目录
类型
String 字符串
List 列表
Set 集合
Sorted Set /ZSet 有序集合
Hash 哈希表
GEO 地理空间
HyperLogLog 基数统计
Bitmap 位图
BitField 位域
Stream 流
线上测试地址
常用命令
key 操作指令
String 操作指令
List 操作指令
Set 操作指令
ZSet 操作指令
Hash操作指令
GEO 操作指令
HyperLogLog 操作指令
Bitmap 操作指令
Bitfield 操作指令
Stream 操作指令(附示例)
这是Redis系列的第一篇( ̄∇ ̄)/,我们来介绍众说纷纭的Redis数据类型,本文会对 Redis 7.0 中10大数据类型的基本定义、使用场景、常用命令进行通俗易懂的介绍(就是额。。🤔说人话),看完会对Redis的数据类型方面有个全面的了解(应付个面试够够的),如果还想要更深入更全面的学习,我也都附上了官方文档的地址,可直达权威⁄(⁄ ⁄ ⁄ω⁄ ⁄ ⁄)⁄
正文开始┏ (^ω^)=
估计大家应该也都看过挺多相关的内容,但各个文章总有些小不同,首先强调下,本系列文章讨论的是 Redis 7.0,不同版本之间还是有有一些差异的,为确保准确,我们直接看官网
https://redis.io/docs/data-types/
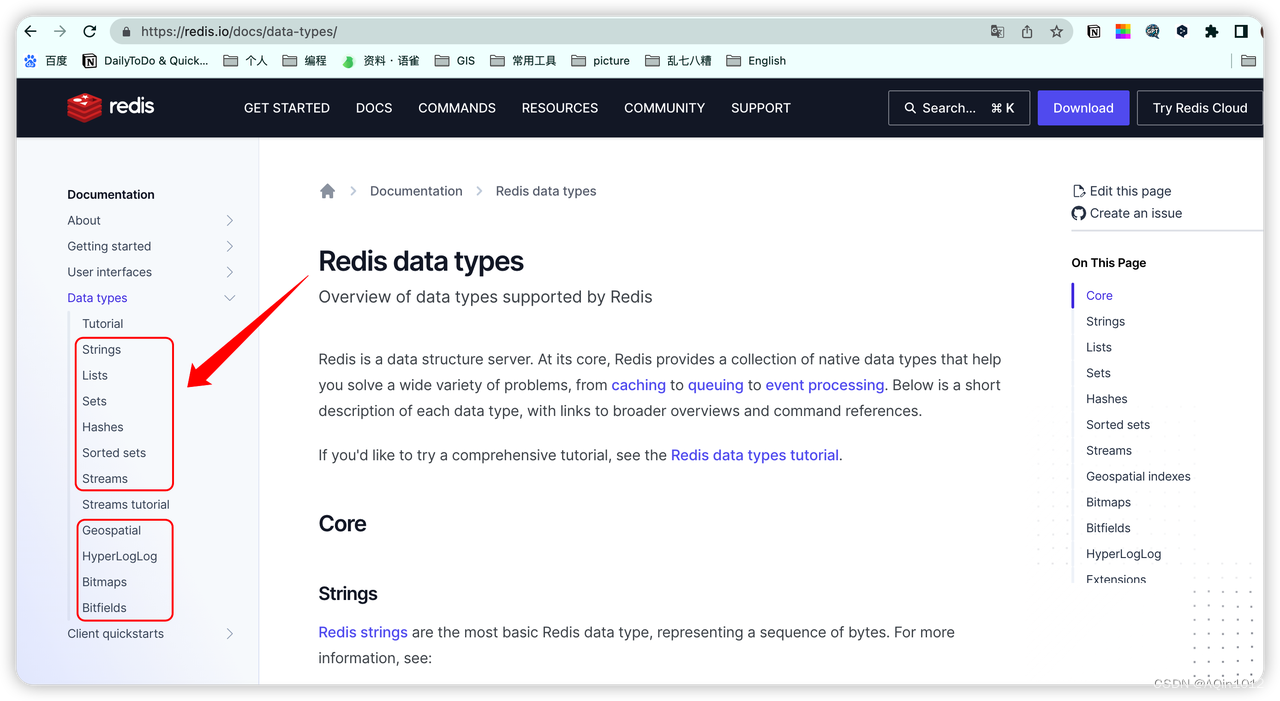
类型
这里的类型是Value,Key一般都是String
-
Strings
-
Lists
-
Sets
-
Sorted Sets (ZSet)
-
Hashes
-
Streams
-
Geospatial
-
HyperLogLog
-
Bitmaps
-
Bitfields
String 字符串
-
Redis中最基本的类型,一个Key可以对应一个Value
-
二进制安全的(可以包含任何数据,比如图片或者序列化的对象)
-
一个Redis中的字符串value最多可以是512M
List 列表
-
简单的字符串列表,按照被插入的顺序排序,你可以添加一个元素到列表的头部(左边)或者尾部(右边)
-
底层是个双端链表,最多可以包含2^32-1个元素(4294967295,超过40亿个元素)
-
对两端操作性能很高,通过索引下标操作中间节点性能会比较差
Set 集合
-
String类型的集合
-
不允许重复 + 无序
-
集合对象的编码可以是intset和hashtable(底层)
-
通过哈希表实现的,所以查询、删除、添加的时间复杂度都是O(1)
-
可以包含2^32-1个元素(4294967295,超过40亿个元素)
-
应用场景
-
微信抽奖小程序(sadd/spop/srandmember)
-
朋友圈的点赞
-
QQ可能认识的人
-
Sorted Set /ZSet 有序集合
-
与Set一样是String类型的集合
-
不同的是每个元素都会关联一个double类型的分数(给Redis从小到大排序用的)
-
value变成了一个键值对:score1 value1
-
key1 score1 value1 key2 score2 value2
-
-
ZSet的成员是唯一的,但分数(score)可以重复
-
通过哈希表实现的,所以查询、删除、添加的时间复杂度都是O(1)
-
可以包含2^32-1个元素(4294967295,超过40亿个元素)
-
应用场景
-
各种排行榜
-
Hash 哈希表
-
K-V 键值对
-
可以包含2^32-1个元素(4294967295,超过40亿个元素)
GEO 地理空间
-
原理(实际上是个ZSet,score变成了经纬度)
-
核心思想:将球体转换为平面,区块转换为一点
-
主要分为3步:
-
将三维地球变为二维坐标
-
将二维坐标转换为一维的点块
-
将一维的点块转换为二进制再通过base32编码
-
-
-
主要用于存储地理位置信息,并对存储的信息进行操作,包括
-
添加地理位置的坐标
-
获取地理位置的坐标
-
计算两个位置之间的距离
-
……
-
-
应用场景
-
美团地图位置附近的酒店
-
高德地图附近的核酸点
-
HyperLogLog 基数统计
-
用完做基数统计的算法
-
基数:是一种数据集,去重后的真实个数
-
基数统计:用于统计一个几乎中不重复的元素的个数,就是对集合去重后剩余元素的计算,即去重脱水后的真实数据
-
-
优点是在输入元素的数量或者体积特别大时,计算基数所需的空间总是固定且很小的
-
每个HyperLogLog键只需要12kb内存,就可以计算出接近2^64个不同的元素的基数
-
这和元素越多耗费内存越多的集合产生了鲜明的对比
-
-
但HyperLogLog并不会记录每个元素的具体值
-
可用于统计某个网站/文章的UV、用户搜索🔍关键词的数量、用户每天搜索不同词条的个数
-
UV unique visitor 独立访客(一般为用户IP)
-
Bitmap 位图
-
Bit arrays(or simply bitmaps)Bitmap是用String作为底层数据结构实现的一种统计二值状态的数据类型
-
一个字节占8位(1 byte = 8 bit)
-
由0和1组成的二进制位的bit数组(1 bit 只能存1个0/1)
-
一般用于状态记录📝
-
用户是否登陆过
-
电影广告是否被点击播放过
-
上下班打卡统计
-
BitField 位域
-
可以一次性操作多个比特位域(连续的多个比特位),它会执行一系列操作并返回一个响应数组,这个数组中的元素对应参数列表中的相应操作的执行结果(其实就是一次性对多个比特位进行操作)
Stream 流
-
Redis 5.0 新增的数据结构 : MQ消息中间件+阻塞队列
-
主要用于消息队列(MQ,Message Queue)
-
支持消息队列的持久化
-
支持自动生成全局唯一ID
-
支持ack确认消息的模式
-
支持消费组(多个消费者)模式等
-
-
Redis本身有一个发布/订阅来实现消息队列的功能,但他的缺点是消息无法持久化,如果出现网络断开、Redis宕机等,消息就会被丢弃
-
即发布/订阅可以分发消息,但无法记录历史消息
-
-
Redis的Stream提供了消息的持久化以及主从备份复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失,让消息队列更加稳定和可靠
线上测试地址
如果有不想在本地安装Redis的同学可以试试这个官方提供的测试网站
https://try.redis.io/
常用命令
需要注意的有两点
- 命令不区分大小写,但是key是区分大小写的
-
中括号('
[]')内的为可选参数
各个命令查询地址 https://redis.io/commands/
key 操作指令
| 指令 | 作用 | 备注 |
|---|---|---|
| key * | 查看当前库所有key | |
| exists key | 判断某个key是否存在 | |
| type key | 查看某个key的类型 | |
| del key | 删除指定的key | 原子的 |
| unlink key | 非阻塞删除(仅将key从keyspace元数据中移除) | |
| ttl key | 查看还有多少秒过期(-1表示永不过期,-2表示已过期) | |
| expire key 秒钟 | 为给定的key设置过期时间 | |
| move key dbindex | 将当前数据库的key移动到给定的数据库db中(dbindex的值为0-15) | 默认0 |
| dbsize | 查看当前数据库key的数量 | |
| flushdb | 清空当前库 | |
| flushall | 清空全部库 |
String 操作指令
| 指令 | 作用 | 可选项说明及备注 | |
|---|---|---|---|
| set key value [ | 设置/添加 |
| |
| 批处理 | mset key value [key value ...] | 同时设置多个值 | |
| mget key value [key value ...] | 同时获取多个值 | ||
| msetnx key value | key不存在才设置 | 所有的key都不存在才会设置成功 | |
| getrange key | 获取指定区域内的值 |
| |
| setrange key | 设置指定区域内的值 |
| |
| 数值增减 (必须是数字才行) | INCR key | 递增数字 | |
| INCRBY key | 增加减少指定的参数 |
| |
| DECR key | 递减数值 | ||
| DECRBY key | 减少指定的参数 | ||
| STRLEN key | 获取字符串长度 | ||
| APPENG key value | 内容追加 | ||
| 分布式锁 (原子操作) | setnx key value | key不存在才设置 | nx: set if not exsit |
| setex key | 同时设置值和过期时间 | ex: set with expire | |
| getset key value | 先get后set | 等价于 set key value get | |
List 操作指令
| 指令 | 作用 | 可选项说明及备注 |
|---|---|---|
| lpush key value | 从左边👈设置/添加 | |
| rpush key value | 从右边👉设置/添加 | |
| lrange key | 从左边👈开始遍历 |
|
| lpop | 弹出最左边的值 | |
| rpop | 弹出最右边的值 | |
| lindex | 按照索引下标获得元素(从上到下) | 左(上)右(下) |
| llen | 获取list中的元素个数 | |
| lrem key | 删除N值为value的元素 |
|
| ltrim key | 截取指定索引范围的值再赋值给key |
|
| rpoplpush key1 key2 | 从key1中弹出最右边的,加入到key2的最左端并返回 | |
| lset key | 将key中序号为 |
|
| linsert key before/after | 在key中值为 |
从上向向下👇第一个等于 |
Set 操作指令
| 指令 | 作用 | 可选项说明及备注 | |
|---|---|---|---|
| sadd key | 添加元素 | 自动去重 | |
| smembers key | 遍历所有元素 | ||
| sismember key | 判断元素是否在集合中 | ||
| srem key | 删除元素 | ||
| scard key | 获取集合里面的元素个数 | ||
| srandmember key [ | 从集合中随机展现 |
| |
| spop key [ | 从集合中随机弹出/删除 |
| |
| smove key1 key2 [ | 将key1中的某个值 |
| |
| 集合运算 | sdiff key [key...] | 差集运算 A - B | |
| sunion key [key...] | 并运算 A U B | ||
| sinter key [key...] | 交运算 A n B | ||
| sintercard numkeys key [key...] [limit | 只返回基数(去重统计数) |
| |
ZSet 操作指令
| 指令 | 作用 | 可选项说明及备注 |
|---|---|---|
| zadd key [ | 向有序集合添加一个元素和该元素的分数 | |
| zrange key | 按照元素分数从小到大的顺序,返回索引从start到stop之间的所有元素 |
|
| zrevrange key | zrange的反转(从大到小) |
|
| zrangebyscore key | 获取指定分数范围的元素 |
|
| zscore key member | 获取元素的分数 | |
| zcard key | 获取集合中元素的数量 | |
| zrem key | 删除值为指定分数的元素 |
|
| zincrby key | 增加某个元素的分数 |
|
| zcount key | 获取指定分数范围内的元素个数 |
|
| zmpop | 从键名列表中的第一个非空排序集中弹出一个或多个元素,他们是成员分数对 | |
| zrank key values | 获取下标值(从0开始) | |
| zrevrank key values | 逆序获取下标值 |
Hash操作指令
| 指令 | 作用 | 可选项说明及备注 | |
|---|---|---|---|
| hset key | 添加/设置 |
| |
| hget key field | 获取键为key的元素中的field属性的值 | ||
| 批处理 | hmset key | 批量添加/设置 | |
| hget key | 批量获取 | ||
| hgetall key | 获取键为key的元素中的全部属性 | ||
| hlen key | 获取某个key内的全部数量 | ||
| hexists key | 判断是否存在键值为key值(0不存在) | ||
| hkeys key | 获取键值为key值元素的所有字段名( | ||
| hvals key | 获取键值为key值元素的所有字段值( | ||
| hincrby/hincrbyfloat key | 给键值为key值元素中 |
| |
| hsetnx key | 不存在才会新建成功 | ||
GEO 操作指令
| 指令 | 作用 | 可选项说明及备注 |
|---|---|---|
| geoadd key | 添加经纬度坐标 | 出现中文乱码,redis-cli启动时加个 |
| geopos | 从键里面返回所有给定元素的位置(经纬度) | |
| geodist key | 返回给定位置之间的距离 geodist不仅可以计算两个 member 之间的距离,还可以计算一个 member 与 key 中多个 member 之间的距离 【示例】
|
|
| georadius key | 以给定经纬度为中心,返回与中心距离离不超过给定最大距离的所有元素,且可以根据需求返回经纬度、距离等详细信息,并将查询结果保存到一个新的有序集合中。 |
|
| georadiusbymember key member | georadiusbymember各个参数的含义和作用与georadius命令的相应参数完全相同,唯一的不同是 georadiusbymember 使用的查询中心是指定的成员,而不是经纬度坐标。 | |
| geohash | 返回坐标的geohash表示 | geohash算法生成的base32编码值 |
HyperLogLog 操作指令
| 指令 | 作用 | 可选项说明及备注 |
|---|---|---|
| pfadd key | 添加指定的元素 | |
| pfcount key [key ...] | 返回给定的基数估计值 | |
| pfmerge | 合并统计 |
Bitmap 操作指令
| 指令 | 作用 | 可选项说明及备注 | 时间复杂度 |
|---|---|---|---|
| setbit key | 为键为key的元素序号为 |
| O(1) |
| getbit key | 获取指定key的第 | O(1) | |
| strlen key | 统计字节数占用多少(按字节) | O(1) | |
| bitcount key | 返回指定范围[ |
| O(n) |
| bitop | 对不同的二进制存储数据进行位运算(AND、OR、NOT、XOR) |
| O(n) |
Bitfield 操作指令
实际生产中几乎……%不怎么用,这里就不列举叻,还是想了解可查看官网
https://redis.io/commands/bitfield/
Stream 操作指令(附示例)
特殊符号:
-
-+最小和最大可能出现的ID -
$表示读新到来的,即随着新消息的到来,$ 的指针会自动向前移动 -
>表示从第一条尚未被消费的数据开始读起 -
*添加消息的ID自增
| 指令 | 作用 | 可选项说明及备注 | |
|---|---|---|---|
| 队列相关 | xadd key [ | 添加消息到队列末尾,返回消息
|
|
| xrange key | 用于获取消息列表(可以指定范围),从最旧的开始 【示例】
|
| |
| xrevrange key | 用于查询 Redis Stream 中的消息,从最新的开始( xread、xrange 命令的默认查询起始点是最旧的消息) 【示例】
|
| |
| xdel key | 删除一个或多个消息(需要注意的是 xdel 的操作一旦删除了消息就无法恢复) |
| |
| xlen key | 返回 Redis Stream 中的消息数量 | 无论有多少数据,时间复杂度都是 O(1) | |
| xtrim key | 将 Redis Stream 中的消息按照指定的条件进行裁剪y(同xdel一样,删除了无法恢复) 【示例】
|
| |
| xread [ | 从Redis Stream 中读取数据 【示例】
|
| |
| 消费者相关 (同一个消费组中的不同消费者不能消费同一个消息,但不同消费组的消费者可以,可以进行负载均衡) | xgroup create key | 用于在 Redis Stream 中创建一个新的消费者组,并将指定消费者加入该组 【示例】
|
|
| xreadgroup group | 用于从 Redis Stream 中读取数据,并且将其发送给指定的消费者组 【示例】
|
| |
| xpending key | 于从消费者组中获取关于 Stream 的消费状态信息,包括等待下一个确认的消息、还未分配给消费者的消息和已经被消费者处理但还未确认的消息 【示例】
|
| |
| xack key | 用于向 Redis Stream 数据结构中添加消费者对消息的确认,即表示此消息已经被成功消费和处理 【示例】
|
| |
| xinfo [ | 用于打印Stream/Consumer/Group的详细信息,便于监控和调试 【示例】
|
| |
搞定~撒个花(。・ω・。)ノ🎉🎉🎉