前一篇博客已经整理了不训练视觉模型的文章们:
- 基于LLMs的多模态大模型(Visual ChatGPT,PICa,MM-REACT,MAGIC)
本篇文章将介绍一些需要训练视觉编码器来适配多模态大模型的工作们,这也是目前最为流行的研究思路。
其实早在2021年DeepMind发表Frozen的时候就已经有了few-shot甚至in-context learning的思路,博主在以往的博文中也有过介绍(Multimodal Few-Shot Learning with Frozen Language Models),此处简要回顾一下,如下图所示,Frozen先将图片编码成visual tokens,然后作为prefix跟文本的tokens一起输入到LLMs。在o-shot,1-shot和few-shot时都可以利用类似的操作。
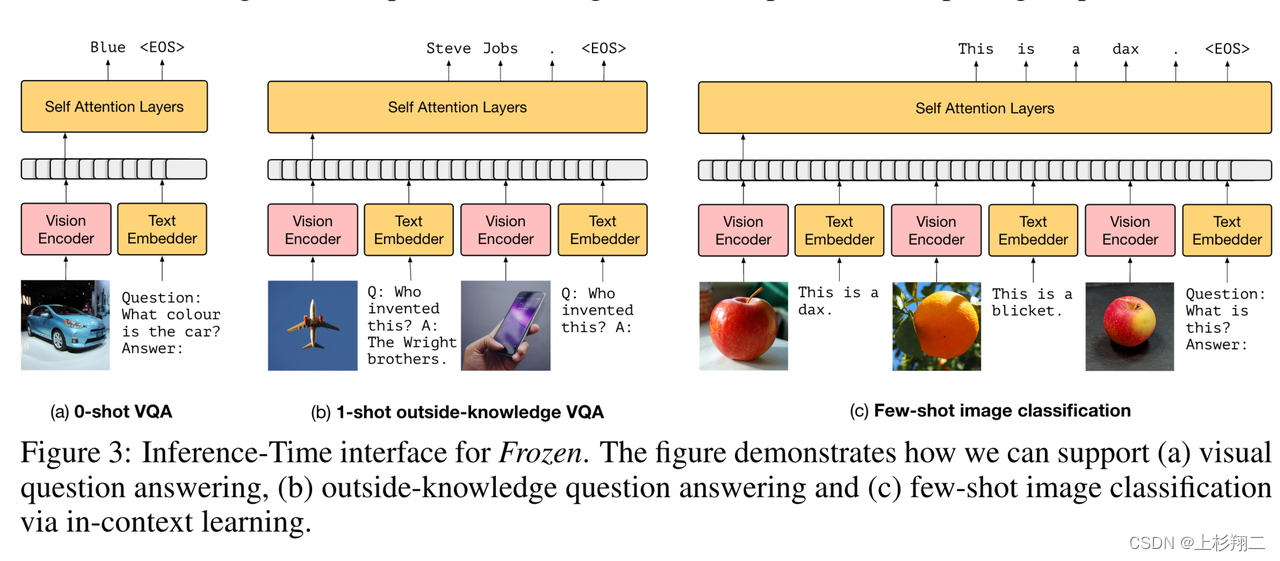
由于Frozen仅有vision encoder是支持训练,而LLMs参数处于冻结状态,即通过训练视觉编码器来适配LLMs,这种方法可以使得训练成本大大降低,而当现在有了chatgpt系列的技术之后,这一思路也很自然的能被用到多模态大模型上来。
Flamingo
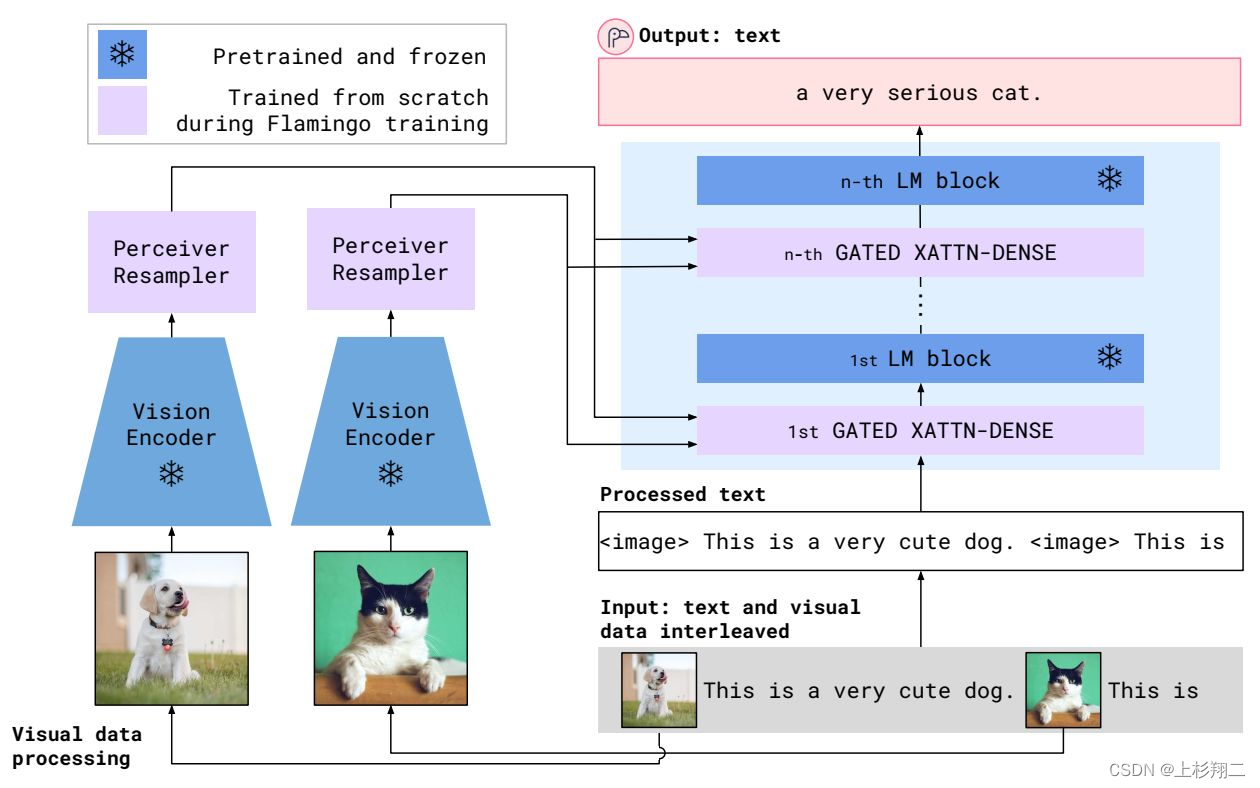
出自DeepMind,它在Frozen模型的基础上做进一步的改进,不同点主要有两个:一是使用了更大的LLMs,二是冻结视觉编码器,引入perceiver resampler和XAttn-Dense两个适配单元作为可训练的模块。
- perceiver resampler:类似DETR,通过设计多个Perceiver Resampler来生成64个固定长度的tokens,主要作用在于可以从图像中提取固定长度的特征向量,能够解决图像甚至多帧视频的feature map不一致的问题。
- XAttn-Dense:在每一层LLM上都会增加corss- attention以入到LLM中与视觉向量进行交互,融合多模态信息。
另外值得注意的是,Flamingo在训练时使用了MultiModal MassiveWeb (M3W) 数据集,这是一个从网页上收集的图文混合数据,由于这种混合数据需要先拍平再输入模型(通过图片相对位置等信息),从而让Flamingo拥有了in-context learning的能力。
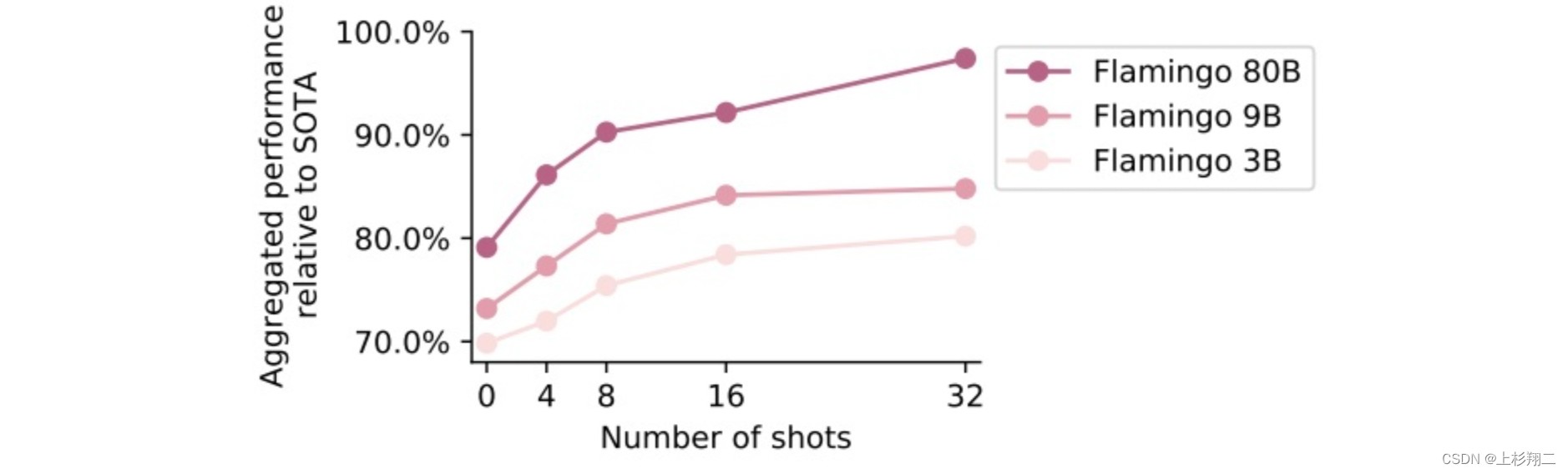
Flamingo有3B,9B,80B的三个版本,性能和N-shots能力如下图所示。
paper:Flamingo: a Visual Language Model for Few-Shot Learning
arxiv:https://arxiv.org/abs/2204.14198
code:https://github.com/lucidrains/flamingo-pytorch
BLIP-2
首先回顾一下BLIP,BLIP的主要特点是结合了encoder和decoder,即形成了统一理解和生成(Understanding&Generation)的多模态模型。统一的动机在于encoder模型如CLIP没有生成器无法做VQA等生成任务,而如果用encoder-decoder框架无法做retrieval任务。因此BLIP很大的贡献在于MED(mixture of encoder-decoder)模块。从而使该模型既可以有理解能力(encoder),又可以有生成能力(decoder)。
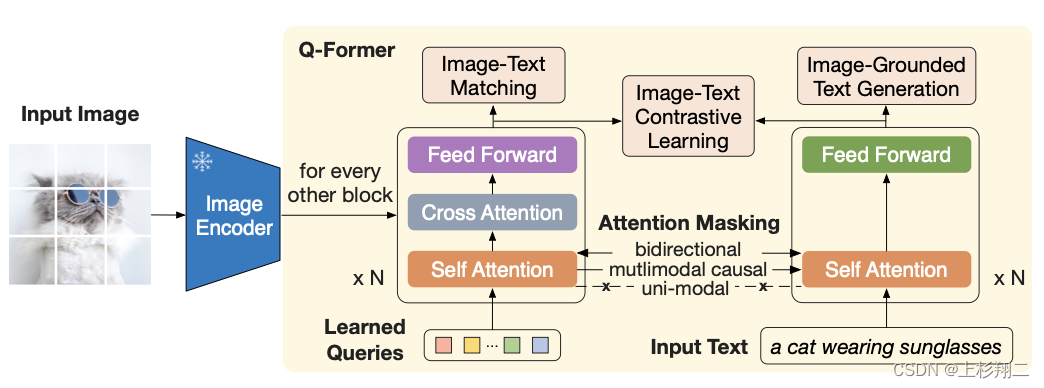
而BLIP-2和Flamingo一样,用一个Qformer来提取图像特征(等同与Flamingo的perceiver resampler),然后用cross- attention进行多模态交互,此时视觉编码器和LLM都会被冻结,只训练Qformer,而在下游任务微调时,可以再解锁视觉编码器,让它跟Qformer一起训练,如下图所示。
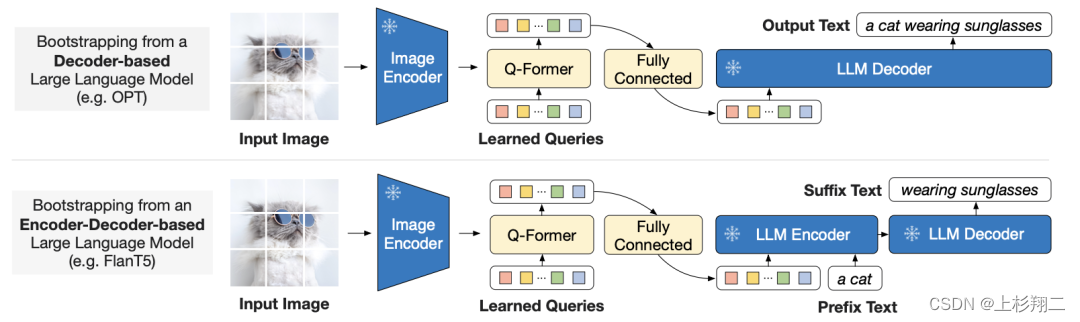
因此BLIP-2设计了两阶段的训练策略,以使视觉编码器能学会提取更关键的信息。
- 第一阶段:使用多种预训练任务,如Image-Text Contrastive Learning,Image-grounded Text Generation,Image-Text Matching让Qformer学会如何从视觉编码器中抽取文本相关的特征。
- 第二阶段,将Qformer插入到LLMs中,用language modeling进行训练。
BLIP2的训练数据包括MSCOCO,Visual Genome,CC15M,SBU,115M来自于LAION400M的图片以及BLIP在web images上生成的描述。不过BLIP-2没有使用Flamingo那种图文交错的数据,因此它没有太强的in-context learning能力。
paper:BLIP2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
arxiv:https://arxiv.org/abs/2301.12597
code:https://github.com/salesforce/LAVIS/tree/main/projects/blip2

KOSMOS-1
KOSMOS-1是一个基于decoder-only Transformer的因果语言模型、并且完全从头开始训练,能够instruction following和in-context learning。
首先对于多模态的输入,会使用特殊符号进行每种模态的分割:
图像输入:<image>Image Embedding</image>
文本输入:<s>这是一只狗吗</s>
交错的图文输入:<s><image>Image Embedding</image>这是一只白狗吗?</s>

此外,Flamingo中的Resampler同样会被使用来做注意力池化以减少图像嵌入的数量。
因果语言模型是指在获得以上展平后的embedding后,将在Transformer中应用一个causal mask以mask未来的信息,即从左到右的因果模型以自回归的方式处理序列。该模型共有24层,2048个隐藏维度,8192的FFN中间层大小,32个注意力头,这一部分1.3B。使用Magneto的初始化、xPos的position embedding、CLIP(ViT-L/14)得到1024维图新特征。最后一共1.6B参数量。
对于训练数据来说,由多个源的数据组成:
- 交错的多模态数据。主要是交错排列的图文文档,来自Common Crawl的原始网页快照,通过过滤、提取图像文本、并限制最大长度为5,且随机对齐一半只有1张图的网页。
- mage-caption pairs。主要是LAION-2B、LAION-400M、COYO-700M、Conceptual Captions数据集。
- 一些纯文本预料。主要是The pile和Common Crawl数据集。
其中数据中有0.5M个tokens来自文本语料,0.5M个tokens来自图文对,0.2M个tokens来自交错数据,约360B的tokens,然后通过language modeling进行预训练(即next-token prediction)。
此外,KOSMOS-1能够更好地理解人类指令,在预训练结束之后,还加入了Unnatural Instruction(68478个指令-输入-输出三元组)和FLAN v2 (涵盖不同类型的语言理解任务,例如阅读理解、常识推理、闭卷问答,随机选择 54k )进行指令微调,这是非常靠近ChatGPT的做法了,也被相信GPT-4的多模态能力有可能也是从instruction中得来。
从结果来看,KOSMOS-1比Flamingo-3B和Flamingo-9B模型具有更高的准确率和鲁棒性。
paper:Language Is Not All You Need: Aligning Perception with Language Models
arxiv:https://arxiv.org/abs/2302.14045
通用来说,预训练主要是帮助模型能够拥有很多的知识,使得生成的结构更符合语义和逻辑(在多模态领域可能就是多模态语义理解了),但如果想要面对用户的要求(如帮我翻译以下文章)则需要instruct tuning。
因此在KOSMOS-1使用instruction tuning后,也短短数周内出现了很多类似的文章,如MiniGPT-4,LLaVA,mPLUG-Owl,InstuctBLIP等,它们将在下一篇博文中继续整理:
- 基于LLMs的多模态大模型(MiniGPT-4,LLaVA,mPLUG-Owl,InstuctBLIP)
- 基于LLMs的多模态大模型(PALM-E,ArtGPT-4,VPGTrans )
ScienceQA
补。有了instruct tuning,还会缺少多模态cot的数据集吗?该数据集来自UCLA和艾伦人工智能研究院,是首个用于测试模型的多模态推理能力的多模态科学问答(Science Question Answering)数据集。构建该数据的Motivation来自于为了正确回答科学问题,模型需要
- 理解多模态内容
- 获取外部知识
- 揭示推理过程

比如要回答上图所示的例子(输入为问题,回答和一个多模态的上下文),那么首先要知道关于力的定义,然后形成一个多步的推理过程,最终才能得到正确答案。
ScienceQA数据一共包含21208个例子, 其中10332的题目有视觉上下文,10220道的题目有文本上下文,6532道(30.8%)有视觉+文本。且83.9%问题有背景知识标注(lecture),91.3%问题有详细的解答(explanation),这么详细的数据集非常适合做cot了。
基于这样的数据集,也可以通过结合上面的方法来进一步拓展利用LLMs的能力。
paper:ScienceQA: Science Question Answering
arxiv:https://arxiv.org/pdf/2209.09513.pdf
code:https://github.com/lupantech/ScienceQA