来源:投稿 作者:橡皮
编辑:学姐

论文链接:https://arxiv.org/pdf/2211.11317
0.背景:
工业异常检测旨在发现产品的异常区域,在工业质量检测中发挥着重要作用。在工业场景中,很容易获得大量的正常示例,但缺陷示例很少。
大多数现有的工业异常检测方法都是基于2D图像的。然而,在工业产品的质量检查中,人类检查员利用3D形状和颜色特征来确定它是否是缺陷产品,其中3D形状信息对于判断是重要和必要的。
无监督异常检测的核心思想是找出异常和正态表示之间的区别。目前2D工业异常检测方法可分为两类:
(1)基于重构的方法。图像重建任务被广泛用于异常检测方法中,以学习正常表示。基于重建的方法对于单模态输入(2D图像或3D点云)很容易实现。但对于多模态输入,很难找到重建目标。
(2) 基于预训练特征提取器的方法。利用特征提取器的直观方法是将提取的特征映射到正态分布,并将分布外的特征作为异常。
1.主要贡献:
-
提出了一种去噪学生编码器-解码器,它经过训练,可以从具有异常输入的教师那里显式地生成不同的特征表示。
-
使用分割网络来自适应地融合多级特征相似性,以取代经验推理方法。
-
在基准数据集上进行了广泛的实验,以证明我们的方法对各种任务的有效性。
2.网络介绍: DeSTSeg
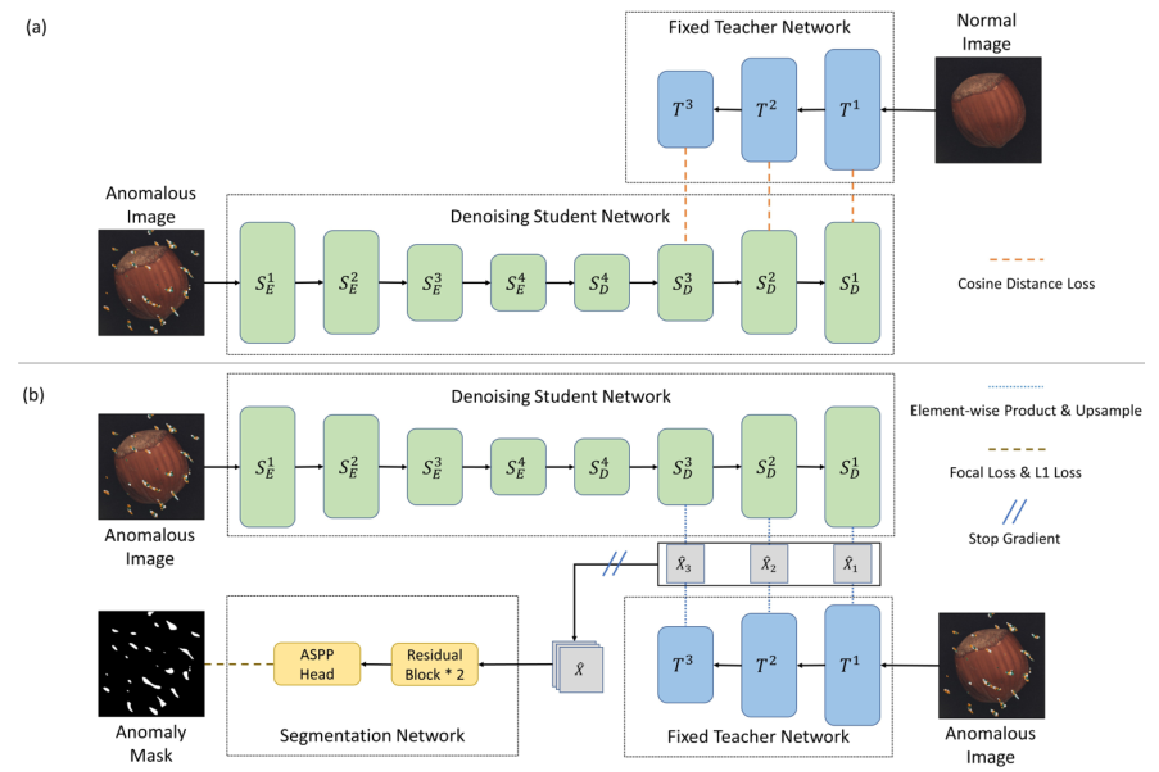
在训练期间生成并使用合成的异常图像。在第一步骤(a)中,训练具有合成输入的学生网络,以从干净的图像生成与教师网络类似的特征表示。在第二步(b)中,学生和教师网络的归一化输出的元素乘积被级联并用于训练分割网络。分割输出是预测的异常得分图。
3.方法细节:原理概览
-
所提出的 DeSTSeg 由三个主要组件组成:预先训练的教师网络、去噪的学生网络和分割网络。
-
将合成异常引入到正常训练图像中,并分两步训练模型。
-
在第一步中,模拟的异常图像被用作学生网络的输入,而原始的干净图像被用作教师网络的输入。教师网络的权重是固定的,但用于去噪的学生网络是可训练的。
-
在第二步中,学生模型也是固定的。学生网络和教师网络都以合成的异常图像作为输入,以优化分割网络中的参数来定位异常区域。
-
为了推断,以端到端模式生成像素级异常图,并且可以通过后处理来计算相应的图像级异常分数。
3.1方法细节: Synthetic Anomaly Generation 合成异常生成
我们模型的训练依赖于使用 [Draem] 中提出的相同算法生成的合成异常图像。生成随机二维Perlin噪声,并通过预设阈值进行二值化以获得异常掩模 M。通过用无异常图像和来自外部数据源A的任意图像的线性组合替换掩模区域来生成异常图像
,其中不透明度因子β在[0.15,1]之间随机选择:
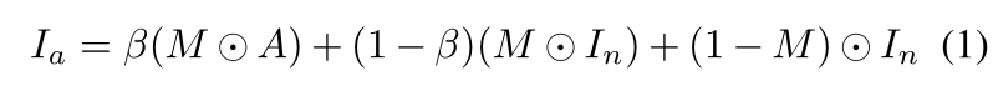
表示逐元素乘法运算。异常生成在训练期间在线执行。通过使用该算法,介绍了三个优点。
首先,与绘制矩形异常掩模相比,随机Perlin噪声生成的异常掩模更不规则,与实际异常形状相似。 其次,用作异常内容A的图像可以在没有精心选择的情况下任意选择。 第三,引入不透明度因子β可以被视为数据扩充,以有效增加训练集的多样性。
3.2方法细节:Denoising Student-Teacher Network 去噪教师学生网络
在以前的多层次知识蒸馏方法中,学生网络(正常图像)的输入与教师网络的输入相同,学生网络的架构也是如此。然而,提出的去噪学生网络和教师网络以成对的异常和正常图像作为输入,去噪学生网络具有不同的编码器-编码器架构。在接下来的两段中,我们将研究这种设计的动机。
首先,建立优化目标,以鼓励学生网络生成不同于教师的异常特定特征。我们进一步赋予学生网络一个更直接的目标:在教师网络监督的异常区域上建立正常特征表示。由于教师网络是在大型数据集上预先训练的,它可以在正常和异常区域生成判别特征表示。因此,在推理过程中,去噪学生网络将生成与教师网络不同的特征表示。其次,考虑到特征重建任务,得出结论,学生网络不应该复制教师网络的架构。考虑到重建早期层的特征的过程,众所周知,CNN的较低层捕获局部信息,如纹理和颜色。相反,CNN的上层表达全局语义信息。
我们采用它作为去噪学生网络的架构。有一种替代方法可以使用教师网络作为编码器,并将学生网络反向作为解码器;初步实验结果表明,完整的编码器-解码器学生网络性能更好。一种可能的解释是,预先训练的教师网络通常在ImageNet上进行分类任务训练;因此,最后一层中的编码特征缺乏足够的信息来重建所有级别的特征表示。


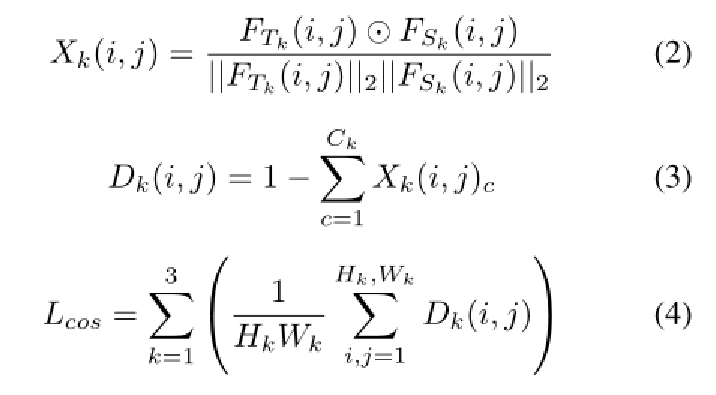
3.3方法细节:Segmentation Network 分割网络

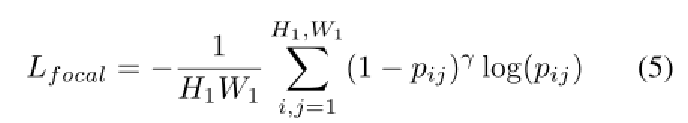
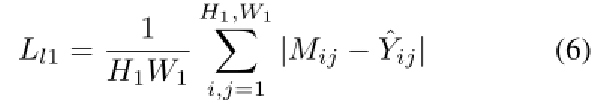
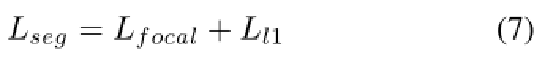
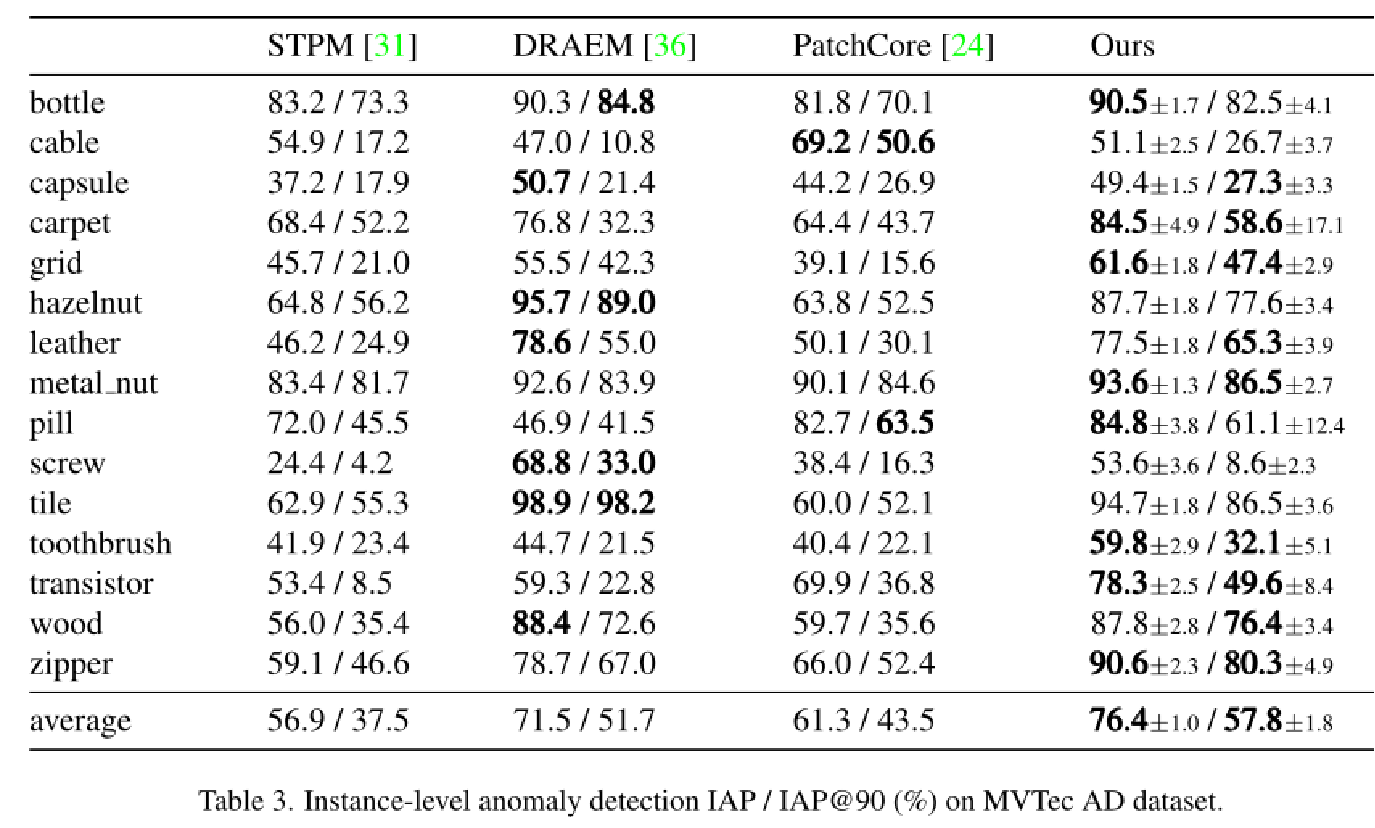
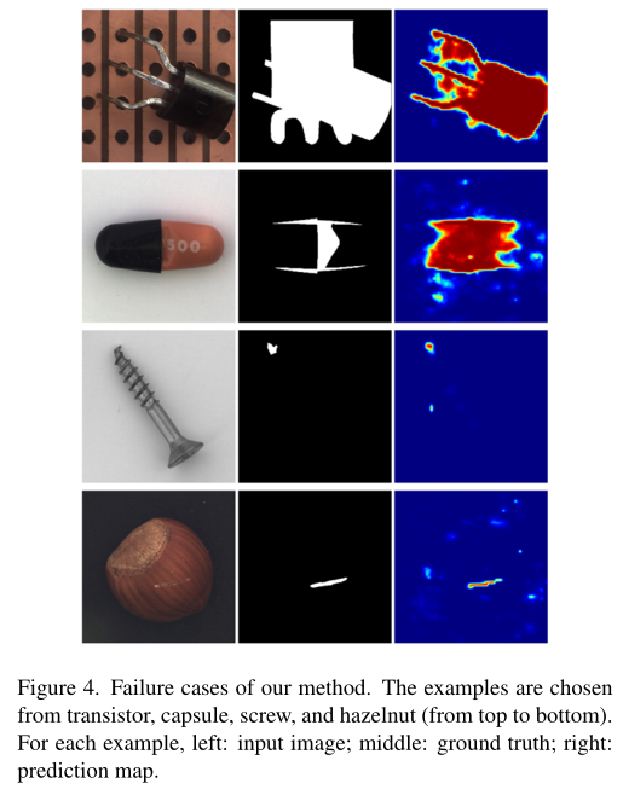
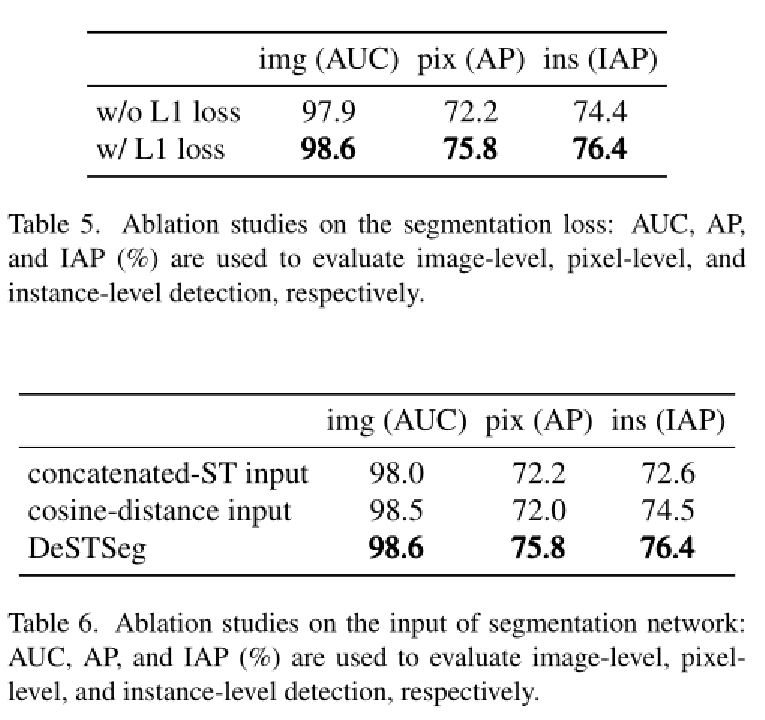
实验结果:



关注下方《学姐带你玩AI》🚀🚀🚀
回复“500”获取AI必读论文合集
码字不易,欢迎大家点赞评论收藏!