn/82992ea1adda41c2bcc72c685380578a.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MdfSerTV-1687187982973)(../../../AppData/Roaming/Typora/typora-user-images/image-20230611184906765.png)]](https://img-blog.csdnimg.cn/0e6434437aee406cb1d804972e3c5c35.png)
-
在许多调整字符串的操作中,
StringBuffer和StringBuilder只需要直接调整内部的char[]即可,不需要频繁的寻址、创建新对象等操作,所以,实际执行效率远高于String类! -
当然,如果默认的
char[]长度(实际长度)不足以满足运算需求时,会自动扩容,也需要创建新的对象![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-V4pW0nzY-1687187982973)(../../../AppData/Roaming/Typora/typora-user-images/image-20230612224300691.png)]](https://img-blog.csdnimg.cn/558fcd286b96466698f259e6d6f461bc.png)
3️⃣总结
- 相同之处:
- 都是用于处理字符串数据的类
- 都是管理内部的一个char[]实现的
- 实现的接口大致相同,特别是
CharSequence接口 - 有许多相同的API,例如
replace()、indexOf()等
- 不同之处:
- String的字符串操作效率低下,是因为它的“不可变”特性决定的
StringBuffer和StringBuilder会保证管理的char[]的长度始终高于实际存入的字符长度,在处理字符串操作时,效率远高于StringStringBuffer是线程安全的,而StringBuilder不是
- 实际使用原则:尽管
StringBuffer和StringBuilder在处理字符串时的效率远高于String,但并不是每个String都需要频繁的改变,相比之下,使用String的语法更加简洁、直观,实际占用的存储空间更小,所以,当字符串不需要频繁的改变时,优先使用String。如果字符串需要频繁改变,原则上来说,仅当单线程运行时,或已经采取措施保障线程安全时,优先使用StringBuilder,因为它的执行效率高于StringBuffer,事实上,尽管StringBuilder的执行效率比StringBuffer高,但差距并不大,为了避免后续调整带来的安全隐患,当字符串可能频繁改变时,一般使用StringBuffer。
ArrayList与LinkedList的区别🍊
1️⃣共同点
都是List接口的实现类,都是序列的,可存储相同元素,绝大多数情况下不需要关心特有方法
- 关于“序列的”:
- 在List集合中的各元素都有索引,类似数组下标,是顺序编号的
- 不推荐描述为“有序的”,详见后续
LinkedList的存储结构 - 同理,不要将Set集合描述为“无序的”,只能描述为“散列的”。例如
TreeSet、LinkedHashSet的各元素就可以表现出“有序”的特征
- 关于“存储相同元素”:
- 在使用集合时,仅当两个对象的
hashCode()返回值相同,且equals()对比结果为true时,视为“相同” Set集合不可以存储相同元素
- 在使用集合时,仅当两个对象的
2️⃣区别
-
ArrayList的底层实现是基于数组的- 优点:查询效率高
- 缺点:修改效率低
-
LinkedList的底层实现是基于双向链表的-
内部使用“节点”管理元素
-
优点:修改效率高——增删
-
缺点:查询效率低
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3ZLUU1iX-1687187982974)(../../../AppData/Roaming/Typora/typora-user-images/image-20230612224320343.png)]](https://img-blog.csdnimg.cn/941fedec6b0348d79f24488e432ecc72.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-a5eoQimB-1687187982975)(../../../AppData/Roaming/Typora/typora-user-images/image-20230612224328035.png)]](https://img-blog.csdnimg.cn/170bfc7bc2f94871bb85d3aac53363a5.png)
-
-
因为
LinkedList的底层实现基于双向链表,当添加元素时,本质是基于新元素创建“节点”,每个节点需要记录指向前一个节点和后一个节点的引用,占用的存储空间更多。 -
无论是
-
无论是
ArrayList,还是LinkedList,都是线程不安全的,当在多线程中需要使用List时,应该使用CopyOnWriteArrayList
3️⃣常见误区
- 错误的表达:查询使用
ArrayList,修改使用LinkedList - 解读:
- 尽管
ArrrayList易读难写,但是没有写入数据就无从读起 - 尽管
LinkedList易写难读,但是光写入,不读取就毫无意义 ArrayList和LinkedList这两者之间没有继承关系,不可互相转换- 如果对程序的运行效率的要求非常高,可以事先分析读写频率,并根据分析结果使用
ArrayList或LinkedList
- 尽管
4️⃣总结
- 相同之处:
- 都是List接口的实现类
- 都是序列的,可存储相同的元素
- 绝大部分情况下,不关心特有方法
- 都是线程不安全的
- 不同之处:
ArrayList的底层实现是基于数组的,所以查询效率高,修改效率低LinkedList的底层实现是基于双向链表的,所以查询效率低,修改效率高,另外内部本质上管理的是多个节点,每个节点需要记录指向前一个节点和后一个节点的引用,占用的存储空间更多
- 实际使用原则:在使用简单的字符串作为集合元素时,在10万级别的元素数量时,
ArrayList和LinkedList的性能差异并不明显(在绝大部分情况下,使用List时的元素数量都不超过100个,尽管元素数据更加复杂),并且,不可以单纯的只读不写,或只写不读,同时,基于ArrayList占用的存储空间更少,一般使用ArrayList即可,仅当需要极致的追求性能时,再根据读写频率来区分使用,但是当需要考虑线程安全问题时,则使用CopyOnWriteArrayList
什么是volatile🍐
volatile是Java语言中的一个关键字,可以修饰类的属性,英译一般为:不稳定的
1️⃣主要作用
- 禁止指令重排
- 确保多线程时属性的可见性
2️⃣关于指令重排
在代码没有依赖关系的前提下,出于优化的目的,CPU和编译器均可能会对指令进行重新排序,可能导致执行顺序与源代码顺序并不相同
//以下2行代码的执行先后顺序可以被改变,并且不会出现任何错误
int x = 5;
int y = 8;
//以下2行代码的执行先后顺序不会被改变
int x = 5;
int y = x + 8;
但是在多线程下,指令重排可能导致运行结果不符合预期
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-z0H4BvnB-1687187982976)(../../../AppData/Roaming/Typora/typora-user-images/image-20230612224352837.png)]](https://img-blog.csdnimg.cn/9aa4fb8c321b40248094da0fe056b791.png)
- 指令重排是CPU和编译器决定的,一定程度上人为不可控。
- 指令重排的目的是优化指令,提高执行效率,在单线程中,执行结果不会出现问题,但是,在多线程中,可能出现预期外的结果,所以,应该为共享变量添加
volatile关键字进行修饰
3️⃣关于属性的可见性
- 每个线程在执行过程中,有专属的工作内存空间,当需要某个值时,会优先从工作内存中查找,如果工作内存中没有,则会从主内存中将值复制到工作内存中并缓存。
- 在多线程情景下,可能存在:X线程已经将值缓存到工作内存中,Y线程改变了主内存的值,但X线程仍使用工作内存中缓存的值(尚未从主内存中同步最新的值)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yVvEyqTO-1687187982977)(../../../AppData/Roaming/Typora/typora-user-images/image-20230612224405973.png)]](https://img-blog.csdnimg.cn/65f2c1ce42ae4b07bc8881880e5f07bb.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QpsNH2wD-1687187982977)(../../../AppData/Roaming/Typora/typora-user-images/image-20230612224416345.png)]](https://img-blog.csdnimg.cn/ac6b599c3aeb43b8bcee00b63ae5607d.png)
线程更新了共享变量的值,但其它线程仍使用工作内存中缓存的值,出现属性可见性问题,添加volatile即可解决此问题
4️⃣总结
- 关于
volatile,它是一个关键字,用于修饰类的成员,主要作用是禁止指令重排,确保多线程时属性的可见性 synchronized和volatile均不可替代彼此,虽然两者都是用于解决多线程相关问题的,但问题的情景并不相同,通常,使用synchronized解决的问题大多是“多个线程执行相同的代码”的情景,而使用volatile解决的问题大多是“多个线程执行的代码不同,但使用到了相同的共享变量”的情景- 实际使用原则:当某个属性出现在多个方法中,至少有1个方法会改变该属性的值,且这些方法可能同时被不同的线程执行,则应该为属性添加
volatile关键字
Thread类中的start()和run()方法的区别🍓
1️⃣关于Thread类的start()方法
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-k8wEWQ5W-1687187982978)(../../../AppData/Roaming/Typora/typora-user-images/image-20230612224437090.png)]](https://img-blog.csdnimg.cn/c07f81c653564b5ab14d4d609af1bc3f.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XtotOBq7-1687187982979)(../../../AppData/Roaming/Typora/typora-user-images/image-20230612224447620.png)]](https://img-blog.csdnimg.cn/4e70f74e4dbc495db2ba8210b75477ed.png)
- 是用于启动线程的方法
- 其内部(自动的)调用run()方法
- 通常,每个线程对象只能调用1次该方法
2️⃣关于Thread类的run()方法
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MR5AChSm-1687187982980)(../../../AppData/Roaming/Typora/typora-user-images/image-20230612224500028.png)]](https://img-blog.csdnimg.cn/a82f468fda4845cc8a32058bad90334f.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QRIsxMrk-1687187982981)(../../../AppData/Roaming/Typora/typora-user-images/image-20230612224509708.png)]](https://img-blog.csdnimg.cn/fe924ff39a1b4f3c96788453ee19ef4a.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eAInxpdv-1687187982991)(../../../AppData/Roaming/Typora/typora-user-images/image-20230612224520220.png)]](https://img-blog.csdnimg.cn/6ae28432fe5e46748c019f269511a2f3.png)
- 是在线程启动后(自动的)被调用的方法
- 用于编写子线程执行的代码
- 默认的
run()方法会尝试调用Runnable对象(如果存在的话)的run()方法, 否则什么都不执行,也不返回任何值 - 如果你创建线程对象时使用
Runnable对象作为构造方法的参数,当线程启动会调用Runnable对象的run()方法。所以,你应该在Runnable实现类中实现run()方法 - 如果你创建的是
Thread子类的对象,则应该在Thread子类中重写run()方法
3️⃣常见误区
- 误区:Runnable是线程接口
- 解读:
Runnable表示“可执行的”,创建Thread对象时,可以使用Runnable接口类型的对象作为构造方法的参数,并且,在子线程中执行的确实是Runnable实现类中的run()方法,但是,Runnable自身并不是线程接口,事实上,还有许多其它类都可能使用到Runnable,但与线程完全没有关系。
4️⃣总结
- 关于start()方法:
- 是用于启动线程的方法
- 其内部会(自动的)调用run( )方法
- 通常,每个线程对象只能调用1次该方法
- 关于run()方法:
- 是在线程启动后(自动的)被调用的方法
- 用于编写子线程执行的代码
- 默认的run( )方法会尝试调用Runnable对象(如果存在的话)的run()方法,否则,什么都不执行,也不返回任何值
- 使用Runnable接口时,应该实现run( )方法
- 使用Thread子类时,应该重写run()方法
String、StringBuffer和StringBuilder的区别🥥
-
在许多调整字符串的操作中,
StringBuffer和StringBuilder只需要直接调整内部的char[]即可,不需要频繁的寻址、创建新对象等操作,所以,实际执行效率远高于String类! -
当然,如果默认的
char[]长度(实际长度)不足以满足运算需求时,会自动扩容,也需要创建新的对象![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7qc2Sl7C-1687187982991)(../../../AppData/Roaming/Typora/typora-user-images/image-20230619190337775.png)]](https://img-blog.csdnimg.cn/1cc8fa8244794e7aa7d653d6c5c3aae8.png)
1️⃣总结
- 相同之处:
- 都是用于处理字符串数据的类
- 都是管理内部的一个char[]实现的
- 实现的接口大致相同,特别是
CharSequence接口 - 有许多相同的API,例如
replace()、indexOf()等
- 不同之处:
- String的字符串操作效率低下,是因为它的“不可变”特性决定的
StringBuffer和StringBuilder会保证管理的char[]的长度始终高于实际存入的字符长度,在处理字符串操作时,效率远高于StringStringBuffer是线程安全的,而StringBuilder不是
- 实际使用原则:尽管
StringBuffer和StringBuilder在处理字符串时的效率远高于String,但并不是每个String都需要频繁的改变,相比之下,使用String的语法更加简洁、直观,实际占用的存储空间更小,所以,当字符串不需要频繁的改变时,优先使用String。如果字符串需要频繁改变,原则上来说,仅当单线程运行时,或已经采取措施保障线程安全时,优先使用StringBuilder,因为它的执行效率高于StringBuffer,事实上,尽管StringBuilder的执行效率比StringBuffer高,但差距并不大,为了避免后续调整带来的安全隐患,当字符串可能频繁改变时,一般使用StringBuffer。
ArrayList与LinkedList的区别🍑
1️⃣共同点
都是List接口的实现类,都是序列的,可存储相同元素,绝大多数情况下不需要关心特有方法
- 关于“序列的”:
- 在List集合中的各元素都有索引,类似数组下标,是顺序编号的
- 不推荐描述为“有序的”,详见后续
LinkedList的存储结构 - 同理,不要将Set集合描述为“无序的”,只能描述为“散列的”。例如
TreeSet、LinkedHashSet的各元素就可以表现出“有序”的特征
- 关于“存储相同元素”:
- 在使用集合时,仅当两个对象的
hashCode()返回值相同,且equals()对比结果为true时,视为“相同” Set集合不可以存储相同元素
- 在使用集合时,仅当两个对象的
2️⃣区别
-
ArrayList的底层实现是基于数组的- 优点:查询效率高
- 缺点:修改效率低
-
LinkedList的底层实现是基于双向链表的-
内部使用“节点”管理元素
-
优点:修改效率高——增删
-
缺点:查询效率低
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-b3gg3jI6-1687187982992)(../../../AppData/Roaming/Typora/typora-user-images/image-20230619190409981.png)]](https://img-blog.csdnimg.cn/1ecc503f3f554d88baff17c9db99b541.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GYlsJ8VP-1687187982993)(../../../AppData/Roaming/Typora/typora-user-images/image-20230619190422961.png)]](https://img-blog.csdnimg.cn/9c248ddff5ef4626b2472882b33fbbf2.png)
-
-
因为
LinkedList的底层实现基于双向链表,当添加元素时,本质是基于新元素创建“节点”,每个节点需要记录指向前一个节点和后一个节点的引用,占用的存储空间更多。 -
无论是
-
无论是
ArrayList,还是LinkedList,都是线程不安全的,当在多线程中需要使用List时,应该使用CopyOnWriteArrayList
3️⃣常见误区
- 错误的表达:查询使用
ArrayList,修改使用LinkedList - 解读:
- 尽管
ArrrayList易读难写,但是没有写入数据就无从读起 - 尽管
LinkedList易写难读,但是光写入,不读取就毫无意义 ArrayList和LinkedList这两者之间没有继承关系,不可互相转换- 如果对程序的运行效率的要求非常高,可以事先分析读写频率,并根据分析结果使用
ArrayList或LinkedList
- 尽管
4️⃣总结
- 相同之处:
- 都是List接口的实现类
- 都是序列的,可存储相同的元素
- 绝大部分情况下,不关心特有方法
- 都是线程不安全的
- 不同之处:
ArrayList的底层实现是基于数组的,所以查询效率高,修改效率低LinkedList的底层实现是基于双向链表的,所以查询效率低,修改效率高,另外内部本质上管理的是多个节点,每个节点需要记录指向前一个节点和后一个节点的引用,占用的存储空间更多
- 实际使用原则:在使用简单的字符串作为集合元素时,在10万级别的元素数量时,
ArrayList和LinkedList的性能差异并不明显(在绝大部分情况下,使用List时的元素数量都不超过100个,尽管元素数据更加复杂),并且,不可以单纯的只读不写,或只写不读,同时,基于ArrayList占用的存储空间更少,一般使用ArrayList即可,仅当需要极致的追求性能时,再根据读写频率来区分使用,但是当需要考虑线程安全问题时,则使用CopyOnWriteArrayList
什么是volatile🥦
volatile是Java语言中的一个关键字,可以修饰类的属性,英译一般为:不稳定的
1️⃣主要作用
- 禁止指令重排
- 确保多线程时属性的可见性
2️⃣关于指令重排
在代码没有依赖关系的前提下,出于优化的目的,CPU和编译器均可能会对指令进行重新排序,可能导致执行顺序与源代码顺序并不相同
//以下2行代码的执行先后顺序可以被改变,并且不会出现任何错误
int x = 5;
int y = 8;
//以下2行代码的执行先后顺序不会被改变
int x = 5;
int y = x + 8;
但是在多线程下,指令重排可能导致运行结果不符合预期
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NMag7aFm-1687187982994)(../../../AppData/Roaming/Typora/typora-user-images/image-20230619190445754.png)]](https://img-blog.csdnimg.cn/1a141acf4ad049639877494ed5b8249c.png)
- 指令重排是CPU和编译器决定的,一定程度上人为不可控。
- 指令重排的目的是优化指令,提高执行效率,在单线程中,执行结果不会出现问题,但是,在多线程中,可能出现预期外的结果,所以,应该为共享变量添加
volatile关键字进行修饰
3️⃣关于属性的可见性
- 每个线程在执行过程中,有专属的工作内存空间,当需要某个值时,会优先从工作内存中查找,如果工作内存中没有,则会从主内存中将值复制到工作内存中并缓存。
- 在多线程情景下,可能存在:X线程已经将值缓存到工作内存中,Y线程改变了主内存的值,但X线程仍使用工作内存中缓存的值(尚未从主内存中同步最新的值)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PXB8DrQX-1687187982997)(../../../AppData/Roaming/Typora/typora-user-images/image-20230619190501097.png)]](https://img-blog.csdnimg.cn/94625a02da3049979c146ff3c772189a.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qHeTfrlK-1687187982998)(../../../AppData/Roaming/Typora/typora-user-images/image-20230619190513191.png)]](https://img-blog.csdnimg.cn/8acb056408e4421b8170291346d621e2.png)
在多线程中,由于各线程会优先从工作内存中获取共享变量的值,可能导致某线程更新了共享变量的值,但其它线程仍使用工作内存中缓存的值,出现属性可见性问题,添加volatile即可解决此问题
4️⃣总结
- 关于
volatile,它是一个关键字,用于修饰类的成员,主要作用是禁止指令重排,确保多线程时属性的可见性 synchronized和volatile均不可替代彼此,虽然两者都是用于解决多线程相关问题的,但问题的情景并不相同,通常,使用synchronized解决的问题大多是“多个线程执行相同的代码”的情景,而使用volatile解决的问题大多是“多个线程执行的代码不同,但使用到了相同的共享变量”的情景- 实际使用原则:当某个属性出现在多个方法中,至少有1个方法会改变该属性的值,且这些方法可能同时被不同的线程执行,则应该为属性添加
volatile关键字
Thread类中的start()和run()方法的区别🍋
1️⃣关于Thread类的start()方法
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0CuXwQ8L-1687187982998)(../../../AppData/Roaming/Typora/typora-user-images/image-20230619190530535.png)]](https://img-blog.csdnimg.cn/8ab304131d6545c2a56861d090354acb.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tqFLqEP6-1687187982999)(../../../AppData/Roaming/Typora/typora-user-images/image-20230619190543681.png)]](https://img-blog.csdnimg.cn/cec1425276a849fdb0968ab53f9a847d.png)
- 是用于启动线程的方法
- 其内部(自动的)调用run()方法
- 通常,每个线程对象只能调用1次该方法
2️⃣关于Thread类的run()方法
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iAK6Op4Q-1687187983000)(../../../AppData/Roaming/Typora/typora-user-images/image-20230619190610463.png)]](https://img-blog.csdnimg.cn/c0e9b327f6d246e1854af51aac583a39.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IRKb8DNm-1687187983001)(../../../AppData/Roaming/Typora/typora-user-images/image-20230619190623060.png)]](https://img-blog.csdnimg.cn/8159336f52d3440b9c9ef93d5ce82c0a.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-weRf6FsV-1687187983001)(../../../AppData/Roaming/Typora/typora-user-images/image-20230619190642799.png)]](https://img-blog.csdnimg.cn/5702576de38747a8a7216c1635300dbc.png)
- 是在线程启动后(自动的)被调用的方法
- 用于编写子线程执行的代码
- 默认的
run()方法会尝试调用Runnable对象(如果存在的话)的run()方法, 否则什么都不执行,也不返回任何值 - 如果你创建线程对象时使用
Runnable对象作为构造方法的参数,当线程启动会调用Runnable对象的run()方法。所以,你应该在Runnable实现类中实现run()方法 - 如果你创建的是
Thread子类的对象,则应该在Thread子类中重写run()方法
3️⃣常见误区
- 误区:Runnable是线程接口
- 解读:
Runnable表示“可执行的”,创建Thread对象时,可以使用Runnable接口类型的对象作为构造方法的参数,并且,在子线程中执行的确实是Runnable实现类中的run()方法,但是,Runnable自身并不是线程接口,事实上,还有许多其它类都可能使用到Runnable,但与线程完全没有关系。
4️⃣总结
- 关于start()方法:
- 是用于启动线程的方法
- 其内部会(自动的)调用run( )方法
- 通常,每个线程对象只能调用1次该方法
- 关于run()方法:
- 是在线程启动后(自动的)被调用的方法
- 用于编写子线程执行的代码
- 默认的run( )方法会尝试调用Runnable对象(如果存在的话)的run()方法,否则,什么都不执行,也不返回任何值
- 使用Runnable接口时,应该实现run( )方法
- 使用Thread子类时,应该重写run()方法
数据库的三范式🍗
范式:Normal Form,可缩写为NF
在设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式,各种范式呈递次规范(例如第1、第2、第3),越高的范式数据库冗余越小
早期提倡的有三大范式,目前已经发展到6个范式,但一般只讨论最初的三大范式即可
1️⃣第一范式 1NF(列不可再分)
- 第一范式(1NF)是指在关系模型中,对于添加的一个规范要求,所有的域都应该是原子性的,即数据库表的每一列都是不可分割的原子数据项,而不能是集合、数组、记录等非原子数据项。即实体中的某个属性有多个值时,必须拆分为不同的属性
- 在符合第一范式(1NF)表中的每个域值只能是实体的一个属性或一个属性的一部分
- 简而言之,第一范式就是无重复的域。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-96UXepww-1687187983002)(../../../AppData/Roaming/Typora/typora-user-images/image-20230619190716979.png)]](https://img-blog.csdnimg.cn/c6a7933d7f104d37bc4889a14fbb642b.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yatE0RZ5-1687187983003)(../../../AppData/Roaming/Typora/typora-user-images/image-20230619190731577.png)]](https://img-blog.csdnimg.cn/c8e1229c7eb242019a354b9d009abd7b.png)
2️⃣第二范式 2NF(该拆就拆)
- 在1NF的基础_上,非码属性必须完全依赖于候选码(在1NF基础上消除非主属性对主码的部分函数依赖)
- 候选码:候选键,任何能保证“唯一性”的字段都可以是候选键,例如在“用户”信息中,身份证号、验证过的手机号都是候选键,任何候选键都可以被选作主键,如果无可用候选键,应创建ID等值不重复的字段
- 简而言之,非主属性不能只依赖主键的一部分
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-o5hOeUA1-1687187983004)(../../../AppData/Roaming/Typora/typora-user-images/image-20230619190741993.png)]](https://img-blog.csdnimg.cn/05071248366f4678aff6af3af08986d2.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nfKGppl7-1687187983004)(../../../AppData/Roaming/Typora/typora-user-images/image-20230619190806948.png)]](https://img-blog.csdnimg.cn/1c33c129b0594b1a97114bcdab7a2163.png)
3️⃣第三范式 3NF(没有传递)
- 在2NF基础上,任何非主属性不依赖于其它非主属性(在2NF基础.上消除传递依赖)
- 传递依赖:A依赖于B,B依赖于C,完整来看,A也是依赖于C的,这个依赖关系是传递过去的
- 简而言之,每列数据都与主键直接相关
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xteAKCYS-1687187983005)(../../../AppData/Roaming/Typora/typora-user-images/image-20230619190821141.png)]](https://img-blog.csdnimg.cn/2cb0aa7065ec4663a5f70f27cbc3058d.png)
解读:在现实中,各“班级”都是归属于“学院”的,即:只要是“JSD001”学院就一定是“软件工程学院”,所以,“学院”依赖于“班级”,形成“非主属性”依赖于另一个“非主属性”的情况,不符合第三范式的要求
- 基于“消除传递依赖”的思想,应该将以上表中的“学院”删除,另创建其它表记录“班级”和“学院”的关系。
4️⃣关于冗余
只要是“可以不存”、“可以使用id表示” 、“存了多次(非id) ”的数据,却直接存储到数据库里,都可以称之为“冗余”
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hIdmXYTL-1687187983006)(../../../AppData/Roaming/Typora/typora-user-images/image-20230619190850706.png)]](https://img-blog.csdnimg.cn/2c702da43f444b8ca8b41e2c55710bfc.png)
冗余的缺点主要在于:
-
占用较多的存储空间:如果可以不存,却存了,肯定多占用了空间,如果可以存id,却存的是较长的字符串,也会多占用存储空间
-
不便于管理维护:如果使用关联,其它表中只存id,当数据需要修改时,只修改数据所在的表即可,如果存的不是id,而是数据本身,则修改时需要将所有表都同时修改,删除也会有类似的问题
-
遵守数据库范式,设计不冗余的数据表,同时,也会把原本冗余的数据表中的数据拆分到多张表中去,导致“单一的数据表不足于表现数据”,如当需要查看订单信息时,仅仅只是查询“订单信息表”是完全不够的,因为即使知道商品id是P001也不知道这到底是什么商品,更不足以显示到软件的界面中去,为了查询到完整的信息,必须查询多张表
-
当表的关联越复杂,查询时需要关联的表就越多,但是,如果采取的是“冗余”的设计方案,只需要查询“订单信息表”这1张表就能查询到完整的信息。
-
可见,即使是“冗余”的设计方案,它也是有优点的,就是“简单! 快!”,所以冗余不一-定是缺点,适当冗余可提高查询性能,所以,数据库范式不是必须完全遵循的,应该根据实际情况来决定!
5️⃣创建数据库的几点建议
- 如果
varchar类型的字段的值的长度相对可控,推荐使用char替代,因为char的效率更高一些 - 尽管
varchar类型的理论长度可达65535,但如果可能超过5000 (部分企业可能约定为其它值),建议将其设计到另张表中去, 并与当前表关联可能建议将字段类型改为text - 可能会在当前表把长字符串值进行截取,便于获取简要信息
- 如果可行,建议使用更小的单位存储更大的数值,避免使用浮点类型,造成运算时的误差,例如价值为“18.52元” 的商品,存储为“1852分”
6️⃣总结
数据库三范式:
- 1NF:在关系模型中,对于添加的一个规范要求,所有的域都应该是原子性的,即数据库表的每一列都是不可分割的原子数据项,而不能是集合,数组,记录等非原子数据项,简单来说就是:列不可再分
- 2NF:在1NF的基础上,非码属性必须完全依赖于候选码,简单来说就是:非主属性不能只依赖主键的一部分
- 3NF:在2NF基础上,任何非主属性不依赖于其它非主属性,简单来说就是:每列数据都与主键直接相关
数据库范式的核心思想包括“消除冗余”,冗余的缺点在于占用较多的存储空间,不便于管理维护。但是,适当冗余可提高查询性能。数据库范式不是必须严格遵守的
依赖注入的几种方式🥫
1️⃣属性注入
在属性的声明之前添加@Autowired注解。该类必须是Spring管理对象的
public class UserController {
@Autowired
private IUserService use rService;
}
- 优点:简单便捷,直观
- 缺点:在属性上使用
@Autowired是不安全的,在执行单元测试(不依赖于任何非测试环境,包括Spring环境, 如果加载了非测试环境,则称之为集成测试)时,由于不加载Spring环境,属性将不会被注入值,则相关代码会出现NPE(NullPointerException),或者,无论是任何原因导致未加载Spring环境的运行,都会导致NPE
2️⃣Setter注入
在需要被Spring调用的Setter方法的声明之前添加@Autowired注解该类必须是Spring管理对象的
public class UserController {
private IUserService userService;
@Autowired
public void setUserService ( IUserService userService) {
this.userService = userService;
}
}
配置类中的@Bean方法也是Spring自动调用的,Spring也会尝试从容器中查找匹配的对象并用于调用@Bean方法
- 优点:直观,相比属性注入,安全性略有提升。即使属性是
private的,在没有加载Spring环境时,也可以手动调用Setter方法以避免出现NPE问题,将属性声明为private是开发规范,应该遵守 - 缺点:相对麻烦,且没有彻底解决安全问题。增减属性都要做相应的调整,如果使用
lombok,源代码中根本没有Setter方法,无法添加注解,在没有加载Spring环境时,如果没有手动调用Setter方法,仍会导致NPE
3️⃣构造方法注入
在需要被Spring调用的构造方法的声明之前添加@Autowired注解该类必须是Spring管理对象的
public class UserController {
private IUserService userService;
@Autowired
public UserController(IUserService userService) {
this.userService = userService;
}
}
仅当类中有多个构造方法时才需要添加该注解,如果仅有1个构造方法,Spring会自动调用
- 优点:能保障安全性,如果构造方法是唯一的,任何环境下都是必须调用的,不会出现在
NPE问题 - 缺点:不直观,相对麻烦,构造方法的参数列表可能很长,必须结合构造方法,才可以明确哪些属性将被注入值,必须保证构造方法唯一,增减属性都要做相应的调整
使用@Autowired时,可以通过属性注入、Setter注 入和构造方法注入这3种方式,Spring本身并不关心你使用哪种方式,只要使用方式没有问题,都是可以装配的
- 理论上的选取原则:构造方法注入> Setter注入> 属性注入
- 如果构造方法是唯一的,任何环境下都是必须调用的,不会出现在
NPE问题 - 如果属性是
private的,有Setter方法时,即使不加载Spring环境,也可以手动调用,以避免出现NPE问题 - 如果属性是
private的,没有可为属性赋值的构造方法,也没有Setter方法,当不加载Spring环境时,必然出现NPE问题
- 如果构造方法是唯一的,任何环境下都是必须调用的,不会出现在
- 到底使用
Setter注入还是构造方法注入,Spring官方在VSP(VMware Spring Professional)培训文档中明确指出:Spring doesn't care (can use either), Constructor injection is generally preferred
4️⃣总结
- 使用Spring实现依赖注入时,可实现的方式有3种:属性注入,Setter注入, 构造方法注入
- 如果项目对代码安全性的要求不是特别高,可以使用属性注入,因为编写代码非常便利,并且直观,哪些属性会被注入值,一目了然,但这种做法并不安全当不加载Spring环境时,例如执行单元测试时,会出现
NPE问题,即出现安全问题 Setter注入方式比较中庸,并且使用lombok时不可行,并不推荐使用- 理想的方式是使用构造方法注入,可以彻底杜绝
NPE安全问题,但是需要保证类中仅有1个将用于对各需要注入值的属性赋值的构造方法,而且,会导致构造方法的参数列表可能很长,并且,必须结合构造方法,才可以明确哪些属性将被注入值,增减属性都需要做相应的调整。总的来说,相对麻烦,编写代码成本略高,总的来说,虽然安全,但缺点也比较多,是对代码安全性的要求非常高时的唯一方案
@Autowired和@Resource的区别🍣
1️⃣共同点
-
在使用Spring框架及基于它的进阶框架(
Spring MVC、Spring Security、Spring Boot)时,多可以实现自动装配public class UserController{ @Autowired private IUserService userService; }public class UserController{ @Resource private IUserService userService; } -
都可以用于属性或
Setter方法,以实现装配public class UserController{ @Autowired //或 @Resource 等效 private IUserService userService; }public class UserController{ private IUserService userService; @Autowired //或 @Resource 等效 public void setUserService(IUserService userService){ this.userService = userService; } }
2️⃣区别
- 定义:
@Autowired是Spring框架中定义的注解- 仅当使用Spring框架时才可以使用,主流的开发模式下,都会使用Spring框架,该约束影响不大
@Resource是javax包的注解- JSR-250标准,在EJB 3.0 和 Spring中均可使用
- 构造方法:
@Autowired可以添加构造方法的声明之前@Resource不可以添加在构造方法的声明之前@Resource还可以添加在类的声明之前,但不会装配属性的值
- 装配顺序:
@Autowired是先尝试根据类型装配,再尝试根据名称进行装配- 先查找匹配类型的对象的数量
- 1个:直接装配
- 0个:判断
@Autowired的required属性:ture:抛出异常,false不装配,即属性值为null - 超过1个:尝试根据名称装配:存在符合的对象:装配,不存在符合的对象:抛出异常
- 先查找匹配类型的对象的数量
@Resource是先尝试根据名称装配,再尝试根据类型装配:能装配,则装配,最后仍然装配不了的则抛出异常
3️⃣常见误区
-
误区:使用
@Resource取代@Autowired -
误区产生原因:
- 有时候使用
@Autowired会报错,但是使用@Resource不会 - 好像听说过不要在属性上使用
@Autowired注解
- 有时候使用
-
解读:以
IntelliJ IDEA v2020.1.4为例,当尝试注入使用Mybatis时定义的接口对象时,添加@Autowired会报错(无此对象),但是使用@Resource不会![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iJDvSBqx-1687187983006)(../../../AppData/Roaming/Typora/typora-user-images/image-20230619193450850.png)]](https://img-blog.csdnimg.cn/1916f109f38a4100be72e264662bb2f7.png)
这是由于某些版本的
IntelliJ IDEA的误判导致的,事实上,这样的代码(正在报错)可以正常运行,或者,将此代码导入到Eclipse等其它开发工具中,并不会提示任何错误,也可以正常运行。并且,当你在持久层(存储层)接口的声明之前添加@Repository注解后,在lntelliJIDEA中使用@Autowired时的错误也就消失了。![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CGOkIFyL-1687187983007)(../../../AppData/Roaming/Typora/typora-user-images/image-20230619193759662.png)]](https://img-blog.csdnimg.cn/cb3f031f3d1148a489f99686e805adcf.png)
以
IntelliJlDEA v2020.1.4为例,当项目中使用Spring Security,且尝试使用@Autowired注入UserDetailsService类型的对象时提示错误(有多个同类型对象),但是使用@Resource不会解决:补充
@Qualifier注解,或将类型声明为UserDetailsService接口的实现类的类型,将不再提示错误![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5chAJXsw-1687187983008)(../../../AppData/Roaming/Typora/typora-user-images/image-20230619193949744.png)]](https://img-blog.csdnimg.cn/e1a10f3233fb491398c9fa1d2151f10c.png)
在属性上使用
@Autowired确实是不安全的,在执行单元测试(不依赖于任何非测试环境,包括Spring环境,如界加载了非测试环境,则称为:集成测试)时,由于不加载Spring环境,属性将不会注入值,则相关代码会出现(NullPointerException),或者,无论是任何原因导致未加载Spring环境的运行,都会导致NPE,在面临这样的问题时,即使改为使用@Resource也不会有任何变化。正确的做法是使用构造方法注入,而不是使用@Resource替换@Autowired
4️⃣引申
关于使用构造方法注入属性的值:
-
如果当前类仅有1个构造方法,Spring会自动调用,无论它有多少参数
- Spring会自动从容器中使用匹配的参数
-
如果当前类中有多个构造方法(超过1个),你应该在你希望Spring调用的构造方法的声明之前添加
@Autowired注解,否则,Spring会自动调用无参数的构造方法,如果既没有无参数的构造方法,也没有使用@Autowired注解,则会报错![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-15Ri2jir-1687187983008)(../../../AppData/Roaming/Typora/typora-user-images/image-20230619194805910.png)]](https://img-blog.csdnimg.cn/0560123963134b4db929dcd8c0d36720.png)
-
当使用
@Resource装配属性的值时,如果存在多个类型相同的对象,且名称均不匹配,可以配置注解属性name的值,以指定某个对象public class UserServiceImpl { @Resource( name = "userJdbcRepository") private IUserRepository userRepository; } -
当使用
@Autowired装配属性的值时,如果存在多个类型相同的对象,且名称均不匹配,需要结合@Qualifier一起使用public class UserServiceImpl { @Autowired @Qualifier("userJdbcRepository") private IUserRepository userRepository; }public class UserServiceImpl { private IUserRepository userRepository; @Autowired public void setUserRepository( @Qualifier("userJdbcRepository") IUserRepository userRepository){ this.userRepository = userRepository } } -
使用
@Autowired时,可以通过属性注入、Setter注入和构造万法注入以3种方式,Spring本身并不关心你使用哪种万式,只要使用方式没问题,都可以装配。 -
理论上的选取原则:构造方法注入> Setter注入>属性注入
- 如果构造方法是唯一的,任何环境下都是必须调用的,不会出现在NPE问题
- 如果属性是
private的,有Setter方法时,即使不加载Spring环境,也可以手动调用,以避免出现NPE问题 - 如果属性是
private的,没有可为属性赋值的构造方法,也没有Setter方法,当不加载Spring环境时,必然出现NPE问题
-
到底使用
Setter注入还是构造方法注入,Spring5官方在VSP培训文档中明确指出:Spring doesn't care (can use either),Constructorinjection is generally preferred
5️⃣总结
- 相同之处:
- 都可以实现自动装配
- 都可以用于属性或Setter方法,以实现装配
- 不同之处:
@Autowired是Spring框架中定义的注解,@Resource是javax包中的注解@Autowired可用于构造方法,@Resource不可以- 当Spring容器中存在多个相同类型的对象,在自动注入时,需要根据名称匹配,使用
@Autowired必须结合@Qualifer注解以指定Bean id/name,用于属性时,在属性的声明之前同时添加这2个注解,用于方法时,在方法的声明之前添加@Autowired,在方法的参数之前添加@Qualifier注解,而使用@Resource时则是配置该注解的name属性 @Autowired是先尝试根据类型装配,再尝试根据名称进行装配先查找匹配类型的对象的数量- 1个:直接装配
- 0个:判断
@Autowired的required属性:- true,抛出异常
- false,不装配,即属性值为null
- 超过1个:尝试根据名称装配
- 存在符合的对象:装配
- 不存在符合的对象:抛出异常
@Resource是先尝试根据名称装配,再尝试根据类型装配一能装配,则装配,最后仍装配不了,则抛也异常
- 实际使用原则:
- 由于自动装配是Spring的机制,
@Autowired也是Spring的注解,所以,优先使用@Autowired实现装配,而@Resource注解是javax包中的,则不优先考虑 - 应该为类添加带参数的构造方法,用于为各个需要注入值的属性赋值,并且保证这是类中唯一的构造方法,或在构造方法的声明之前添加
@Autowired注解,则Spring会自动调用它,这样做可以避免单元测试时出现NPE问题 - 如果在Spring容器中存在多个与需要装配的属性的类型相同的对象,应该结合
@Qualifier注解一起使用,以显式的指定Bean id/name - 在追求编写代码的便利性时,可能会在属性声明之前使用
@Autowired注解,以实现自动装配,如果要装配的是持久层(存储层)接口类型的对象,并且该接口对象是框架自动生成的,应该在接口的声明之前添加@Repository注解,以避免某些版本的IntelliJlDEA报错
- 由于自动装配是Spring的机制,
Mybatis的优点和缺点🍠
1️⃣优点
- 不需要编写繁琐的实现过程,很大程度的减少了开发人员需要编写的代码量
- 例如:不需要自行获取
Connection、Statement / PreparedStatement等,所有的具体实现代码都不需要编写 - 提示:只要是使用Java语言实现数据库编程,其底层一定是通过JDBC实现的
- 例如:不需要自行获取
- 基于接口编程
- 你在使用
Mybatis时需要声明各数据访问功能的接口与抽象方法 - 即使项目不再使用
Mybatis实现,接口和抽象方法并不需要调整
- 你在使用
- 解耦SQL语句
- 可以使用专门的XML文件管理SQL语句,与Java代码分离开来
Mybatis也支持将SQL语句写在抽象方法的@lnsert等注解中,但不推荐
- 与Spring系列框架(Spring / Spring Boot)高度集成
- 只需要极简的配置即可使用
- 提示:在没有Spring的情况下,
Mybatis也可以使用,但需要编写较多配置
- 支持预编译,杜绝出现SQL注入问题
- 各参数可以使用
#{}格式的占位符,其实现本质是通过PreparedStatement实现了SQL语句的预编译
- 各参数可以使用
- SQL代码片段可以复用
- 在XML中,可以使用
<sql>节点编写代码片段,在其它位置可以复用 - 典型的应用场景:一些常用的字段列表、一些复杂的where子句
- 在XML中,可以使用
- 支持自定义ORM映射,自动封装查询结果
- 数据表的字段名与封装结果的类中的属性名可能不完全一致,可以自行配置
<resultMap>节点,以配置字段名与属性名的映射
- 数据表的字段名与封装结果的类中的属性名可能不完全一致,可以自行配置
- 支持动态SQL
- 可以使用
<if>、<foreach>等标签使用动态SQL
- 可以使用
2️⃣缺点
- 需要编写大量的SQL语句
- 某些不需要编写SQL语句的数据库编程框架没有这样的问题
- 例如:JPA,可根据规范的方法名生成SQL语句
- 数据库移植性较差
- 不同的数据库的SQL语句可能不同,如果更换数据库,则原SQL语句可能需要调整
- 某些不需要编写SQL语句的数据库编程框架没有这样的问题,如:JPA
3️⃣理性看待缺点
- 关于
Mybatis的缺点,主要集中在“需要编写SQL语句”方面,它确实导致了编写代码量较多、数据库移植性较差的问题,但是,这也是缺点的同时,也是优点。SQL语句的执行效率是非常重要的,由框架生成的SQL语句都是模版化的,其执行效率必然低于自定义SQL语句的执行效率,所以,“不需要编写SQL语句”虽然可以减少编写的代码量,也可以解决数据库移植性的问题,但却带米了“执仃效率偏低”的问题 - 提示:即使JPA不需要编写SQL语句,但也提供了自定义SQL语句的机制,所以使用JPA时,既可以通过规范的方法名来生成SQL语句,也可以通过
@Query注解自定义SQL语句,为了保证执行效率,使用JPA时也应该自行编写SQL语句,其它可以不需要编写SQL语句的数据库编程框架也大多是这样 - 目前,中国作者
baomidou开发了Mybatis-Plus框架,很好的解决了Mybatis的缺点,你只需要将你使用Mybatis时创建的接口继承自该框架的接口,并添加简单的配置(关于Mybaits-Plus的配置),即可得到常规的数据访问功能。Mybaits-Plus在追求编码效率时,完全不需要编写常规的数据访问功能,在追求执行效率时,依然按照Mybatis的使用方式即可,开发人员可以自主选择
4️⃣总结
Mybatis的优点有:- 不需要编写繁琐的实现过程,很大程度的减少了开发人员需要编写的代码量
- 基于接口编程
- 解耦SQL语句
- 与Spring系列框架(Spring / Spring Boot)高度集成
- 支持预编译,杜绝出现SQL注入问题
- SQL代码片段可以复用
- 支持自定义ORM映射,自动封装查询结果
- 支持动态SQL
Mybatis的缺点有:- 需要编写大量的SQL语句
- 数据库移植性较差
Mybatis的缺点并不是严重问题,编写SQL语句的工作量,在整个项目开发中占比并不大,一般也极少更换数据库,并且,这个缺点可以通过Mybatis-Plus来弥补,在实际应用中,简单的数据访问功能直接使用Mybatis-Plus提供的功能即可,完全不需要自行编写,相比复杂的数据访问则自行编写
Mybatis的#{}和${}的区别🍏
1️⃣共同点
都写在SQL语句中,都用于表示参数值
<select id="findById" resultMap="BaseResultMap">
select * from user where id=#{id}
</select>
<select id="findById" resultMap="BaseResultMap">
select * from user where id=${id}
</select>
2️⃣SQL注入
SQL语句中存在一些参数,在实际运行时,传入的参数值可能改变语义,导致执行的SOL语句与预期的(设计的)不同
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-A6dOYPaB-1687187983009)(../../../AppData/Roaming/Typora/typora-user-images/image-20230619222911465.png)]](https://img-blog.csdnimg.cn/9b79ecb7321e4902b3ac48e9b83e5ba7.png)
3️⃣预编译
- 编译:无论是哪种语言的源代码,在执行之前,都必须经过编译
- 编译之前,会进行相关的检查,例如:词法分析、语义分析,仅当能够通过这些检查才可以编译
- 预编译:在尚未确定某些值的情况下执行编译
- 尽管值是未知的,但是其语法结构是合法的,并不影响编译器理解这条语句一例
- 如:
select * from user where id=? - 值只影响执行结果,并不影响编译
- 如:
- SOL语句一旦经过预编译,将不存在SQL注入风险
- 编译之前已经确定语义,无论参数值是什么样的,都不会改变语义
- 尽管值是未知的,但是其语法结构是合法的,并不影响编译器理解这条语句一例
4️⃣Mybatis的#{}占位符
Mybatis在处理SQL语句中的#{}占位符时,会将其替换成问号,并通过预编译的方式(使用PreparedStatement)进行处理的
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CjS1sCjl-1687187983009)(../../../AppData/Roaming/Typora/typora-user-images/image-20230619222459255.png)]](https://img-blog.csdnimg.cn/5010c94af7e94a009a9d454eec4b7a4c.png)
- 只可以表示某个值,不可以表示SQL语句中的某个片段
- 是预编译的
- 在不考虑参数的值是多少的情况下,SQL语句必须是合法的
- 不需要考虑参数值的数据类型
- 例如:不需要在字符串类型的值的两侧添加单引号
- 代入值之前已经预编译,语义已经确定,则不存在SQL注入风险
5️⃣Mybatis的${}占位符
Mybatis在处理SQL语句中的${}占位符时,是单纯的把占位符替换成参数值,再进行后续的处理
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HjcakUZt-1687187983010)(../../../AppData/Roaming/Typora/typora-user-images/image-20230619222558616.png)]](https://img-blog.csdnimg.cn/1cbd1a774fb944ef87ac51594afaabdc.png)
- 可以表示SQL语句中的任何片段,只需要保证最终拼接出来的SQL语句是合法的
- 需要考虑参数值的数据类型
- 例如:需要在字符串类型的值的两侧添加单引号
- 需要考虑SQL注入的风险
- 参数的值可能改变语义
- 可以在执行SQL语句之前进行检查
- 需要考虑参数值的数据类型
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4qtsW77S-1687187983011)(../../../AppData/Roaming/Typora/typora-user-images/image-20230619222841700.png)]](https://img-blog.csdnimg.cn/8cf92d060cab4846824c20c935c34641.png)
6️⃣总结
- 相同之处:都是写在SQL语句中,都是用于表示参数值的
- 不同之处:
#{}格式的占位符将被替换为问号,是通过预编译进行处理的,所以,使用#{}只能表示某个值,而不能表示SQL语句中的某个片段,同时,由于是预编译的,所以不需要考虑参数值的数据类型问题,也没有SQL注入风险${}格式的占位符将直接被替换为参数值,所以,只要保证最终得到的SQL语句是合法的,它可以表示SQL语句中的任何片段,但是,需要考虑参数值中涉及的各值的数据类型,例如字符串类型的值需要在两侧添加单引号,并且,由于在编译SQL语句之前就已经将参数值添加到SQL语句中了,需要考虑SQL注入的风险
- 实际使用原则:因为使用
${}格式的占位符有SQL注入风险,如果执行数据访问之前没有对参数进行完整的检验,是不安全的,并且,还要考虑各值的数据类型问题,相对麻烦,所以,一般使用#{}格式的占位符。
SpringBoot的核心注解有那些🥕
1️⃣注意事项
Spring Boot是基于Spring框架的,理论上来说,Spring框架已经定义的注解,不应该归类于“Spring Boot的核心注解”- 例如:
@Configuration、@Autowired等
- 例如:
Spring Boot没有添加Web的starter时,并不包含Spring MVC框架的相关技术,所以,Spring MVC框架定义的注解,也不应该归类于“Spring Boot的核心注解”- 例如:
@RestController、@GetMapping等
- 例如:
- 其它需要添加
starter才被集成的框架也是同理
2️⃣核心注解
@SpringBootApplication
@SpringBootApplication:每个Spring Boot项目中的启动类都应该添加@SpringBootApplication注解。每个基于Spring Boot的项目或Module应该有且仅有1个类添加该注解
@SpringBootApplication
public class SpringBootDemoApplication {}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XsdhtQ6Z-1687187983012)(../../../AppData/Roaming/Typora/typora-user-images/image-20230619225319189.png)]](https://img-blog.csdnimg.cn/cce6163775f54e3abc796aaeb33d6dd4.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jvJG405g-1687187983013)(../../../AppData/Roaming/Typora/typora-user-images/image-20230619225331714.png)]](https://img-blog.csdnimg.cn/80f2711e4ff9443eb712876c52fb79f3.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kSg6IyBq-1687187983013)(../../../AppData/Roaming/Typora/typora-user-images/image-20230619225449951.png)]](https://img-blog.csdnimg.cn/6fd95ec4420549429411b8cdccd26dc6.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7NKBGwbW-1687187983014)(../../../AppData/Roaming/Typora/typora-user-images/image-20230619225535369.png)]](https://img-blog.csdnimg.cn/e5c0d0d2a8ea47fcbd9b9849d7693514.png)
注意:@SpringBootConfiguration、@EnableAutoConfiguration也应该归类为Spring Boot特有注解
@SpringBootTest
在Spring Boot项目的每个测试类之前都应该添加@SpringBootTest注解,在执行测试(执行整个测试类,或任何一个测试方法)之前,都会加载Spring Boot的自动配置、自定义配置,在执行测试之后,会释放这些资源。如果测试不需要加载Spring Boot的自动配置(包括自定义配置),则不需要添加该注解
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4UiKzWSC-1687187983015)(../../../AppData/Roaming/Typora/typora-user-images/image-20230619225915633.png)]](https://img-blog.csdnimg.cn/40f6777eba904a65aae0c4b7a33a2f49.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vkoyvsjr-1687187983015)(../../../AppData/Roaming/Typora/typora-user-images/image-20230619225927171.png)]](https://img-blog.csdnimg.cn/0975a5faf8d64a7dadc3168b99c82429.png)
3️⃣总结
Spring Boot的核心注解有:
@SpringBootApplication- 添加在启动类的声明之前
- 每个基于
Spring Boot的项目或Module应该有且仅有1个类添加该注解 - 使得启动类是配置类
- 启用自动配置,将加载默认配置和自定义配置
- 启用组件扫描
- 可以通过配置注解参数,排除某些可能自动加载的配置类
- 可以通过配置注解参数,指定组件扫描的根包
@SpringBootConfiguration- 是
@SpringBootApplication的元注解。 - 元注解中包括
@Configuration,使得添加了@SpringBootApplication注解的类是启动类的同时还是配置类
- 是
@EnableAutoConfiguration- 启用自动配置,将加载默认配置和自定义配置
@SpringBootTest- 在
Spring Boot项目的每个测试类之前都应该添加@SpringBootTest注解,在执行测试(执行整个测试类,或任何一个测试方法)之前,都会加载SpringBoot的自动配置、自定义配置,在执行测试之后,会释放这些资源 - 如果你的测试不需要加载
Spring Boot的自动配置(包括自定义配置),则不需要添加该注解 - 可以通过注解参数加载特定的配置(
Properties) - 可以通过配置参数加载特定的
ApplicationContext组件类 - 可以通过配置参数配置
Web测试环境
- 在
SpringBoot的常用starter有那些🥘
1️⃣starter的概念
基于Spring / Spring MVC等基础框架的项目,在创建出来之后,在编写代码之前,需要完成许多配置,在Spring Boot中,设计了许多starter,用于整合SpringBoot和其它基础框架,完成通用配置,并且,当启动Spring Boot项目时,会自动加载这些配置,使得各框架“开箱即用”
- 简单来说,各
starter既包含了所使用的依赖,也包含了通用配置 - 以
Mybatis为例,在使用Spring框架进行整合时,需要自行配置DataSource、SqlSessionFactoryBean等,在Spring Boot中,添加了对应的starter之后,不必自行配置,甚至其它配置(例如连接数据库的参数)也只需要按照指定的属性名称来配置值,并不需要自行读取配置
2️⃣提示
如果在面试时,面试官出了这道题,其考察的目标应该是“你用过哪些starter”,以了解你在开发时使用到了哪些技术
3️⃣常用的starter
spring-boot-starter-web:用于整合Spring MVCspring-boot-starter-test:用于整合JUnit及相关测试环境spring-boot-starter-freemarker:使用Mybatis Plus Generator时将需要spring-boot-starter-validation:用于整合Hibernate Validator来检验请求参数的有效性spring-boot-starter-thymeleaf:用于整合Thymeleaf,仅当“非响应正文”时使用spring-boot-starter-security:用于整合Spring Securityspring-boot-starter-data-redis:用于整合Spring Data Redis,处理项目中使用Redis缓存数据spring-boot-starter-data-elasticsearch:用于整合Spring Data ElasticSearch,处理项目中使用ElasticSearch实现搜索功能Spring Cloud相关框架的starter:- 服务发现:
spring-cloud-starter-netflix-eureka-server:用于整合Spring Cloud中的Eureka服务器端spring-cloud-starter-netflix-eureka-client:用于整合Spring Cloud中的Eureka客户端- 提示:如果使用的“服务发现框架”不是
Eureka,请更换为你使用的,如Nacos
- 网关:
spring-cloud-starter-netflix-zuul:用于整合Spring Cloud中的Zuul,实现网关路由等功能- 提示:如果使用的“网关框架”不是
Zuul,请更换为你使用的,如Gateway
- 服务发现:
mybatis-spring-boot-starter:用于整合Mybatis,由于不是Spring Boot团队开发的,所以命名风格略有不同pagehelper-spring-boot-starter:用于整合Page Helper,处理Mybatis查询分页,由于不是Spring Boot团队开发的,所以命名风格略有不同