业务背景
根据央行公布的数据显示,全国性银行信用卡和借贷合一卡的发卡量增速从2017年同比增速26.35%的高点逐年下降,截至2020年同比增速降至4.26%。银行信用卡发卡增速明显放缓的背景下,预防老客户流失的问题变得愈发重要。
假设一家消费信用卡银行的业务经理正面临客户流失的问题。经理希望分析数据,找出背后的原因,并利用这些数据来预测可能会流失的客户。经理还试图找到流失客户的主要特征,提出降低客户流失的建议。

描述性统计
在这个项目中,我们将建立一个预测信用卡流失的人工神经网络模型。
此业务问题的首要任务是确定正在流失的客户。
即使我们将非流失客户预测为流失,也不会损害我们的业务。
但是,将流失客户预测为非流失客户就可以了。
所以召回率(TP/TP+FN)需要更高。
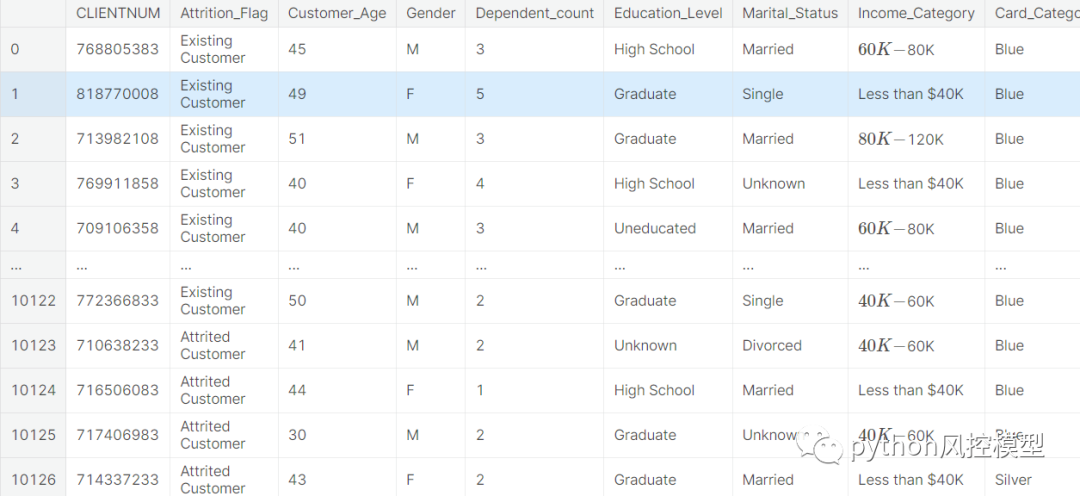
该数据集由 10,000 个客户(条目)组成,
他们提到了他们的年龄、薪水、婚姻状况、信用卡限额、信用卡类别等。
因此,这 19 个属性(特征)将是我们对神经网络的输入。
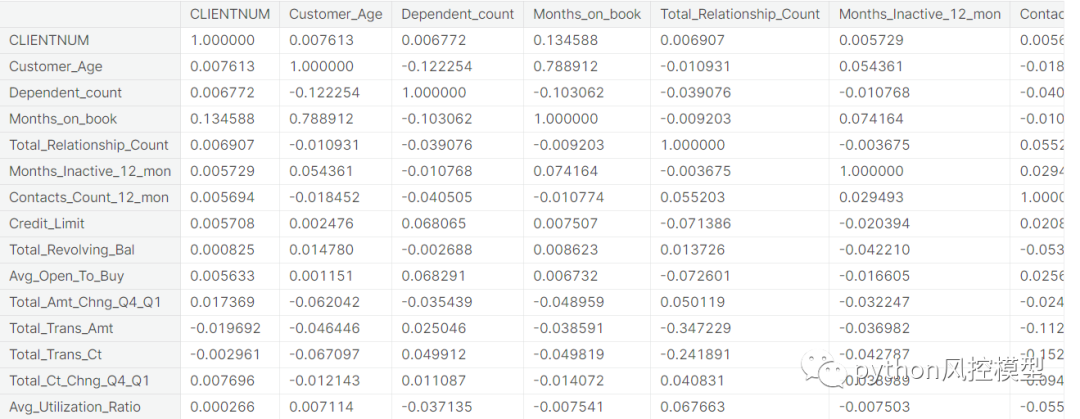
下图为变量相关性分析
下图为变量的直方图可视化
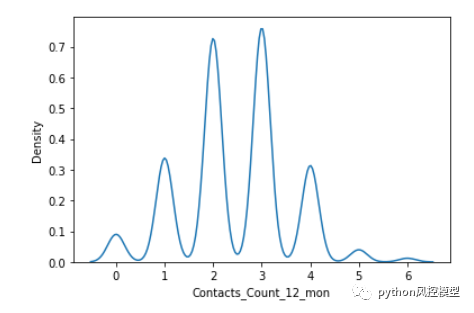
这是对单变量一年合同总数的KDE绘图。
由于数据集具有多种格式的特征;主要是字符串和整数,它需要准备。
我们只有 16.07% 的客户放弃了信用卡服务。
因此,我们有一个不平衡的数据集。
为了处理这种不平衡,我们将为两类目标变量分配权重以使其平衡。
我们通过将特征列中的字符串变量替换为整数来为 ANN 准备数据集,
我们还删除了“CLIENTNUM”列,因为它不是会影响目标变量的特征。
#%% Importing Librariesimport matplotlib.pyplot as pltimport pandas as pdimport numpy as npimport seaborn as snsfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScaler, RobustScaler,MinMaxScalerfrom sklearn.metrics import accuracy_score,confusion_matrix,f1_score,matthews_corrcoef,precision_score,recall_scorefrom tensorflow.keras.layers import Densefrom tensorflow.keras.models import Sequentialfrom sklearn.utils import class_weight#%% Loading the Datasetdf = pd.read_csv('C:/Users/Sahil Bagwe/Desktop/Python/dataset/Bank/BankChurners.csv')df = df.drop(df.columns[21:23],axis=1)df=df.drop('CLIENTNUM',axis=1)#%% Preparing the Datasetdf['Gender'].replace('M',1,inplace = True)df['Gender'].replace('F',0,inplace = True)df['Education_Level'].replace('Unknown',0,inplace = True)df['Education_Level'].replace('Uneducated',1,inplace = True)df['Education_Level'].replace('High School',2,inplace = True)df['Education_Level'].replace('College',3,inplace = True)df['Education_Level'].replace('Graduate',4,inplace = True)df['Education_Level'].replace('Post-Graduate',5,inplace = True)df['Education_Level'].replace('Doctorate',6,inplace = True)df['Marital_Status'].replace('Unknown',0,inplace = True)df['Marital_Status'].replace('Single',1,inplace = True)df['Marital_Status'].replace('Married',2,inplace = True)df['Marital_Status'].replace('Divorced',3,inplace = True)df['Card_Category'].replace('Blue',0,inplace = True)df['Card_Category'].replace('Gold',1,inplace = True)df['Card_Category'].replace('Silver',2,inplace = True)df['Card_Category'].replace('Platinum',3,inplace = True)df['Income_Category'].replace('Unknown',0,inplace = True)df['Income_Category'].replace('Less than $40K',1,inplace = True)df['Income_Category'].replace('$40K - $60K',2,inplace = True)df['Income_Category'].replace('$60K - $80K',3,inplace = True)df['Income_Category'].replace('$80K - $120K',4,inplace = True)df['Income_Category'].replace('$120K +',5,inplace = True)df['Attrition_Flag'].replace('Existing Customer',0,inplace = True)df['Attrition_Flag'].replace('Attrited Customer',1,inplace = True)
预处理数据集
我们通过将数据集拆分为特征矩阵(x)和目标变量(y)来开始这个阶段。由于数据的值变化很大,因此有必要对这些值进行缩放以标准化这些值的范围。Robust Scaler 移除中位数并根据分位数范围(默认为 IQR:Interquartile Range)缩放数据。IQR 是第一个四分位数(第 25 个分位数)和第三个四分位数(第 75 个分位数)之间的范围。
构建人工神经网络
由于数据集是不平衡的,我们需要为其分配类别权重。
这是通过计算流失客户与客户总数的比率来完成的。
接下来,我们构建一个 3 层神经网络。
输入层包含的神经元数量与特征矩阵中的列数相同。
输出层由一个预测输出的层组成,即 1 表示流失客户,0 表示现有客户。
隐藏层的神经元数通常是介于输入层和输出层神经元数之间的一个值。
将隐藏层中的神经元数取为输入层和输出层中神经元的平均值被认为是安全的。
#%% Assigning weights to classescw = class_weight.compute_class_weight('balanced', np.unique(Y_train), Y_train)a = y.value_counts()ratio = a[1]/(a[1]+a[0])weights = [ratio, 1-ratio]#%% Building the Modelmodel = Sequential()model.add(Dense(19,activation="sigmoid"))model.add(Dense(10,activation="sigmoid"))model.add(Dense(1))model.compile(optimizer='rmsprop',loss = "binary_crossentropy",metrics=["BinaryAccuracy"],loss_weights=weights)
预测客户流失
由于数据集是不平衡的,我们需要为其分配类别权重。
这是通过计算流失客户与客户总数的比率来完成的。
接下来,我们构建一个 3 层神经网络。
输入层包含的神经元数量与特征矩阵中的列数相同。
输出层由一个预测输出的层组成,即 1 表示流失客户,0 表示现有客户。
隐藏层的神经元数通常是介于输入层和输出层神经元数之间的一个值。
将隐藏层中的神经元数取为输入层和输出层中神经元的平均值被认为是安全的。
#%% Predictinghistory = model.fit(x=X_train,y=Y_train,epochs=100, class_weight = {0:cw[0], 1:cw[1]})predictions = model.predict_classes(X_test)
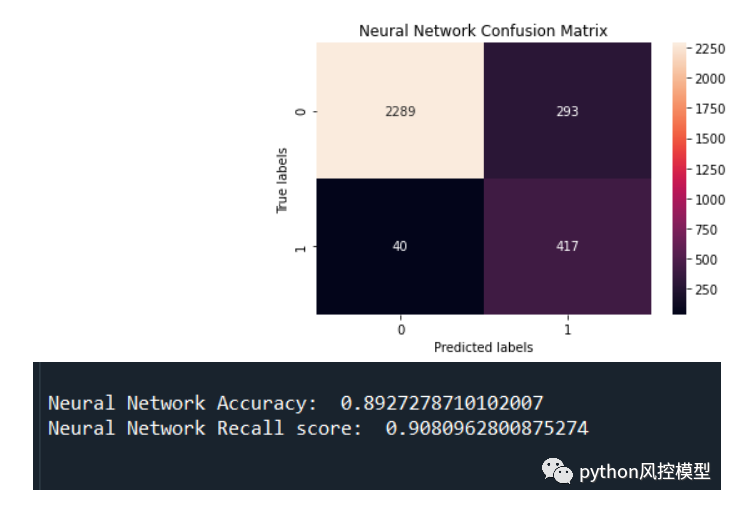
通过模型验证,accuracy准确率达到0.89,召回率达到0.9,这是非常不错模型性能。
预测银行信用卡流失模型就为大家介绍到这里,《python金融风控评分卡模型和数据分析(加强版)》更多实战案例会定期更新,用于银行培训,大家扫一扫下面二维码,记得收藏课程。我们公司提供一对一机器学习模型定制服务,如果你需要建模项目定制服务,可留言。
版权声明:文章来自公众号(python风控模型),未经许可,不得抄袭。遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。