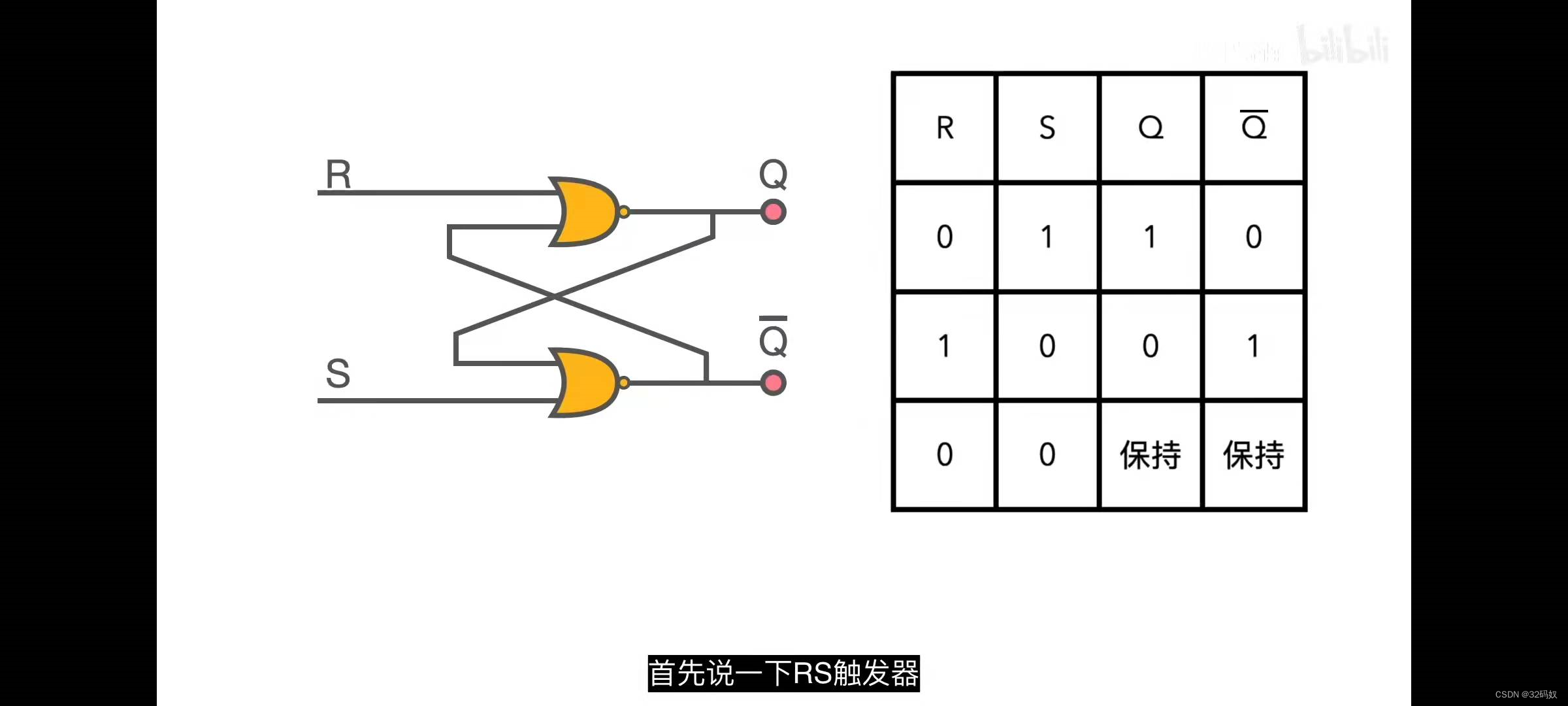
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
实施零样本学习
编码零样本学习
实施小样本学习
建立连体网络
编码连体网络
原型网络的工作细节
关系网络的工作细节
概括
问题
到目前为止,在前面的章节中,我们已经了解了如何对图像进行分类,其中每个类都有成百上千的示例图像要训练。在本章中,我们将学习各种有助于对图像进行分类的技术,即使每个类的训练示例很少。我们将首先训练一个模型来预测一个类,即使与该类对应的图像在训练期间不存在。接下来,我们将继续讨论一个场景,在训练过程中,我们试图预测的类别中只有少数图像存在。我们将对 Siamese 网络进行编码,这些网络属于小样本学习的范畴,并了解关系网络和原型网络的工作细节。
我们将在本章中学习以下主题:
- 实施零样本学习
- 实施小样本学习
实施零样本学习
想象一个场景,我要求您预测图像中的对象类别,而您之前没有看到对象类别的图像。在这种情况下,您将如何做出预测?
直观地说,我们求助于图像中对象的属性,然后尝试识别与最多属性匹配的对象。
在这样一种情况下,我们必须自动提出属性(没有为训练提供属性),我们利用词向量。词向量包含词之间的语义相似性。例如,所有动物都会有相似的词向量,而汽车会有非常不同的词向量表示。虽然词向量的生成超出了本书的范围,但我们将研究预训练的词向量。在非常高的层次上,具有相似周围词(上下文)的词将具有相似的向量。这是词向量的示例 t-SNE 表示:
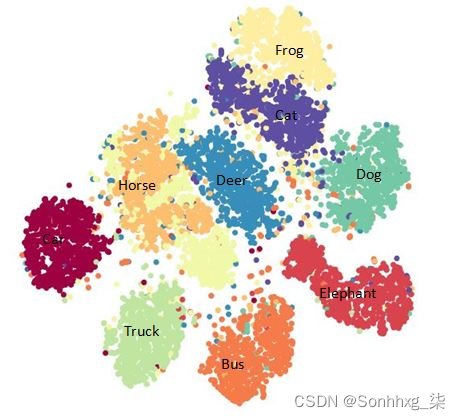
从前面的示例中,我们可以看到汽车的词向量在图表的左侧,而与动物对应的向量在右侧。此外,相似的动物也有相似的向量。
这给了我们直觉,就像图像一样,单词也具有有助于获得相似性的向量嵌入。
在下一节中,当我们编写零样本学习代码时,我们将利用这种现象来识别模型在训练期间没有看到的类。本质上,我们将直接学习将图像特征映射到单词特征。
编码零样本学习
我们在编码零样本学习时采用的高级策略如下:
- 导入数据集——构成图像及其相应的类。
- 从预训练的词向量模型中获取每个类对应的词向量。
- 通过预训练的图像模型(例如 VGG16)传递图像。
- 我们期望网络预测图像中对象对应的词向量。
- 一旦我们训练了模型,我们就会在新图像上预测词向量。
- 最接近预测词向量的词向量的类别是图像的类别。
让我们将前面的策略编码如下:
1.克隆包含本练习数据集的 GitHub 存储库,并导入相关包:
!git clone https://github.com/sizhky/zero-shot-learning/
!pip install -Uq torch_snippets
%cd zero-shot-learning/src
import gzip, _pickle as cPickle
from torch_snippets import *
from sklearn.preprocessing import LabelEncoder, normalize
device = 'cuda' if torch.cuda.is_available() else 'cpu'2.定义特征数据的路径 ( DATAPATH) 以及 word2vec 嵌入 ( WORD2VECPATH):
WORD2VECPATH = "../data/class_vectors.npy"
DATAPATH = "../data/zeroshot_data.pkl"3.提取可用类的列表:
with open('train_classes.txt', 'r') as infile:
train_classes = [str.strip(line) for line in infile]4.加载特征向量数据:
with gzip.GzipFile(DATAPATH, 'rb') as infile:
data = cPickle.load(infile)5.定义训练数据和属于零样本类的数据(训练期间不存在的类)。请注意,我们将只显示属于训练类的类,并隐藏零样本模型类,直到推理时间:
training_data = [instance for instance in data if \
instance[0] in train_classes]
zero_shot_data = [instance for instance in data if \
instance[0] not in train_classes]
np.random.shuffle(training_data)6.每个类获取 300 个训练图像进行训练,其余训练类图像进行验证:
train_size = 300 # per class
train_data, valid_data = [], []
for class_label in train_classes:
ctr = 0
for instance in training_data:
if instance[0] == class_label:
if ctr < train_size:
train_data.append(instance)
ctr+=1
else:
valid_data.append(instance)7.将训练和验证数据打乱,并将与类对应的向量提取到字典中 - vectors:
np.random.shuffle(train_data)
np.random.shuffle(valid_data)
vectors = {i:j for i,j in np.load(WORD2VECPATH, \
allow_pickle=True)}8.获取训练和验证数据的图像和词嵌入特征:
train_data=[(feat,vectors[clss]) for clss,feat in train_data]
valid_data=[(feat,vectors[clss]) for clss,feat in valid_data]9.获取训练、验证和零样本类:
train_clss = [clss for clss,feat in train_data]
valid_clss = [clss for clss,feat in valid_data]
zero_shot_clss = [clss for clss,feat in zero_shot_data]10.定义训练数据、验证数据和零样本数据的输入和输出数组:
x_train, y_train = zip(*train_data)
x_train, y_train = np.squeeze(np.asarray(x_train)), \
np.squeeze(np.asarray(y_train))
x_train = normalize(x_train, norm='l2')
x_valid , y_valid = zip(*valid_data)
x_valid, y_valid = np.squeeze(np.asarray(x_valid)), \
np.squeeze(np.asarray(y_valid))
x_valid = normalize(x_valid, norm='l2')
y_zsl, x_zsl = zip(*zero_shot_data)
x_zsl, y_zsl = np.squeeze(np.asarray(x_zsl)), \
np.squeeze(np.asarray(y_zsl))
x_zsl = normalize(x_zsl, norm='l2')11.定义训练和验证数据集和数据加载器:
from torch.utils.data import TensorDataset
trn_ds = TensorDataset(*[torch.Tensor(t).to(device) for t in \
[x_train, y_train]])
val_ds = TensorDataset(*[torch.Tensor(t).to(device) for t in \
[x_valid, y_valid]])
trn_dl = DataLoader(trn_ds, batch_size=32, shuffle=True)
val_dl = DataLoader(val_ds, batch_size=32, shuffle=False)12.构建一个以 4,096 维特征为输入并预测 300 维向量作为输出的模型:
def build_model():
return nn.Sequential(
nn.Linear(4096, 1024), nn.ReLU(inplace=True),
nn.BatchNorm1d(1024), nn.Dropout(0.8),
nn.Linear(1024, 512), nn.ReLU(inplace=True),
nn.BatchNorm1d(512), nn.Dropout(0.8),
nn.Linear(512, 256), nn.ReLU(inplace=True),
nn.BatchNorm1d(256), nn.Dropout(0.8),
nn.Linear(256, 300)
)13.定义函数来训练和验证一批数据:
def train_batch(model, data, optimizer, criterion):
model.train()
ims, labels = data
_preds = model(ims)
optimizer.zero_grad()
loss = criterion(_preds, labels)
loss.backward()
optimizer.step()
return loss.item()
@torch.no_grad()
def validate_batch(model, data, criterion):
model.eval()
ims, labels = data
_preds = model(ims)
loss = criterion(_preds, labels)
return loss.item()14.在越来越多的时期训练模型:
model = build_model().to(device)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
n_epochs = 60
log = Report(n_epochs)
for ex in range(n_epochs):
N = len(trn_dl)
for bx, data in enumerate(trn_dl):
loss = train_batch(model, data, optimizer, criterion)
log.record(ex+(bx+1)/N, trn_loss=loss, end='\r')
N = len(val_dl)
for bx, data in enumerate(val_dl):
loss = validate_batch(model, data, criterion)
log.record(ex+(bx+1)/N, val_loss=loss, end='\r')
if not (ex+1)%10: log.report_avgs(ex+1)
log.plot_epochs(log=True)前面的代码产生以下输出:
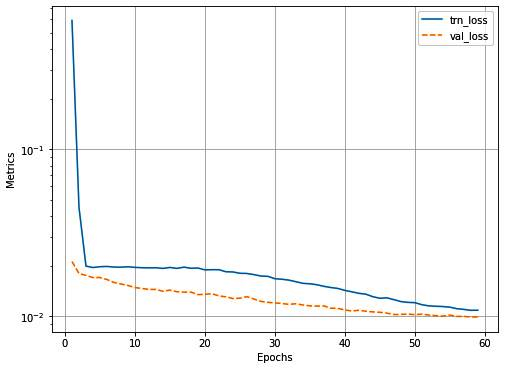
15.预测x_zsl包含零样本类(模型未见过的类)的图像 ( ),并获取实际特征 ( vectors) 并classnames对应于所有可用类:
pred_zsl = model(torch.Tensor(x_zsl).to(device)).cpu()\
.detach().numpy()
class_vectors = sorted(np.load(WORD2VECPATH, \
allow_pickle=True), key=lambda x: x[0])
classnames, vectors = zip(*class_vectors)
classnames = list(classnames)
vectors = np.array(vectors)16.计算每个预测向量与可用类对应的向量之间的距离,并测量前五个预测中存在的零样本类的数量:
dists = (pred_zsl[None] - vectors[:,None])
dists = (dists**2).sum(-1).T
best_classes = []
for item in dists:
best_classes.append([classnames[j] for j in \
np.argsort(item)[:5]])
np.mean([i in J for i,J in zip(zero_shot_clss, best_classes)])从前面可以看出,在模型的前 5 个预测中,我们可以正确预测约 73% 的图像,其中包含训练期间不存在类的对象。请注意,前 1、2 和 3 个预测的正确分类图像的百分比分别为 6%、14% 和 40%。
现在我们已经看到了通过零样本分类在训练中不存在某个类别的图像时进行预测的场景,在下一节中,我们将学习如何构建一个模型来预测图像中的对象类别(如果有)训练集中一个类的几个例子。
实施小样本学习
想象一个场景,我们只给你一个人的 10 张图像,并要求你确定一张新图像是否是同一个人的。作为人类,我们可以轻松地对此类任务进行分类。然而,到目前为止,我们学习的基于深度学习的算法需要成百上千的标记示例才能准确分类。
属于元学习范式的多种算法可以派上用场来解决这种情况。在本节中,我们将了解用于解决少图像问题的连体网络、原型网络和关系匹配网络。
这三种算法都旨在学习比较两个图像,以得出图像相似程度的分数。
下面是一个小样本分类过程中的预期示例:

在前面的代表性数据集中,我们在训练时向网络展示了每个类别的一些图像,并要求它根据这些图像预测新图像的类别。
到目前为止,我们一直在使用预训练模型来解决此类问题。然而,鉴于可用数据量很少,此类模型可能很快就会过拟合。
您可以利用多个指标、模型和基于优化的架构来解决此类场景。在本章中,我们将学习基于度量的架构,该架构提出了一个最佳度量,欧几里得距离或余弦相似度,将相似的图像组合在一起,然后在新图像上进行预测。
一个 N-shot k 类分类是其中有 N 个图像,每个用于 k 个类来训练网络。
在接下来的部分中,我们将了解 Siamese 网络的工作细节和代码,以及原型和关系网络的工作细节。
建立连体网络
在这里,它是我们的两个图像(一个参考图像和查询图像)通过的网络。让我们了解 Siamese 网络的工作细节,以及它们如何帮助识别只有几张图像的同一个人的图像。首先,让我们看一下连体网络如何工作的高级概述:
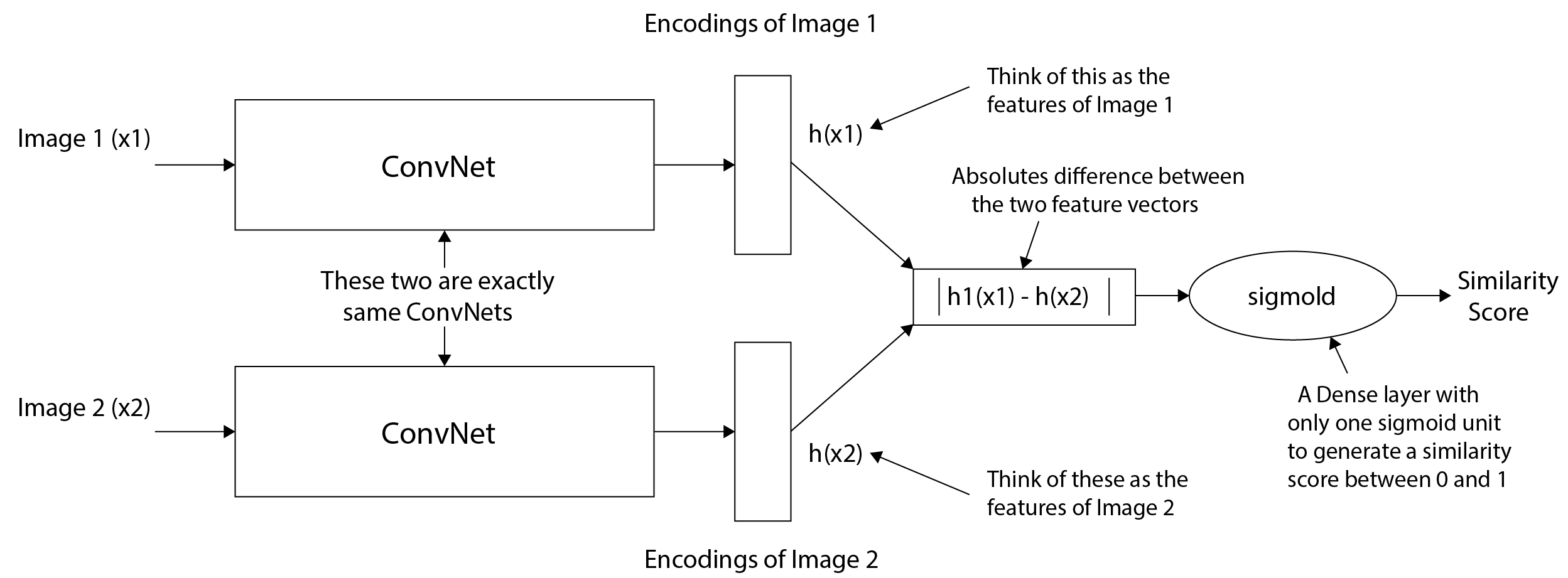
我们通过以下步骤:
- 通过卷积网络传递图像。
- 通过与步骤 1 相同的神经网络传递另一张图像。
- 计算两个图像的编码(特征)。
- 计算两个特征向量之间的差异。
- 通过sigmoid激活传递差异向量,表示两幅图像是否相似。
前面架构中的 Siamese 一词涉及通过双胞胎网络(我们复制网络以处理两个图像)传递两个图像以获取两个图像中每一个的图像编码。此外,我们正在比较两个图像的编码以获取两个图像的相似度分数。如果相似度得分(或相异度得分)超过阈值,我们认为这些图像属于同一个人。
有了这个策略,让我们编写 Siamese 网络来预测与图像对应的类别——其中图像类别在训练数据中只出现过几次。
编码连体网络
在本节中,我们将学习如何对连体网络进行编码,以预测一个人的图像是否与我们数据库中的参考图像相匹配。
我们采用的高层策略如下:
- 获取数据集。
- 以这样一种方式创建数据,即同一个人的两个图像的相异性会很低,而当两个图像是不同的人时,相异性会很高。
- 构建卷积神经网络( CNN )。
- 如果图像是同一个人,我们期望 CNN 将与分类损失相对应的损失值和两幅图像之间的距离相加。我们在这个练习中使用对比损失。
- 在越来越多的时期训练模型。
让我们对前面的策略进行编码:
1.导入相关包和数据集:
!pip install torch_snippets
from torch_snippets import *
!wget https://www.dropbox.com/s/ua1rr8btkmpqjxh/face-detection.zip
!unzip face-detection.zip
device = 'cuda' if torch.cuda.is_available() else 'cpu'训练数据包含 38 个文件夹(每个文件夹对应不同的人),每个文件夹包含 10 个该人的样本图像。测试数据包括 3 个不同人员的 3 个文件夹,每个文件夹有 10 张图像。
2.定义数据集类 - SiameseNetworkDataset:
- 该方法将包含的图像和要执行的转换 ( ) 作为输入: __init__ folder transform
class SiameseNetworkDataset(Dataset):
def __init__(self, folder, transform=None, \
should_invert=True):
self.folder = folder
self.items = Glob(f'{self.folder}/*/*')
self.transform = transform- 定义方法: __getitem__
def __getitem__(self, ix):
itemA = self.items[ix]
person = fname(parent(itemA))
same_person = randint(2)
if same_person:
itemB = choose(Glob(f'{self.folder}/{person}/*', \
silent=True))
else:
while True:
itemB = choose(self.items)
if person != fname(parent(itemB)):
break
imgA = read(itemA)
imgB = read(itemB)
if self.transform:
imgA = self.transform(imgA)
imgB = self.transform(imgB)
return imgA, imgB, np.array([1-same_person])在前面的代码中,我们获取两个图像 -imgA和,如果是同一个人,则返回第三个输出 0,如果不是,则返回 1。 imgB
- 定义方法: __len__
def __len__(self):
return len(self.items)3.定义要执行的转换,并为训练和验证数据准备数据集和数据加载器:
from torchvision import transforms
trn_tfms = transforms.Compose([
transforms.ToPILImage(),
transforms.RandomHorizontalFlip(),
transforms.RandomAffine(5, (0.01,0.2), \
scale=(0.9,1.1)),
transforms.Resize((100,100)),
transforms.ToTensor(),
transforms.Normalize((0.5), (0.5))
])
val_tfms = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize((100,100)),
transforms.ToTensor(),
transforms.Normalize((0.5), (0.5))
])
trn_ds=SiameseNetworkDataset(folder="./data/faces/training/" \
, transform=trn_tfms)
val_ds=SiameseNetworkDataset(folder="./data/faces/testing/", \
transform=val_tfms)
trn_dl = DataLoader(trn_ds, shuffle=True, batch_size=64)
val_dl = DataLoader(val_ds, shuffle=False, batch_size=64)4.定义神经网络架构:
- 定义卷积块 ( convBlock):
def convBlock(ni, no):
return nn.Sequential(
nn.Dropout(0.2),
nn.Conv2d(ni, no, kernel_size=3, padding=1, \
padding_mode='reflect'),
nn.ReLU(inplace=True),
nn.BatchNorm2d(no),
)- 定义在SiameseNetwork给定输入的情况下返回五维编码的架构:
class SiameseNetwork(nn.Module):
def __init__(self):
super(SiameseNetwork, self).__init__()
self.features = nn.Sequential(
convBlock(1,4),
convBlock(4,8),
convBlock(8,8),
nn.Flatten(),
nn.Linear(8*100*100, 500), nn.ReLU(inplace=True),
nn.Linear(500, 500), nn.ReLU(inplace=True),
nn.Linear(500, 5)
)
def forward(self, input1, input2):
output1 = self.features(input1)
output2 = self.features(input2)
return output1, output25.定义函数: ContrastiveLoss
class ContrastiveLoss(torch.nn.Module):
"""
Contrastive loss function.
Based on: http://yann.lecun.com/exdb/publis/pdf/hadsell-chopra-lecun-06.pdf
"""
def __init__(self, margin=2.0):
super(ContrastiveLoss, self).__init__()
self.margin = margin请注意,这里的边距就像 SVM 中的边距,我们希望属于两个不同类别的数据点之间的边距尽可能高。
- 定义forward方法:
def forward(self, output1, output2, label):
euclidean_distance = F.pairwise_distance(output1, \
output2, keepdim = True)
loss_contrastive = torch.mean((1-label) * \
torch.pow(euclidean_distance, 2) + \
(label) * torch.pow(torch.clamp( \
self.margin - euclidean_distance, \
min=0.0), 2))
acc = ((euclidean_distance>0.6)==label).float().mean()
return loss_contrastive, acc在前面的代码中,我们正在获取两个不同图像的编码 -并计算它们的. output1 output2 eucledian_distance
接下来,我们正在计算对比损失 - ,它会惩罚相同标签的图像之间的欧几里德距离高,以及欧几里得距离低和不同标签的图像。 loss_contrastiveself.margin
6.定义对一批数据进行训练和验证的函数:
def train_batch(model, data, optimizer, criterion):
imgsA, imgsB, labels = [t.to(device) for t in data]
optimizer.zero_grad()
codesA, codesB = model(imgsA, imgsB)
loss, acc = criterion(codesA, codesB, labels)
loss.backward()
optimizer.step()
return loss.item(), acc.item()
@torch.no_grad()
def validate_batch(model, data, criterion):
imgsA, imgsB, labels = [t.to(device) for t in data]
codesA, codesB = model(imgsA, imgsB)
loss, acc = criterion(codesA, codesB, labels)
return loss.item(), acc.item()7.定义模型、损失函数和优化器:
model = SiameseNetwork().to(device)
criterion = ContrastiveLoss()
optimizer = optim.Adam(model.parameters(),lr = 0.001)8.在越来越多的时期训练模型:
n_epochs = 200
log = Report(n_epochs)
for epoch in range(n_epochs):
N = len(trn_dl)
for i, data in enumerate(trn_dl):
loss, acc = train_batch(model, data, optimizer, \
criterion)
log.record(epoch+(1+i)/N,trn_loss=loss,trn_acc=acc, \
end='\r')
N = len(val_dl)
for i, data in enumerate(val_dl):
loss, acc = validate_batch(model, data, \
criterion)
log.record(epoch+(1+i)/N,val_loss=loss,val_acc=acc, \
end='\r')
if (epoch+1)%20==0: log.report_avgs(epoch+1)- 绘制训练和验证损失精度随时间增加的变化的对数:
log.plot_epochs(['trn_loss','val_loss'])
log.plot_epochs(['trn_acc','val_acc'])前面的代码产生以下输出:
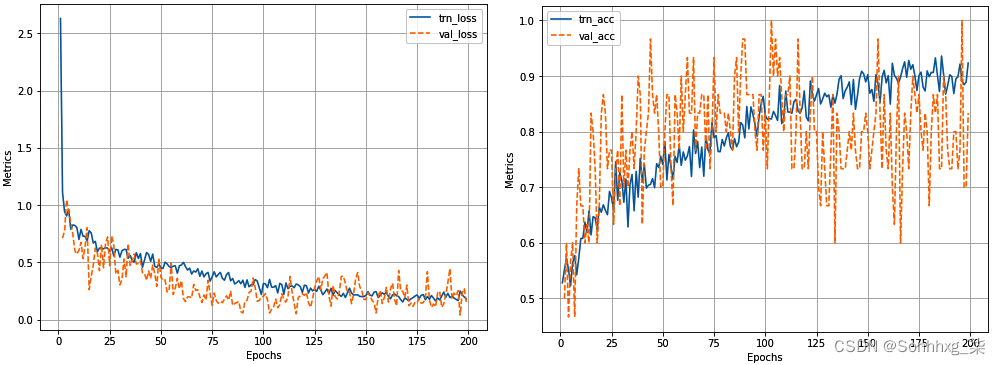
9.在新图像上测试模型。请注意,该模型从未见过这些新图像。在测试时,我们将随机获取一张测试图像,并将其与测试数据中的其他图像进行比较:
model.eval()
val_dl = DataLoader(val_ds,num_workers=6,batch_size=1, \
shuffle=True)
dataiter = iter(val_dl)
x0, _, _ = next(dataiter)
for i in range(2):
_, x1, label2 = next(dataiter)
concatenated = torch.cat((x0*0.5+0.5, x1*0.5+0.5),0)
output1,output2 = model(x0.cuda(),x1.cuda()) euclidean_distance
= F.pairwise_distance(output1, output2)
output = 'Same Face' if euclidean_distance.item() < 0.6 \
else 'Different'
show(torchvision.utils.make_grid(concatenated), \
title='Dissimilarity: {:.2f}\ n{}'.\
format(euclidean_distance.item(), output))
plt.show()上述结果产生以下输出:

从前面我们可以看出,即使我们只有几个类别的图像,我们也可以识别图像中的人。
现在我们了解了连体网络的工作原理,在接下来的部分中,我们将了解其他基于度量的技术——原型和关系网络。
原型网络的工作细节
原型是某个类的代表。想象一个场景,我们为每个类提供 10 张图像,并且有 5 个这样的类。原型网络通过取属于一个类的每个图像的嵌入的平均值,为每个类提出一个有代表性的嵌入(原型)。
在这里,让我们了解一个实际的场景:
假设您有 5 个不同类别的图像,其中每个类别包含 10 个图像的数据集。此外,我们在训练中为每个班级提供 5 张图像,并在其他 5 张图像上测试您的网络的准确性。我们将使用每个类别的一张图像和随机选择的测试图像作为查询来构建我们的网络。我们的任务是识别与查询图像(测试图像)具有最高相似性的已知图像(训练图像)的类别。
对于面部识别,原型网络的工作细节如下:
- 随机选择 N 个不同的人进行训练。
- 选择与每个人对应的 k 个样本作为可用于训练的数据点——这是我们的支持集(要比较的图像)。
- 选择每个人对应的 q 个样本作为要测试的数据点——这是我们的查询集(要比较的图像):

目前,我们选择了 N c个类,支持集中有 N s幅图像,查询集中有 N q幅图像:
- 当通过 CNN 网络时,获取支持集(训练图像)和查询集(测试图像)中每个数据点的嵌入,我们期望 CNN 网络识别与训练图像具有最高相似性的索引查询图像。
- 训练网络后,计算与支持集(训练图像)嵌入对应的原型:
- 原型是属于同一类的所有图像的平均嵌入:

在前面的示例图中,有三个类,每个圆圈代表属于该类的图像的嵌入。每个星(原型)是图像中存在的所有图像(圆圈)的平均嵌入:
- 计算查询嵌入和原型嵌入之间的欧几里得距离:
- 如果有 5 个查询图像和 10 个类,我们将有 50 个欧几里得距离。
- 在前面获得的欧几里德距离之上执行 softmax,以识别对应于不同支持类的概率。
- 训练模型以最小化将查询图像分配给正确类别的损失值。此外,在遍历数据集时,在下一次迭代中随机选择一组新的人。
在迭代结束时,模型将学会识别查询图像所属的类别——给定一些支持集图像和查询图像。
关系网络的工作细节
关系网络与连体网络非常相似,只是我们优化的指标不是嵌入之间的 L1 距离,而是关系分数。让我们使用下图了解关系网络的工作细节:
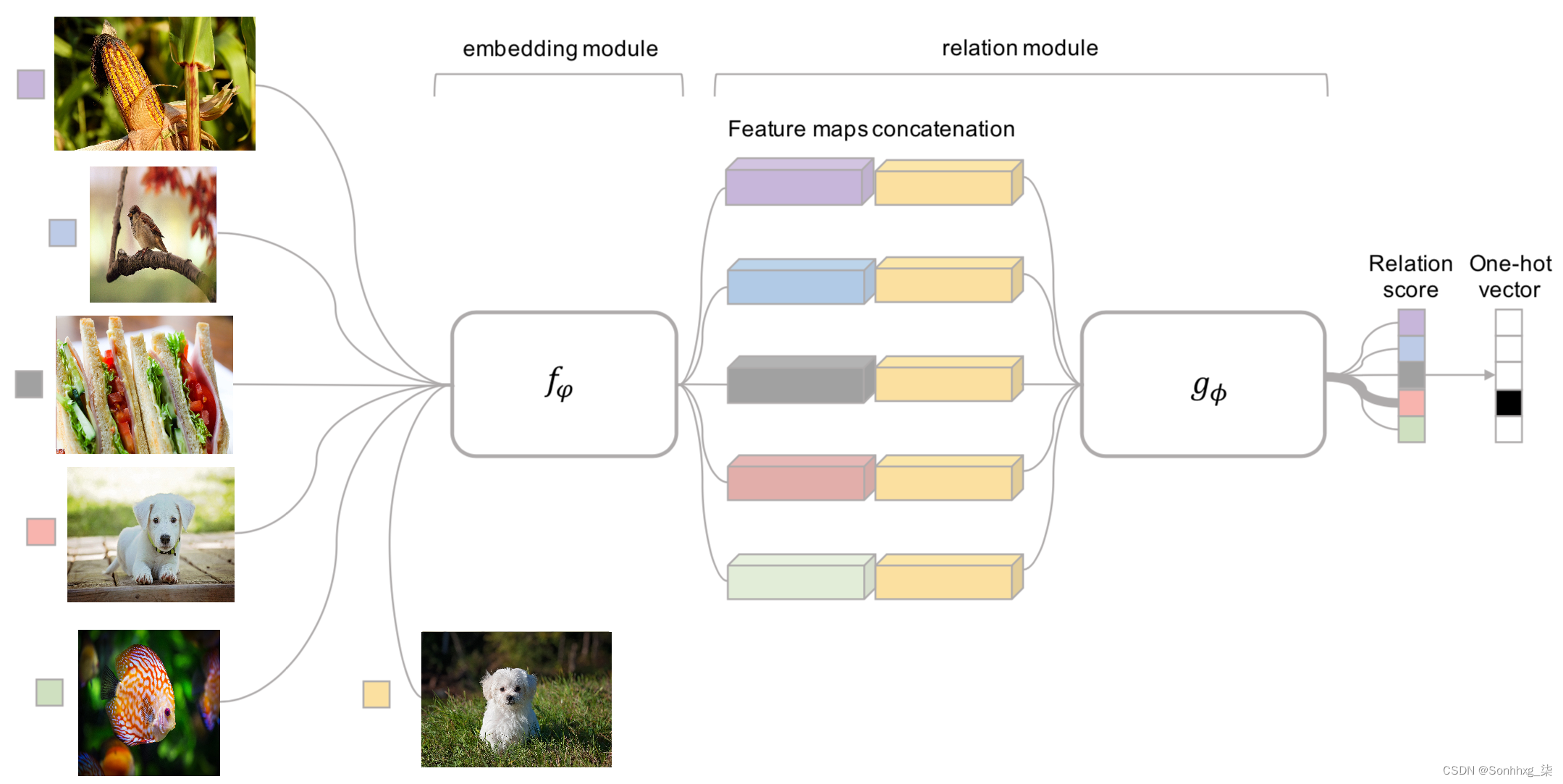
在上图中,左边的图片是五个类的支持集,底部的狗图片是查询图片:
- 通过嵌入模块传递支持和查询图像,该模块为输入图像提供嵌入。
- 将支持图像的特征图与查询图像的特征图连接起来。
- 通过 CNN 模块传递连接的特征以预测关系分数。
具有最高关系分数的类是查询图像的预测类。
有了这个,我们已经了解了小样本学习算法的不同工作方式。我们将给定的查询图像与一组支持图像进行比较,以得出支持集中与查询图像具有最高相似性的对象类别。
概括
在本章中,我们学习了如何利用词向量提出一种方法来解决我们想要预测的类在训练期间不存在的情况。此外,我们了解了连体网络,它学习了两个图像之间的距离函数来识别相似人的图像。最后,我们了解了原型网络和关系网络,以及它们如何学习执行小样本图像分类。
在下一章中,我们将学习如何结合计算机视觉和基于自然语言处理的技术来提出解决图像注释、检测图像中的对象和手写转录的方法。
问题
- 如何获得预训练的词向量?
- 我们如何在零样本学习中从图像特征嵌入映射到词嵌入?
- 连体网为什么这么叫?
- Siamese 网络是如何得出两张图片之间的相似度的?