前言:最近拜读了美团算法团队出品的《美团机器学习实践》,这本书写于2018年,一个大模型还没有标配的时代。这本书侧重于工业界的实践,能清楚地让我们了解到工业界和学术界对机器学习的关注方向上的差异,值得一读。因为我是重点做模型工程/模型部署方向的,所以重点关注这个方面,汲取美团技术团队的经验。
目录
机器学习的通用流程
1、问题建模
2、特征工程
3、模型选择
4、模型融合
数据去噪
特征工程
CPU推理服务优化
系统级优化
系统级优化使用中有哪些影响性能的因素?
如何进行应用级的优化?
如何进行算法级的优化?
Batchsize 的选取在 CPU 上对服务性能的影响是怎样的?
融合优化
引擎优化
Pipeline
参考

机器学习的通用流程
1、问题建模
将问题抽象成机器学习可预测的问题,这个过程中要有明确的业务指标和模型预测目标,根据目标选择适当的评估指标用于模型评估。
2、特征工程
对数据集进行特征抽取。成功的机器学习算法必然在特征工程方面做的非常好。
3、模型选择
在众多模型中选择最佳的模型需要对模型有很深入的理解。
4、模型融合
采用模型融合的方法,充分利用不同模型的差异,进一步优化目标。
数据去噪
噪声的存在会使数据质量变低,影响模型效果;另一方面通过在训练数据集中引入噪声能够提升模型的健壮性。所以处理噪声数据的时候需要权衡模型的健壮性和模型效果。
针对误标注实例,最常见的有集成过滤法、交叉验证委员会过滤法、迭代分割过滤法。
特征工程
“数据和特征决定了算法的上限,而模型和算法知识不断逼近这个上限而已”
特征工程就是把原始的数据空间变换到新的特征空间。
CPU推理服务优化
CPU 上进行深度学习推理服务优化的方法,可以分为系统级、应用级、算法级,每一级也有对应的性能分析工具:

系统级优化
CPU 上系统级优化实践中我们主要采用数学库优化(基于 MKL-DNN)和深度学习推理 SDK 优化(Intel OpenVINO)两种方式。这两种方式均包含了 SIMD 指令集的加速。
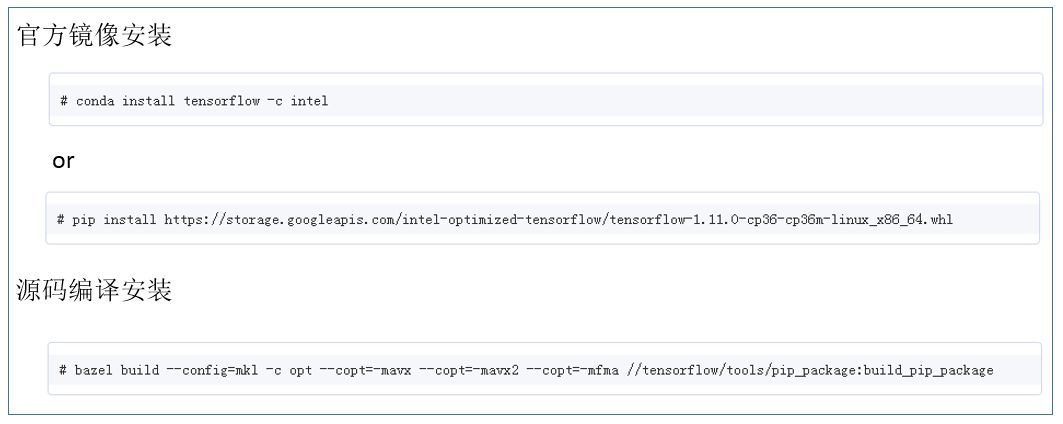
数学库优化对主流的深度学习框架(tensorflow,caffe,mxnet,pytorch 等)均有官方源支持。以 tensorflow 为例,使用方法如下所示:
深度学习推理 SDK 优化方法,需要首先将原生深度学习模型进行转换,生成 IR 中间模型格式,之后调用 SDK 的接口进行模型加载和推理服务封装。具体流程如下所示:

基于两种优化方式的特点,实践中可首先使用基于 MKL-DNN 的优化方式进行服务性能测试,如满足服务需求,可直接部署;对于性能有更高要求的服务,可尝试进行 OpenVINO SDK 优化的方法。
系统级优化使用中有哪些影响性能的因素?
以上两种系统级优化方法,使用过程中有以下因素会影响服务性能。
(1)OpenMP 参数的设置
两种推理优化方式均使用了基于 OMP 的并行计算加速,因此 OMP 参数的配置对性能有较大的影响。主要参数的推荐配置如下所示:
• OMP_NUM_THREADS = “number of cpu cores in container”
• KMP_BLOCKTIME = 10
• KMP_AFFINITY=granularity=fine, verbose, compact,1,0
(2)部署服务的 CPU 核数对性能的影响
CPU 核数对推理服务性能的影响主要是:
• Batchsize 较小时(例如在线类服务),CPU 核数增加对推理吞吐量提升逐渐减弱,实践中根据不同模型推荐 8-16 核 CPU 进行服务部署;
• Batchsize 较大时(例如离线类服务),推理吞吐量可随 CPU 核数增加呈线性增长,实践中推荐使用大于 20 核 CPU 进行服务部署;
(3)CPU 型号对性能的影响
不同型号的 CPU 对推理服务的性能加速也不相同,主要取决于 CPU 中 SIMD 指令集。例如相同核数的 Xeon Gold 6148 的平均推理性能是 Xeon E5-2650 v4 的 2 倍左右,主要是由于 6148 SIMD 指令集由 avx2 升级为 avx-512。
目前线上集群已支持选择不同类型的 CPU 进行服务部署。
(4)输入数据格式的影响
除 Tensorflow 之外的其他常用深度学习框架,对于图像类算法的输入,通常推荐使用 NCHW 格式的数据作为输入。Tensorflow 原生框架默认在 CPU 上只支持 NHWC 格式的输入,经过 MKL-DNN 优化的 Tensorflow 可以支持两种输入数据格式。
使用以上两种优化方式,建议算法模型以 NCHW 作为输入格式,以减少推理过程中内存数据重排带来的额外开销。
(5)NUMA 配置的影响
对于 NUMA 架构的服务器,NUMA 配置在同一 node 上相比不同 node 上性能通常会有 5%-10%的提升。
如何进行应用级的优化?
进行应用级的优化,首先需要将应用端到端的各个环节进行性能分析和测试,找到应用的性能瓶颈,再进行针对性优化。性能分析和测试可以通过加入时间戳日志,或者使用时序性能分析工具,例如 Vtune,timeline 等 。优化方法主要包括并发和流水设计、数据预取和预处理、I/O 加速、特定功能加速(例如使用加速库或硬件进行编解码、抽帧、特征 embedding 等功能加速)等方式。
下面以视频质量评估服务为例,介绍如何利用 Vtune 工具进行瓶颈分析,以及如何利用多线程/进程并发进行服务的优化。
视频质量评估服务的基本流程如图 10 所示,应用读入一段视频码流,通过 OpenCV 进行解码、抽帧、预处理,之后将处理后的码流经过深度学习网络进行推理,最后通过推理结果的聚合得到视频质量的打分,来判定是何种类型视频。
图 11 是通过 Vtune 工具抓取的原始应用线程,可以看到 OpenCV 单一解码线程一直处于繁忙状态(棕色),而 OMP 推理线程常常处于等待状态(红色)。整个应用的瓶颈位于 Opencv 的解码及预处理部分。
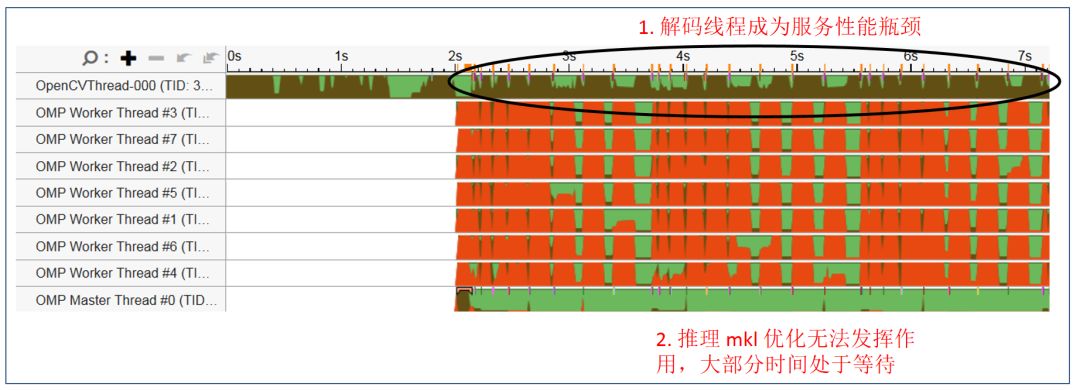
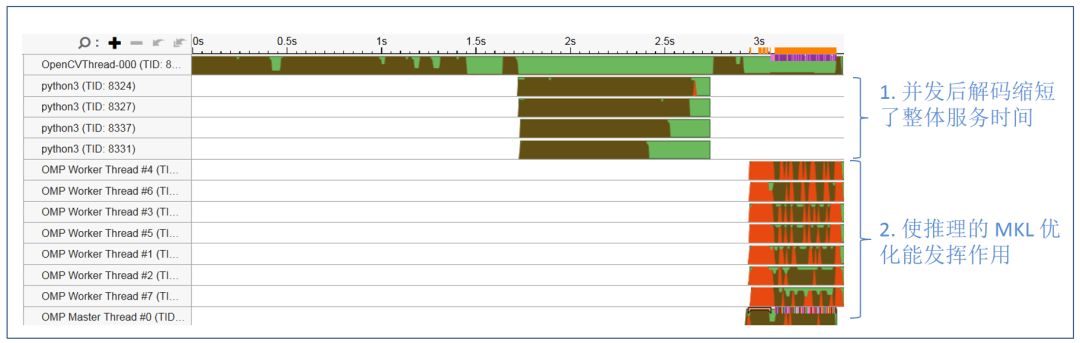
图 12 显示优化后的服务线程状态,通过生成多个进程并发进行视频流解码,并以 batch 的方式进行预处理;处理后的数据以 batch 的方式传入 OMP threads 进行推理来进行服务的优化。
经过上述简单的并发优化后,对 720 帧视频码流的处理时间,从 7 秒提升到了 3.5 秒,性能提升一倍。除此之外,我们还可以通过流水设计,专用解码硬件加速等方法进一步提升服务整体性能。
如何进行算法级的优化?
常见的算法级优化提升推理服务性能的方法包括 batchsize 的调整、模型剪枝、模型量化等。其中模型剪枝和量化因涉及到模型结构和参数的调整,通常需要算法同学帮助一起进行优化,以保证模型的精度能满足要求。
Batchsize 的选取在 CPU 上对服务性能的影响是怎样的?
Batchsize 选取的基本原则是延时敏感类服务选取较小的 batchsize,吞吐量敏感的服务选取较大的 batchsize。
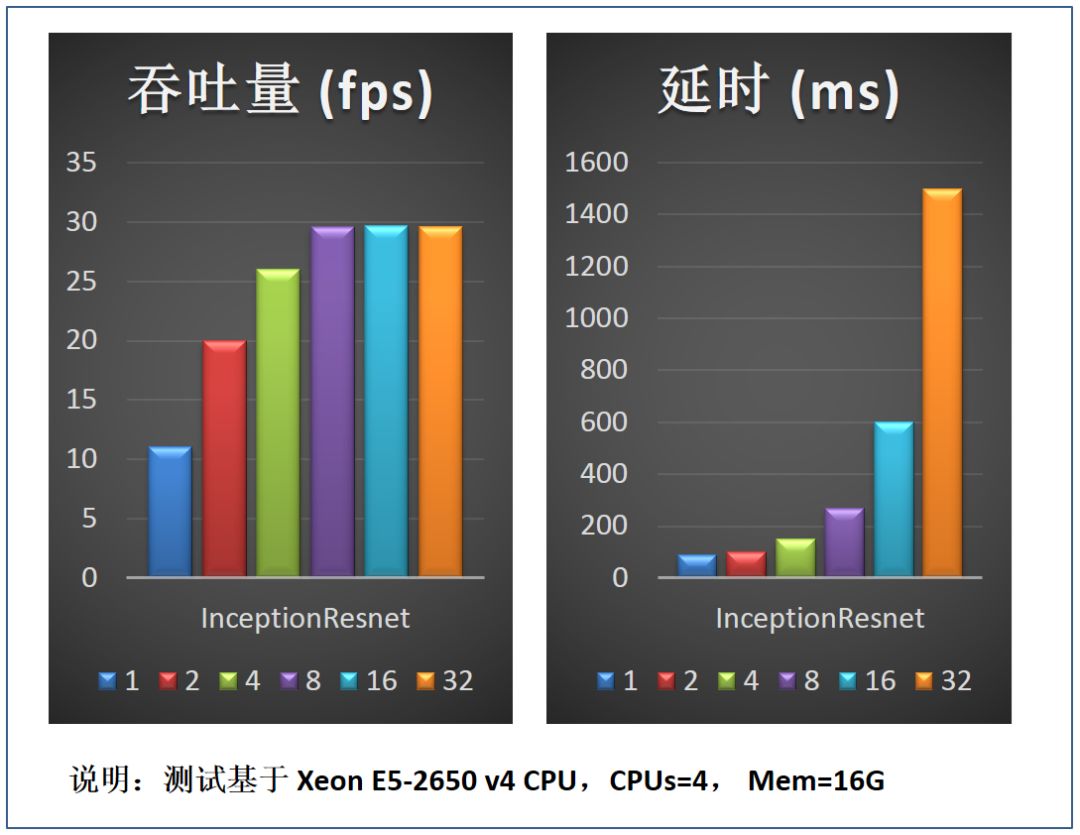
图 13 是选取不同的 batchsize 对推理服务吞吐量及延时的影响。测试结果可以看 batchsize 较小时适当增大 batchsize(例如 bs 从 1 到 2),对延时的影响较小,但是可以迅速提升吞吐量的性能;batchsize 较大时再增加其值(例如从 8 到 32),对服务吞吐量的提升已没有帮助,但是会极大影响服务延时性能。因此实践中需根据部署服务节点 CPU 核数及服务性能需求来优化选取 batchsize。
融合优化
在线模型inference时,每一层的运算操作都是由GPU完成,实际上是CPU通过启动不同的CUDA kernel来完成计算,CUDA kernel计算张量的速度非常快,但是往往大量的时间是浪费在CUDA kernel的启动和对每一层输入/输出张量的读写操作上,这造成了内存带宽的瓶颈和GPU资源的浪费。这里我们将主要介绍TensorRT部分自动优化以及手工优化两块工作。
1. 自动优化:TensorRT是一个高性能的深度学习inference优化器,可以为深度学习应用提供低延迟、高吞吐的推理部署。TensorRT可用于对超大规模模型、嵌入式平台或自动驾驶平台进行推理加速。TensorRT现已能支持TensorFlow、Caffe、MXNet、PyTorch等几乎所有的深度学习框架,将TensorRT和NVIDIA的GPU结合起来,能在几乎所有的框架中进行快速和高效的部署推理。而且有些优化不需要用户过多参与,比如部分Layer Fusion、Kernel Auto-Tuning等。
- Layer Fusion:TensorRT通过对层间的横向或纵向合并,使网络层的数量大大减少,简单说就是通过融合一些计算op或者去掉一些多余op,来减少数据流通次数、显存的频繁使用以及调度的开销。比如常见网络结构Convolution And ElementWise Operation融合、CBR融合等,下图是整个网络结构中的部分子图融合前后结构图,FusedNewOP在融合过程中可能会涉及多种Tactic,比如CudnnMLPFC、CudnnMLPMM、CudaMLP等,最终会根据时长选择一个最优的Tactic作为融合后的结构。通过融合操作,使得网络层数减少、数据通道变短;相同结构合并,使数据通道变宽;达到更加高效利用GPU资源的目的。
- Kernel Auto-Tuning:网络模型在inference时,是调用GPU的CUDA kernel进行计算。TensorRT可以针对不同的网络模型、显卡结构、SM数量、内核频率等进行CUDA kernel调整,选择不同的优化策略和计算方式,寻找适合当前的最优计算方式,以保证当前模型在特定平台上获得最优的性能。上图是优化主要思想,每一个op会有多种kernel优化策略(cuDNN、cuBLAS等),根据当前架构从所有优化策略中过滤低效kernel,同时选择最优kernel,最终形成新的Network。
2. 手工优化:众所周知,GPU适合计算密集型的算子,对于其他类型算子(轻量级计算算子,逻辑运算算子等)不太友好。使用GPU计算时,每次运算一般要经过几个流程:CPU在GPU上分配显存 -> CPU把数据发送给GPU -> CPU启动CUDA kernel -> CPU把数据取回 -> CPU释放GPU显存。为了减少调度、kernel launch以及访存等开销,需要进行网络融合。由于CTR大模型结构灵活多变,网络融合手段很难统一,只能具体问题具体分析。比如在垂直方向,Cast、Unsqueeze和Less融合,TensorRT内部Conv、BN和Relu融合;在水平方向,同维度的输入算子进行融合。为此,我们基于线上实际业务场景,使用NVIDIA相关性能分析工具(NVIDIA Nsight Systems、NVIDIA Nsight Compute等)进行具体问题的分析。把这些性能分析工具集成到线上inference环境中,获得inference过程中的GPU Profing文件。通过Profing文件,我们可以清晰的看到inference过程,我们发现整个inference中部分算子kernel launch bound现象严重,而且部分算子之间gap间隙较大,存在优化空间,如下图所示:
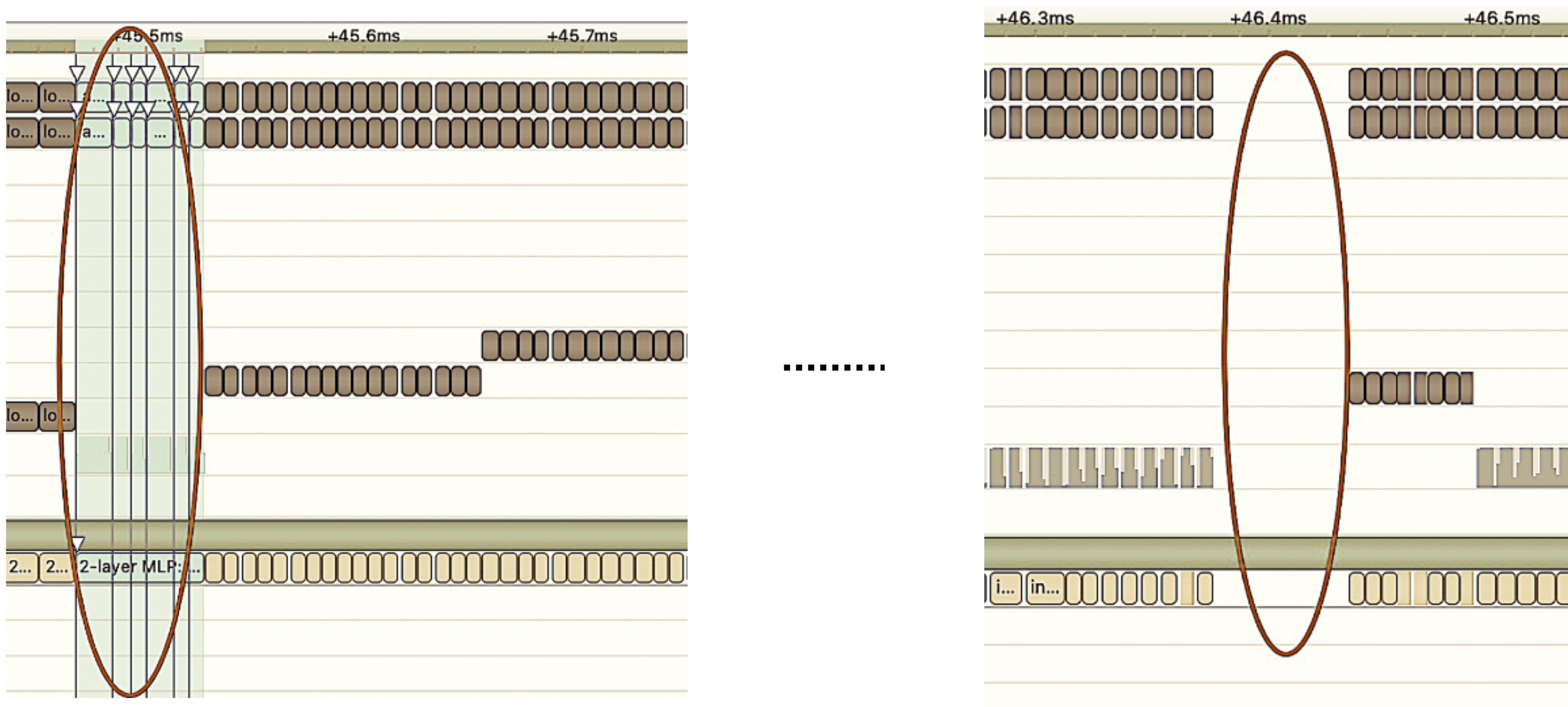
为此,基于性能分析工具和转换后的模型对整个Network分析,找出TensorRT已经优化的部分,然后对Network中其他可以优化的子结构进行网络融合,同时还要保证这样的子结构在整个Network占有一定的比例,保证融合后计算密度能够有一定程度的上升。至于采用什么样的网络融合手段,根据具体的场景进行灵活运用即可,如下图是我们融合前后的子结构图对比:

引擎优化
- 多模型:由于外卖广告中用户请求规模不确定,广告时多时少,为此加载多个模型,每个模型对应不同输入的Batch,将输入规模分桶归类划分,并将其padding到多个固定Batch,同时对应到相应的模型进行inference。
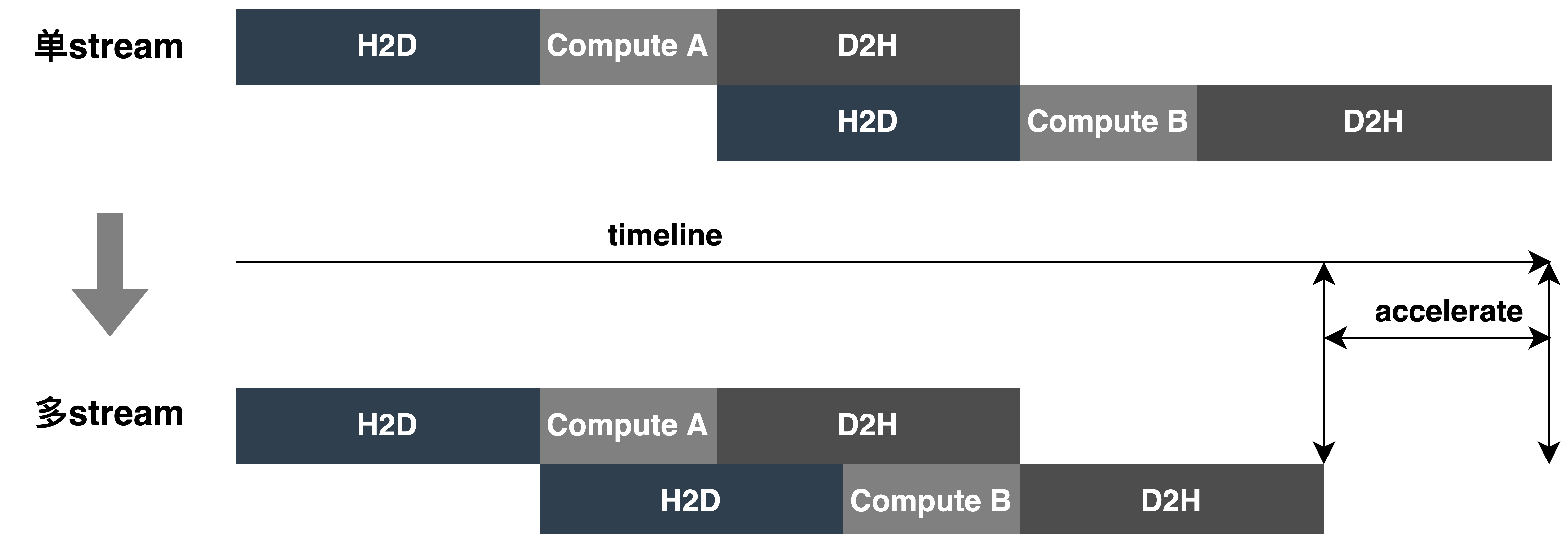
- Multi-contexts和Multi-streams:对每一个Batch的模型,使用多context和多stream,不仅可以避免模型等待同一context的开销,而且可以充分利用多stream的并发性,实现stream间的overlap,同时为了更好的解决资源竞争的问题,引入CAS。如下图所示,单stream变成多stream:
- Dynamic Shape:为了应对输入Batch不定场景下,不必要的数据padding,同时减少模型数量降低显存等资源的浪费,引入Dynamic Shape,模型根据实际输入数据进行inference,减少数据padding和不必要的计算资源浪费,最终达到性能优化和吞吐提升的目的。
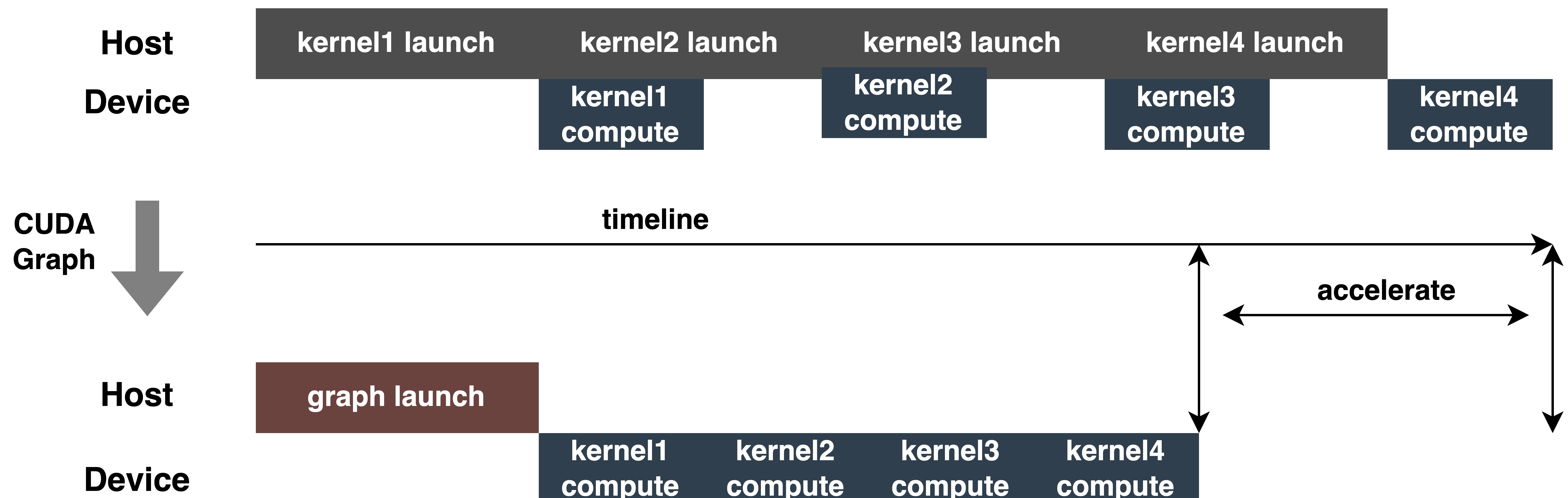
- CUDA Graph:现代GPU每个operation(kernel运行等)所花费的时间至少是微秒级别,而且,将每个operation提交给GPU也会产生一些开销(微秒级别)。实际inference时,经常需要执行大量的kernel operation,这些operation每一个都单独提交到GPU并独立计算,如果可以把所有提交启动的开销汇总到一起,应该会带来性能的整体提升。CUDA Graph可以完成这样的功能,它将整个计算流程定义为一个图而不是单个操作的列表,然后通过提供一种由单个CPU操作来启动图上的多个GPU操作的方法减少kernel提交启动的开销。CUDA Graph核心思想是减少kernel launch的次数,通过在推理前后capture graph,根据推理的需要进行update graph,后续推理时不再需要一次一次的kernel launch,只需要graph launch,最终达到减少kernel launch次数的目的。如下图所示,一次inference执行4次kernel相关操作,通过使用CUDA Graph可以清晰看到优化效果。
- 多级PS:为了进一步挖掘GPU加速引擎性能,对Embedding数据的查询操作可通过多级PS的方式进行:GPU显存Cache->CPU内存Cache->本地SSD/分布式KV。其中,热点数据可缓存在GPU显存中,并通过数据热点的迁移、晋升和淘汰等机制对缓存数据进行动态更新,充分挖掘GPU的并行算力和访存能力进行高效查询。经离线测试,GPU Cache查询性能相比CPU Cache提升10倍+;对于GPU Cache未命中数据,可通过访问CPU Cache进行查询,两级Cache可满足90%+的数据访问;对于长尾请求,则需要通过访问分布式KV进行数据获取。具体结构如下:

Pipeline
模型从离线训练到最终在线加载,整个流程繁琐易出错,而且模型在不同GPU卡、不同TensorRT和CUDA版本上无法通用,这给模型转换带来了更多出错的可能性。因此,为了提升模型迭代的整体效率,我们在Pipeline方面进行了相关能力建设,如下图所示:

Pipeline建设包括两部分:离线侧模型拆分转换流程,以及在线侧模型部署流程:
- 离线侧:只需提供模型拆分节点,平台会自动将原始TF模型拆分成Embedding子模型和计算图子模型,其中Embedding子模型通过分布式转换器进行分布式算子替换和Embedding导入工作;计算图子模型则根据选择的硬件环境(GPU型号、TensorRT版本、CUDA版本)进行TensorRT模型的转换和编译优化工作,最终将两个子模型的转换结果存储到S3中,用于后续的模型部署上线。整个流程都是平台自动完成,无需使用方感知执行细节。
- 在线测:只需选择模型部署硬件环境(与模型转换的环境保持一致),平台会根据环境配置,进行模型的自适应推送加载,一键完成模型的部署上线。
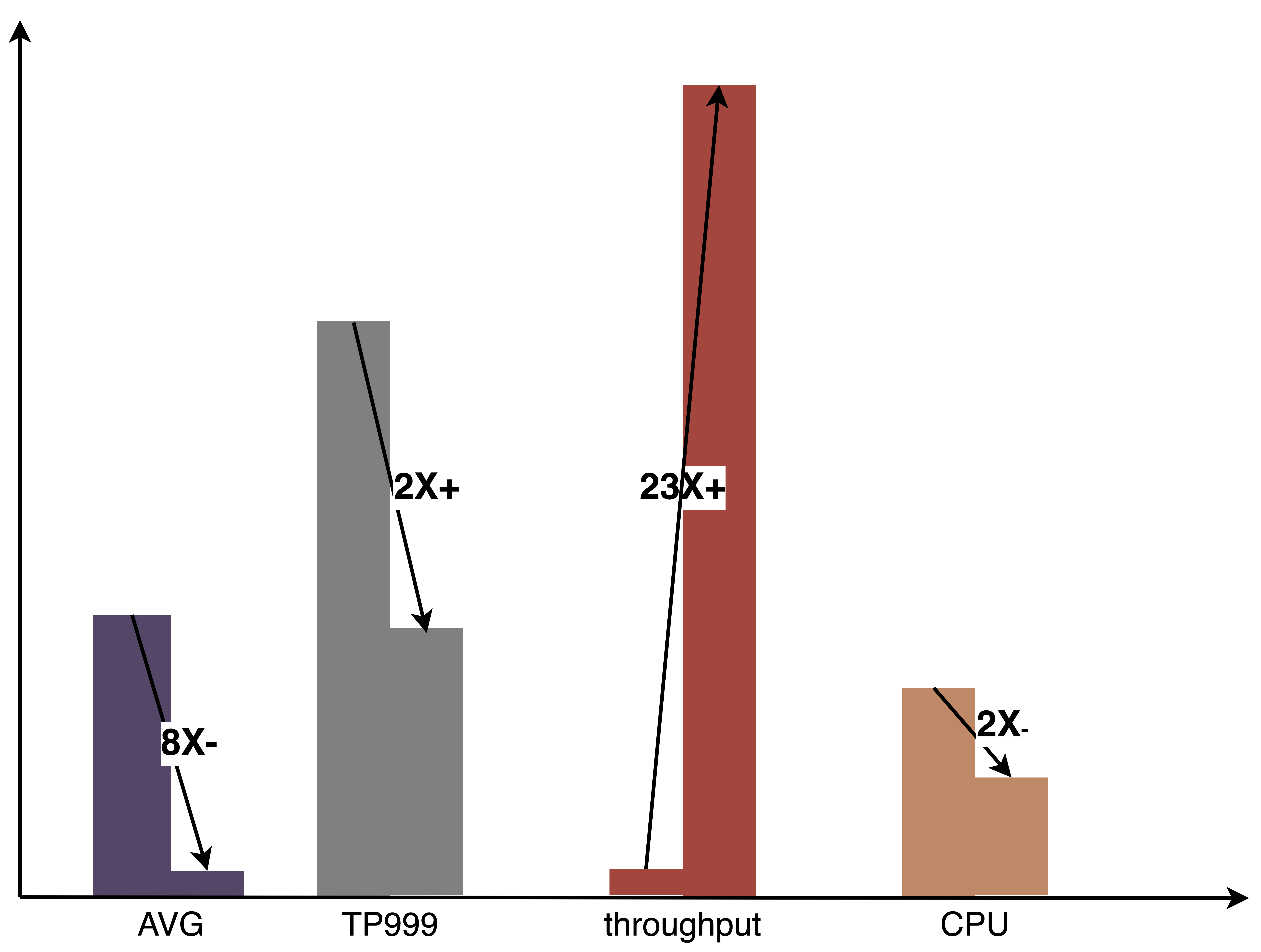
Pipeline通过配置化、一键化能力的建设,极大提升了模型迭代效率,帮助算法和工程同学能够更加专注的做好本职工作。下图是在GPU实践中相比纯CPU推理取得的整体收益:
参考
- 干货|基于CPU的深度学习推理部署优化实践_云计算_爱奇艺技术产品团队_InfoQ精选文章
- 外卖广告大规模深度学习模型工程实践 | 美团外卖广告工程实践专题连载 - 美团技术团队